
我的场景是这样,比如我有两个派生指标都是基于一个原子指标,第一个派生指标统计粒度是 a b c 第二个统计粒度是d和e 我现在需要基于a b c d e五个粒度看这个,写sql没问题,但是dataphin怎么规范处理呢?有什么建议吗
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,我理解这个场景统计粒度直接配置5个就可以看到基于这5个粒度的group by 了吧。如下图,看看是否满足预期呢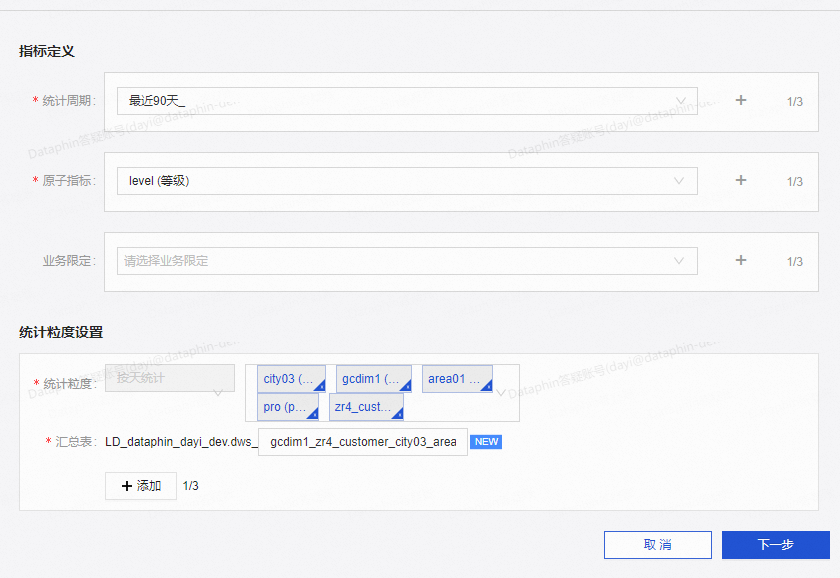
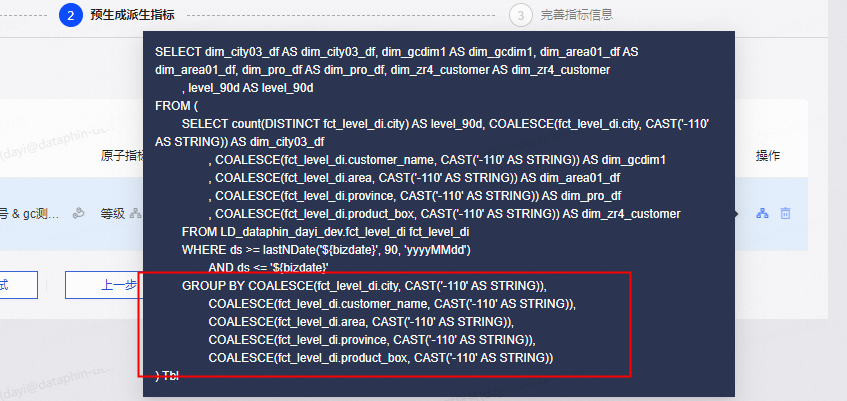 ,此回答整理自钉群“Dataphin公共云答疑群”
,此回答整理自钉群“Dataphin公共云答疑群”

