
SQL Server Writer参数说明是是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云DataWorks中,SQL Server Writer是一种用于将数据写入SQL Server数据库的组件。 SQL Server Writer的参数说明如下:
JDBC URL:SQL Server数据库的JDBC连接URL,例如 jdbc:sqlserver://hostname:port;databaseName=dbname。
用户名/密码:连接SQL Server数据库的用户名和密码。
表名:要将数据写入的表名。
字段列表:指定将要插入的字段列表,格式为 column1, column2, column3, ...。也可以使用*表示插入所有字段。
每次提交的记录数:每次向数据库提交数据的记录条数。
预SQL:执行插入数据之前要先执行的SQL语句,例如 SET IDENTITY_INSERT table_name ON。
后SQL:执行插入数据之后要执行的SQL语句,例如 SET IDENTITY_INSERT table_name OFF。
超时时间(秒):写入数据库操作的超时时间,单位为秒。
重试次数:在写入数据时出现错误时,最大的重试次数。
DataWorks关于数据源的支持,可以参考文档 配置数据源查询DataWorks支持的数据源,包括SQL Server; 关于SQL Server相关数据源的配置操作可以参考文档 配置SQL Server数据源 在配置SQL Server数据源,关于如何配置SQLServer插件,可以参考文档SQLServer Reader和SQLServer Writer。 其中在SQL Server Writer的插件说明文档中有关于SQL Server Writer的参数说明 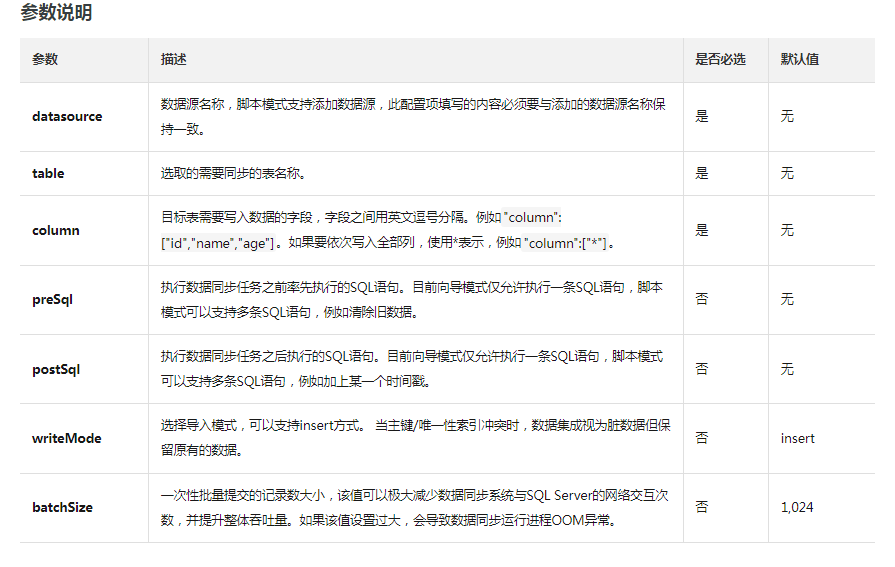
"参数 描述 是否必选 默认值 datasource 数据源名称,脚本模式支持添加数据源,此配置项填写的内容必须要与添加的数据源名称保持一致。 是 无 table 选取的需要同步的表名称。 是 无 column 目标表需要写入数据的字段,字段之间用英文逗号分隔。例如""column"":[""id"",""name"",""age""]。如果要依次写入全部列,使用表示,例如""column"":[""""]。 是 无 preSql 执行数据同步任务之前率先执行的SQL语句。目前向导模式仅允许执行一条SQL语句,脚本模式可以支持多条SQL语句,例如清除旧数据。 否 无 postSql 执行数据同步任务之后执行的SQL语句。目前向导模式仅允许执行一条SQL语句,脚本模式可以支持多条SQL语句,例如加上某一个时间戳。 否 无 writeMode 选择导入模式,可以支持insert方式。 当主键/唯一性索引冲突时,数据集成视为脏数据但保留原有的数据。 否 insert batchSize 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与SQL Server的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程OOM异常。 否 1,024 https://help.aliyun.com/document_detail/137769.html 此回答整理自钉群“DataWorks交流群(答疑@机器人)”"
SQL Server Writer是一种数据写入组件,用于将数据写入SQL Server数据库中。SQL Server Writer的参数说明如下:
你好,有关SQL Server Writer插件的相关参数: 
请参考:https://help.aliyun.com/document_detail/137769.html?spm=a2c4g.146663.0.i4
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



