
flink k8s application的jobmanager反亲和,clusterid怎么动态取值啊,有懂的么?${kubernetes.cluster-id},我这么取值不行。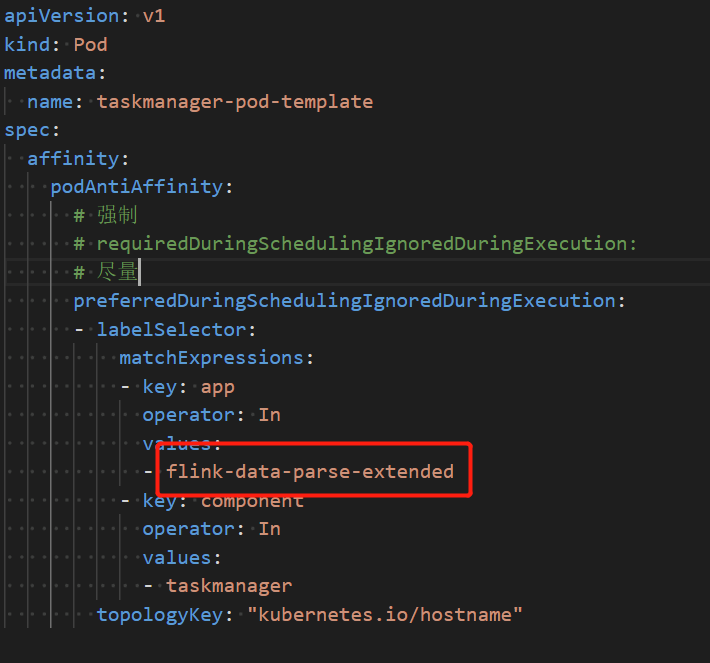 这个地方我不想写死,想做成通用的。
这个地方我不想写死,想做成通用的。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink 的 Kubernetes 模式下,可以通过设置 JobManager 的反亲和性来避免 JobManager 和 TaskManager 调度到同一个节点上,提高作业的稳定性和可靠性。
在 Flink 1.12.0 版本及以上的版本中,可以通过在 flink-conf.yaml 文件中设置 cluster.id 参数来动态设置 JobManager 的反亲和性。具体来说,可以在 flink-conf.yaml 文件中添加以下配置:
high-availability:
cluster-id: ${FLINK_CLUSTER_ID}
然后,在启动 Flink Kubernetes Application 时,可以通过设置环境变量 FLINK_CLUSTER_ID 来动态设置 cluster.id 参数的值。例如,可以使用以下命令来启动 Flink Kubernetes Application:
$ kubectl create namespace flink
$ kubectl create secret generic flink-config-secret \
--from-file=flink-conf.yaml=./flink-conf.yaml \
--namespace=flink
$ kubectl apply -f flink-configuration-configmap.yaml \
--namespace=flink
$ kubectl apply -f jobmanager-service.yaml \
--namespace=flink
$ kubectl apply -f taskmanager-statefulset.yaml \
--namespace=flink \
--env="FLINK_CLUSTER_ID=my-cluster-id"
这里通过设置 FLINK_CLUSTER_ID 环境变量来动态设置 cluster.id 参数的值。可以根据实际情况来设置不同的 FLINK_CLUSTER_ID 值,以避免 JobManager 和 TaskManager 调度到同一个节点上。
FLINK_CLUSTER_ID 环境变量必须在启动 TaskManager 前设置,否则无法生效。另外,需要确保 flink-conf.yaml 文件中的 cluster.id 参数和 FLINK_CLUSTER_ID 环境变量的值保持一致。
yaml不识别变量赋值。在部署脚本里面加个处理逻辑,每次部署前把指定的app name替换掉就好了。此回答整理自钉群“【③群】Apache Flink China社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



