
-
 随心分享,欢迎友善交流讨论:)
随心分享,欢迎友善交流讨论:)Kafka 消费者的参数配置对消费能力的提高有很大影响。以下是一些常用的参数和建议的配置方式:
fetch.max.bytes: 每个拉取请求的最大字节数,默认是50MB。如果网络带宽充足,可以将该参数设置为更大的值,可以提高每个拉取请求拉取的数据量,减少网络往返次数,从而提高消费能力。
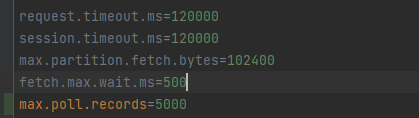
max.poll.records: 每次拉取的最大记录数,默认是500 条。如果消息较小,可以适当提高该参数,以减少拉取次数,从而提高消费能力。
max.poll.interval.ms: 每次拉取的最大时间间隔,默认是5 分钟。如果需要更快地响应消息,可以适当缩短该参数,但是要注意避免频繁拉取导致过多的网络请求。
enable.auto.commit: 是否开启自动提交 offset,默认是开启的。如果关闭自动提交,可以通过手动提交 offset 来控制消费速度,提高消费能力。
isolation.level: 隔离级别,可以设置为 read_committed 或 read_uncommitted。使用 read_uncommitted 可以提高消费速度,但是可能会出现脏读的情况。
enable.partition.eof: 是否在分区末尾添加一个“结束标志”,默认是关闭的。如果开启,可以避免在消费到分区末尾时不断轮询,从而提高消费能力。
max.partition.fetch.bytes: 每个分区拉取的最大字节数,默认是1MB。如果消息较大,可以适当提高该参数,以减少拉取次数,从而提高消费能力。
通过合理配置这些参数,可以提高 Kafka 消费者的消费能力,但是需要根据实际情况进行调整。
2023-03-16 14:52:20赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



