
flink on yarn per-job的模式, hadoop_classpath 没有将 hadoop/share/hadoop/mapreduce 下来的依赖项打上。
flink cluster模式,是有的,这个问题有人知道吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你可以改写启动脚本 然后启动的时候把你需要的Jar地址都加入环境变量
类似这样,想加啥加啥
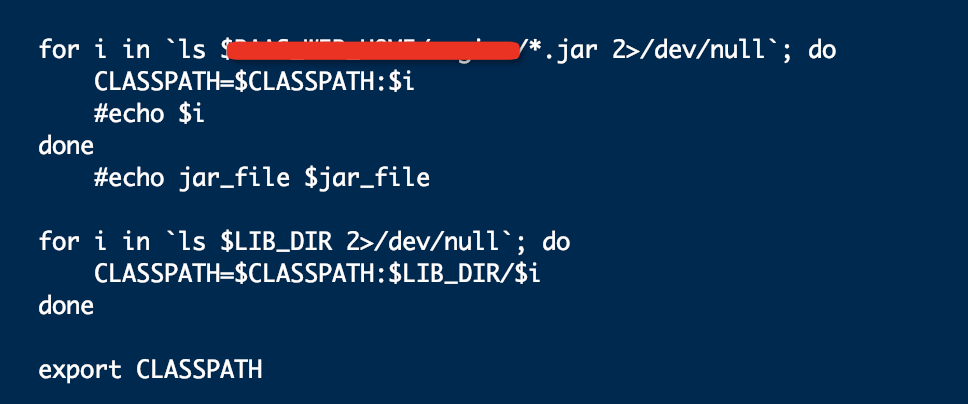
此答案来自钉钉群“【2】Apache Flink China 社区"
这个错误可能是由于在 flink on yarn per-job 模式下,hadoop_classpath 环境变量没有正确地配置导致的。
hadoop_classpath 环境变量用于指定 Hadoop 的依赖项,其中包含了 Hadoop MapReduce 依赖的 jar 包和其他资源文件。在 flink on yarn per-job 模式下,hadoop_classpath 必须正确地配置,才能保证 Flink 程序能够正确地运行。
具体来说,你可以在 flink-conf.yaml 文件中,找到 hadoop_classpath 配置项,并将 hadoop/share/hadoop/mapreduce 下的依赖项添加到 hadoop_classpath 中。例如:
hadoop_classpath: "/path/to/hadoop-mapreduce/*"
在这里,"/path/to/hadoop-mapreduce/*" 表示 hadoop-mapreduce 目录下的所有文件。你可以根据你的实际情况来修改这个路径,以便正确地配置 hadoop_classpath 环境变量。
如果上述步骤还是无法解决问题,你可以尝试检查日志文件,以便找出更多的信息,并基于这些信息来进一步调试程序。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



