
消息队列Kafka版的日志聚合功能是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
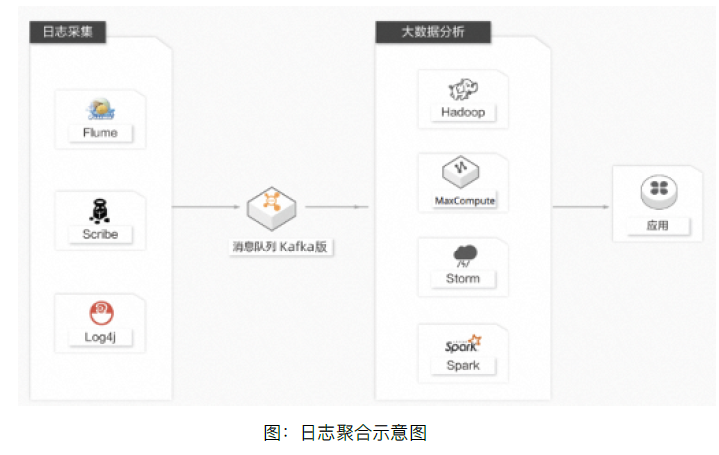
许多公司,例如淘宝、天猫等,每天都会产生大量的日志(一般为流式数据,例如搜索引擎PV、查询等)。相较于以日志为中心的系统,例如Scribe和Flume,消息队列Kafka版在具备高性能的同时,可以实现更强的数据持久化以及更短的端到端响应时间。这种特性决定它适合作为日志收集中心。消息队列Kafka版忽略掉文件的细节,可以将多台主机或应用的日志数据抽象成一个个日志或事件的消息流,异步发送到消息队列Kafka版集群,从而实现非常低的RT。消息队列Kafka版客户端可批量提交消息和压缩消息,对生产者而言几乎感觉不到性能的开支。消费者可以使用Hadoop、MaxCompute等离线仓库存储和Strom、Spark等实时在线分析系统对日志进行统计分析。
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版
涵盖 RocketMQ、Kafka、RabbitMQ、MQTT、轻量消息队列(原MNS) 的消息队列产品体系,全系列产品 Serverless 化。RocketMQ 中文社区:https://rocketmq-learning.com/



