
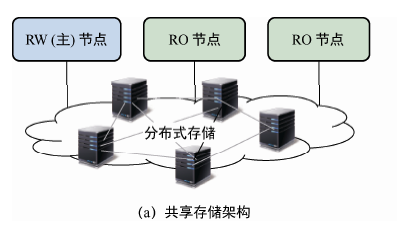
如图,为什么用主节点(Read-Write,RW)和只读节点(Read-Only,RO)将计算节点区分开?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这是因为:尽管存储方面进行了分布式改造,但是计算层(包括事务管理、查询处理等模块)还保留着单机数据库的结构,并发事务处理能力(写入吞吐量)受到单个节点的性能上限制约。共享存储架构为计算和存储两层分别弹性伸缩带来了可能,但是受限于单机写入性能的上限,该架构下的计算实例并不能算真正意义上的扩展,因为系统只能添加只读节点来分担读压力,共享存储架构存在眀显的性能瓶颈。尽管共享存储的垂直扩展能力受到业界的青睐,但是在工程实现中,整个集群的存储上限通常在几十TB 至几百TB。
以上内容摘自《云原生数据库原理与实践》,这本书可以在电子工业出版社天猫店购买。


