
基于密度的异常检测算法中需要计算的变量有哪些呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
基于密度的异常检测算法中需要计算的变量比较多第一个是数据对象o的K距离,把它称之为 也就是数据对象o到他的第K个最近邻邻居的距离。
也就是数据对象o到他的第K个最近邻邻居的距离。
第二个变量是数据对象o的K距离领域。对象o的K距离领域指的是离这个数据对象的距离小于等于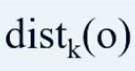 所有数据对象的集合:
所有数据对象的集合: 。注意:对象o的K距离领域的数目可能会大于K,因为在对象o的
。注意:对象o的K距离领域的数目可能会大于K,因为在对象o的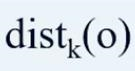 领域范围内,可能会有一些数据对象到o的距离是相等的。
领域范围内,可能会有一些数据对象到o的距离是相等的。
第三个需要计算的变量称之为从对象o‘到o的可达距离。从对象o’到o的可达距离指的是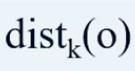 和distance之间的最大值
和distance之间的最大值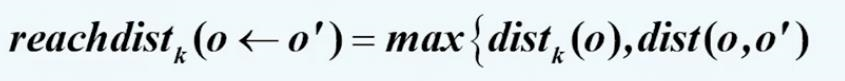 。
。

