
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
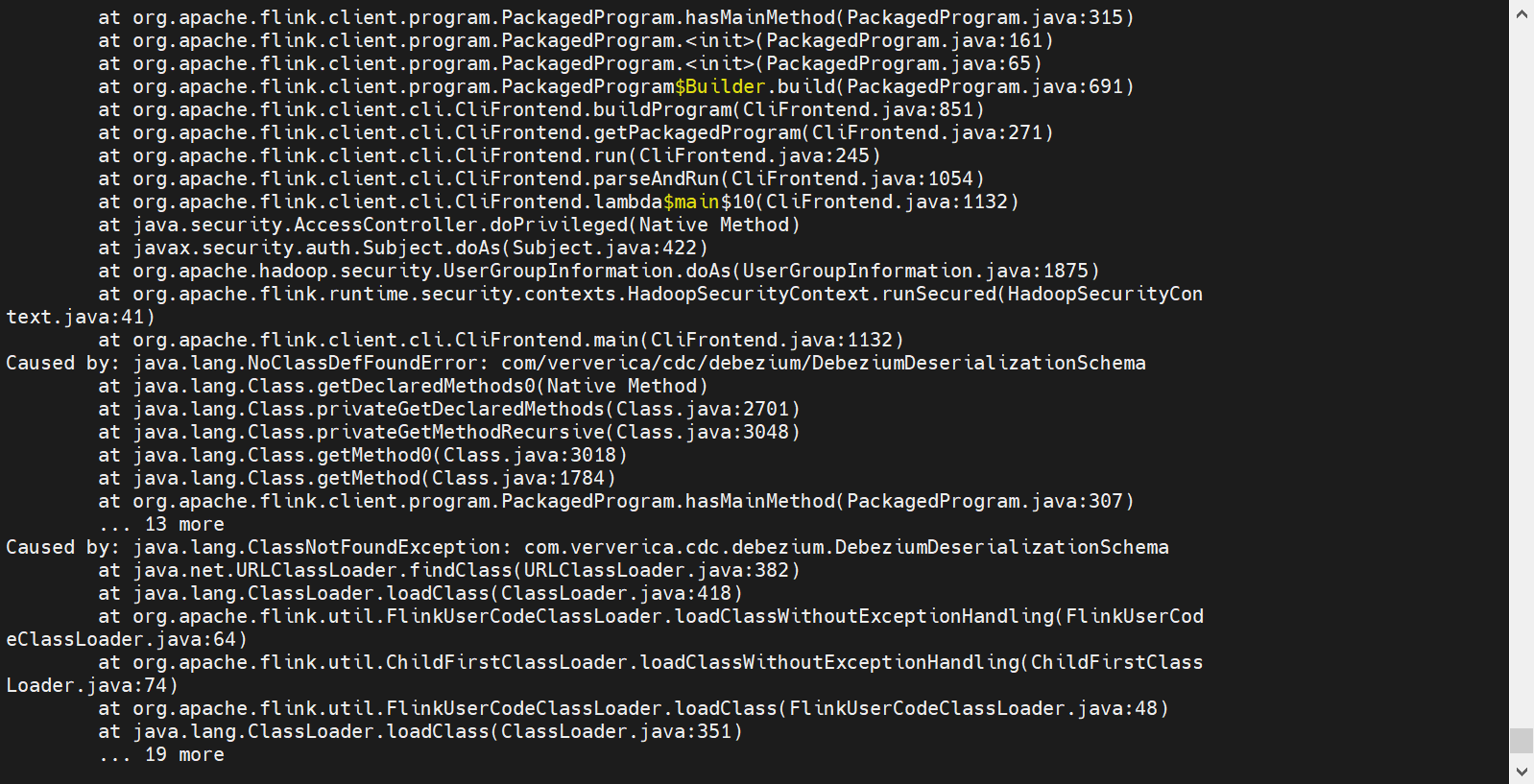
是的,如果您使用的是DataStream API,并且需要找不到类,可能需要引用debezium包。
Debezium是一个开源项目,提供了一组用于连接和抽取数据的API,包括连接器、转换器和增强器等。如果您需要在DataStream API中使用Debezium连接器或转换器,需要先在项目中引用相应的依赖。
具体来说,您可以在Maven项目中添加以下依赖:
Copy code
io.debezium
debezium-core
1.6.0.Final
或者在Gradle项目中添加以下依赖:
Copy code
implementation 'io.debezium:debezium-core:1.6.0.Final'
引用了Debezium依赖后,您就可以在DataStream API中使用Debezium连接器和转换器了。例如,以下代码片段演示了如何使用Debezium连接MySQL数据库:
Copy code
Configuration config = Configuration.create()
.with("connector.class", "io.debezium.connector.mysql.MySqlConnector")
.with("database.hostname", "localhost")
.with("database.port", "3306")
.with("database.user", "user")
.with("database.password", "password")
.with("database.server.name", "my-app-connector")
.build();
DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine.create(Json.class)
.using(config)
.notifying(record -> {
// process the captured change event
})
.build();
engine.run(...);
希望这可以帮助您解决问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



