
从前在使用 Hadoop 和 Spark 等分布式处理系统时,用户通常需要经历的步骤有哪些?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从前在使用 Hadoop 和 Spark 等分布式处理系统时,用户通常需要经历的步骤如图 2-10 所示。其中,真正与用户应用逻辑相关的是步骤 8 ~ 10,而步骤 1 ~ 7 都是前期准备,但这些前期准备工作都非常烦琐。 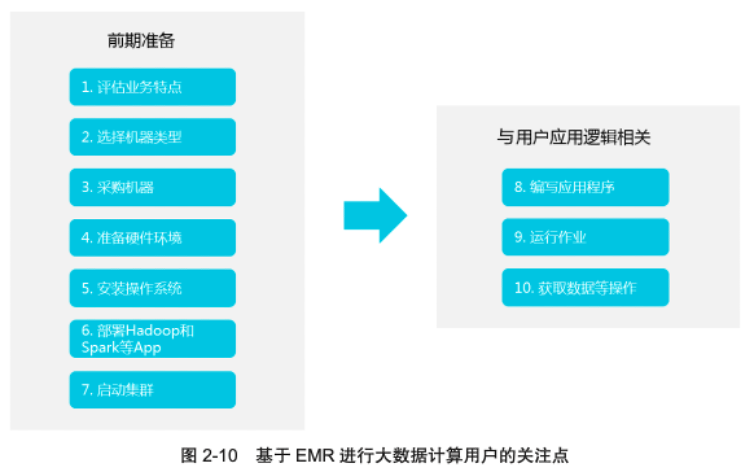
《弹性计算:无处不在的算力》电子书可以通过以下链接下载:https://developer.aliyun.com/topic/download?id=7996"
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
