
RDS MySQL如何使用Percona Toolkit?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
pt-online-schema-change
pt-online-schema-change提供在线修改表结构等功能,搭配RDS MySQL 5.5使用可以避免在修改表结构的过程中阻塞应用对表数据的访问。由于RDS MySQL 5.6支持online-ddl功能,可以直接在业务低峰期进行操作,也可以结合pt-online-schema-change使用。
无论RDS MySQL 5.5还是5.6版本,是否使用pt-online-schema-change,在修改表结构过程中都有可能遇到等待表元数据锁的情况(waiting for table metadata lock)。如果出现这种情况,请参考RDS MySQL表上Metadata lock的产生和处理。
表及数据维护操作请在业务低峰期进行。
样例用表
CREATE TABLE `x` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`password` varchar(10) DEFAULT NULL,
`recommend_level` double(5,0) DEFAULT NULL,
`name` varchar(30) DEFAULT '101' COMMENT 'change',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;
增加字段
1、登录服务器,执行如下命令,增加字段。
pt-online-schema-change --no-version-check --execute --alter "add column c1 int" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
注:
h=xxx.mysql.rds.aliyuncs.com:RDS实例地址。
P=3306:RDS实例端口。
u=jacky:RDS实例用户。
p=xxx:RDS实例用户密码。
D=jacky:RDS实例数据库。
t=x:RDS实例表名称。
系统显示类似如下。
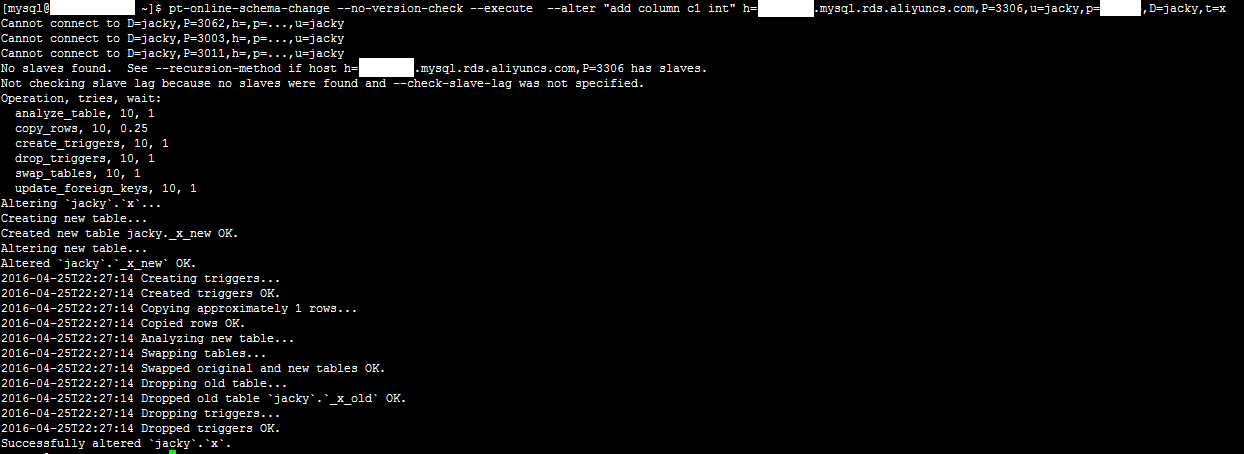
2、登录数据库,执行如下SQL语句,确认添加成功。
show create table x \G
系统显示类似如下。
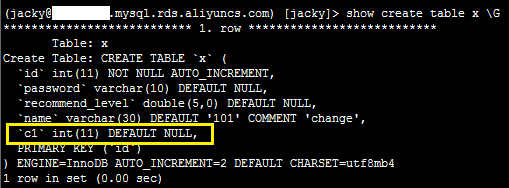
删除字段
1、登录服务器,执行如下命令,删除字段。
pt-online-schema-change --no-version-check --execute --alter "drop column c1" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认删除字段成功。
show create table x \G
系统显示类似如下。
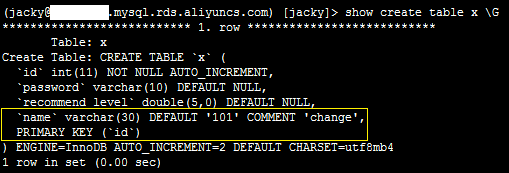
修改字段类型
1、登录服务器,执行如下命令,修改字段类型。
pt-online-schema-change --no-version-check --execute --alter "modify column c1 bigint unsigned" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
2、登录数据库,执行如下SQL语句,确认修改字段类型成功。
show create table x \G
系统显示类似如下。
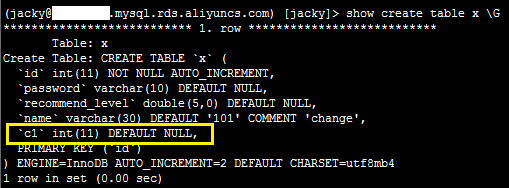
添加索引
1、登录服务器,执行如下命令,添加索引。
pt-online-schema-change --no-version-check --execute --alter "add key idx_c1 (c1)" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
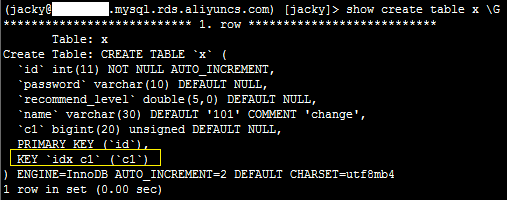
2、登录数据库,执行如下SQL语句,确认添加索引成功。
show create table x \G
系统显示类似如下。
删除索引
1、登录服务器,执行如下命令,删除索引。
pt-online-schema-change --no-version-check --execute --alter "drop key idx_c1" h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=x
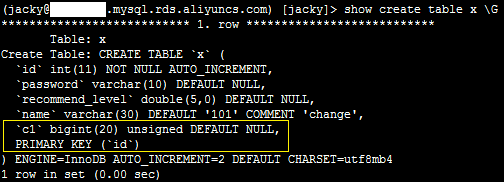
2、登录数据库,执行如下SQL语句,确认删除索引成功。
show create table x \G
系统显示类似如下。
pt-archiver
pt-archiver是Percona官方提供的归档工具,用于归档大型表中的记录到另一个表或文件。
样例用表
CREATE TABLE `my_tab` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`areaID` varchar(50) DEFAULT NULL,
`area` varchar(60) DEFAULT NULL COMMENT '中文注释测试',
`father` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_area` (`area`)
) ENGINE=InnoDB AUTO_INCREMENT=3162 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT KEY_BLOCK_SIZE=8;
归档到操作系统文件
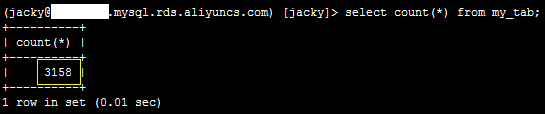
1、登录数据库,执行如下SQL语句,确认源表数据的行数。
select count(*) from my_tab;
系统显示类似如下。
2、登录服务器,执行如下命令,归档到操作系统文件。
pt-archiver --source h=xxx.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --file '/var/tmp/%Y-%m-%d-%D.%t' --where "id > 3008" --limit 1000 --commit-each --no-version-check
注:
h=xxx.mysql.rds.aliyuncs.com:RDS实例地址。
P=3306:RDS实例端口。
u=jacky:RDS实例用户。
p=xxx:RDS实例用户密码。
D=jacky:RDS实例数据库。
t=my_tab:RDS实例表名称。
--source:指定要被归档的数据源。
--charset=utf8:使用的字符集,需与表字符集一致,否则指定--no-check-charset参数。
--file:指定目标操作系统文件名。
--where "id > 3008":指定where过滤条件,过滤出要归档的数据。
--limit 1000:每条语句读取和归档的数据行数,默认是1。
--commit-each:每次获取和归档数据后,commit提交。
--no-version-check:不做版本检查,RDS MySQL必须设置。
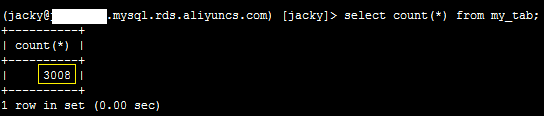
3、归档后,登录数据库,执行如下SQL语句,确认数据行数减少150行。
select count(*) from my_tab;
系统显示类似如下。
4、登录服务器,执行如下命令,发现归档操作系统文件中,包含150行数据。
wc -l /var/tmp/xxx-jacky.my_tab
系统显示类似如下。

归档到另外一个表中
可以将数据归档到同实例不同库下的表中,也可以将数据归档到不同实例下的表中。归档操作前,目标表要存在。
归档到同实例不同库下的表
1、登录服务器,执行如下命令,归档到同实例不同库下的表。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --dest h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=my_db,t=my_tab --where "id > 2000" --limit 1000 --commit-each --no-version-check
注:--dest为指定归档到的目标表。
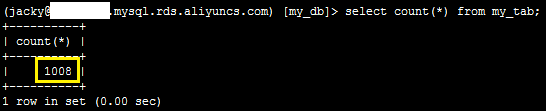
2、登录数据库,执行如下SQL语句,发现目标表中增加了1008行数据。
select count(*) from my_tab;
系统显示类似如下。
3、登录数据库,执行如下SQL语句,源表中减少了1008行数据,剩余2000行数据。
select count(*) from jacky.my_tab;
系统显示类似如下。

归档到不同实例下的表
1、登录服务器,执行如下命令,归档到不同实例下的表。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --charset=utf8 --dest h=rds02.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=my_tab --where "id > 500" --limit 1000 --commit-each --no-version-check
2、登录数据库,执行如下SQL语句,发现目标表中增加了1500行数据。
select count(*) from my_tab;
系统显示类似如下。

3、执行如下SQL语句,源表中减少了1500行数据,剩余500行数据。
select count(*) from jacky.my_tab;
系统显示类似如下。

通过bulk insert加速归档过程
当需要归档的数据量很大,比如第一次做归档的时候,可以考虑通过尝试bulk insert的方式来加速归档过程,命令如下所示。
pt-archiver --source h=rds01.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=rd_test,t=large_tab_04 --charset=utf8 --dest h=rds02.mysql.rds.aliyuncs.com,P=3306,u=jacky,p=xxx,D=jacky,t=large_tab_04 --where "1=1" --limit 5000 --commit-each --bulk-insert --no-version-check --statistics
注:
--bulk-insert:批量插入数据,会自动启用--bulk-delete和--commit-each,每次插入行数通过--limit选项指定。
--statistics:显示pt-archiver本次操作的统计信息。
阿里云关系型数据库主要有以下几种:RDS MySQL版、RDS PostgreSQL 版、RDS SQL Server 版、PolarDB MySQL版、PolarDB PostgreSQL 版、PolarDB分布式版 。


