
-

环境准备
(1)修改 IP
(2)修改主机名及主机名和 IP 地址的映射
(3)关闭防火墙
(4)ssh 免密登录
(5)安装 JDK,配置环境变量等
(6)配置 Zookeeper 集群
规划集群
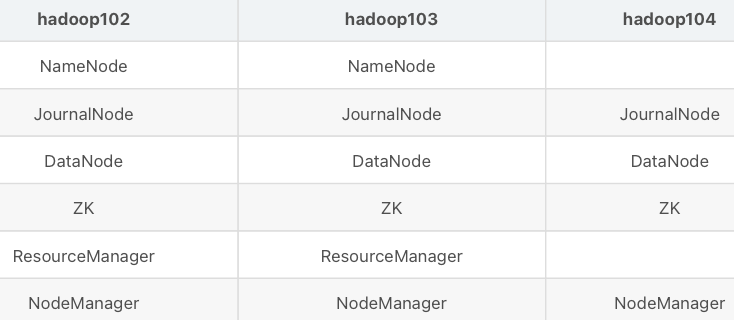
具体配置
(1)yarn-site.xml
(2)同步更新其他节点的配置信息
启动 hdfs
(1)在各个 JournalNode 节点上,输入以下命令启动 journalnode 服务:
sbin/hadoop-daemon.sh start journalnode
(2)在 [nn1] 上,对其进行格式化,并启动:
bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode
(3)在 [nn2] 上,同步 nn1 的元数据信息:
bin/hdfs namenode -bootstrapStandby
(4)启动 [nn2]:
sbin/hadoop-daemon.sh start namenode
(5)启动所有 DataNode
sbin/hadoop-daemons.sh start datanode
(6)将 [nn1] 切换为 Active
bin/hdfs haadmin -transitionToActive nn1
启动 YARN
(1)在 hadoop102 中执行:
sbin/start-yarn.sh
(2)在 hadoop103 中执行:
sbin/yarn-daemon.sh start resourcemanager
(3)查看服务状态
bin/yarn rmadmin -getServiceState rm1
2021-12-11 13:52:58赞同 展开评论 打赏
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。


相关电子书
更多

