全双工自然对话的技术方案是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
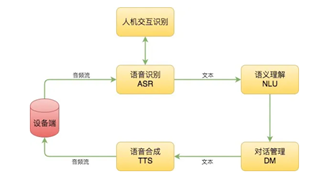
设备端:负责听和说。主要解决什么时候听,有没有听到语音,听到的语音有多长;什么时候说,以及说什么。 语音识别:即 ASR,将用户的语音识别成文本,并提取声音的特征。 语义理解:即 NLU,负责理解用户说了什么并转换成机器可读的信息。 语音合成:即 TTS,负责将文本转换成语音。 对话管理:即 DM,根据语义理解的结果和会话的上下文信息调用各种服务完成用户的请求。 人机交互识别:根据 ASR 输出的声学特征判断收到语音是不是用户和音箱说的话。