
如何区别存储和索引的方式,以及整个用户视角看起来它大概是什么样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如图示,用户写了一个 SQL 之后,首先会按照用户分区键路由到对应要找的表上面,找对逻辑对象 Table。
第二步通过 Distribution Key 找到对应 Shard。
第三步是 Segment Key,找到 Shard 之后要找对应 Shard 上面的文件,因为实际数据是存储成一个个文件,我们通过 Segment Key 找到想要打开的文件。
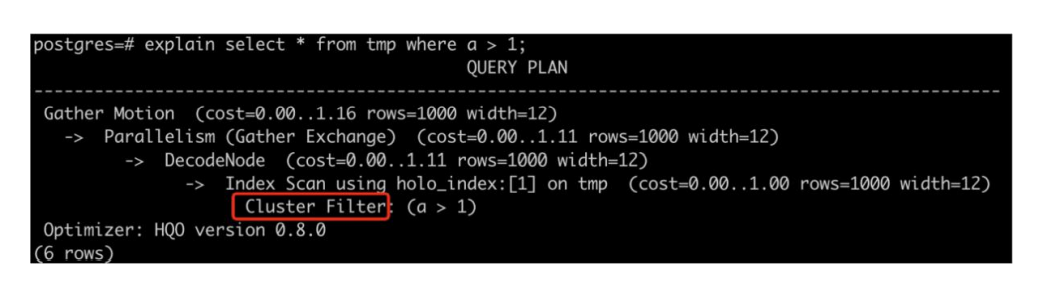
第四步是在文件内部,数据是否有序,这是通过 Clustering Key 来查找的,Clusterin g Key 帮助我们找对实际文件区间。
第五步是 Bitmap。因为 Hologres 把数据按照一个个 Batch 存储,在一个 Batch 里面,我们需要通过 Bitmap 快速定位到某一行,否则需要把某一个区间范围内所有的数据扫一遍。
图中从上往下不同的过程,越来越到文件内部,越往上是越大的范围。
资料来源:《实时数仓“王炸组合”-实时计算》,下载链接:https://developer.aliyun.com/topic/download?id=7944
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



