
我是一名大数据初学者。
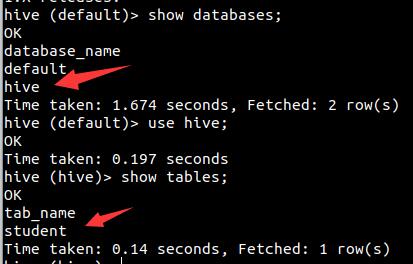
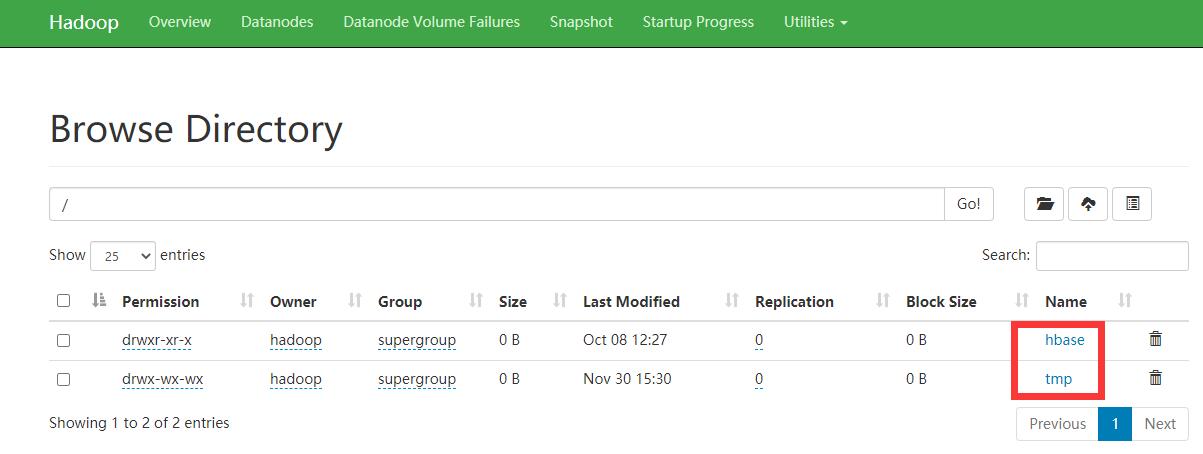
昨天点击弹出一个软件升级的提示,升级后hive里面的所有文件在hadoop都找不到了。但是hive能正常运行。 我的hive默认路径是 /user/hive/warehouse,系统是ubuntu,此前软件配置没有问题。
在其他搜索引擎找不到解决方案,特来此向高人请教解决方案。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Hadoop archive 唯一的优势可能就是将众多的小文件打包成一个har 文件了,那这个文件就会按照dfs.block.size 的大小进行分块,因为hdfs为每个块的元数据大小大约为150个字节,如果众多小文件的存在(什么是小文件内,就是小于dfs.block.size 大小的文件,这样每个文件就是一个block)占用大量的namenode 堆内存空间,打成har 文件可以大大降低namenode 守护节点的内存压力。但对于MapReduce 来说起不到任何作用,因为har文件就相当一个目录,仍然不能讲小文件合并到一个split中去,一个小文件一个split ,任然是低效的,这里要说一点<<hadoop 权威指南 中文版>>对这个翻译有问题,上面说可以分配到一个split中去,但是低效的。 既然有优势自然也有劣势,这里不说它的不足之处,仅介绍如果使用har 并在hadoop中更好的使用har 文件 首先 看下面的命令 hadoop archive -archiveName 20131101.har /user/hadoop/login/201301/01 /user/hadoop/login/201301/01 我用上面的命令就可以将 /user/hadoop/login/201301/01 目录下的文件打包成一个 20131101.har 的归档文件,但是系统不会自动删除源文件,需要手动删除 hadoop fs -rmr /user/hadoop/login/201301/01/..* 我是用正则表达式来删除的,大家根据自己的需求删除原始文件
