
服务器centos7.2
hive版本0.12
hadoop版本2.7.6
----------------分割线-----------------
创建table的时候,用的外部表,放置于mysql,其中使用了partitioned by 关键字 (
partitioned by (logdate string,hour string))。
具体代码片段为:
create external table people(id int,name string)
partitioned by (logdate string,hour string) row format delimited
fields terminated by ',';--------------------------------
但是!! 往表里面存入数据时就报错为hive.partition doesn't exists !!!!
java.sql.SQLSyntaxErrorException: Table 'hive.PARTITIONS' doesn't existmysql那边看了,hive数据库生成了,但确实没有partition表。只有下图。
select * 之后确实是我添加的partition字段
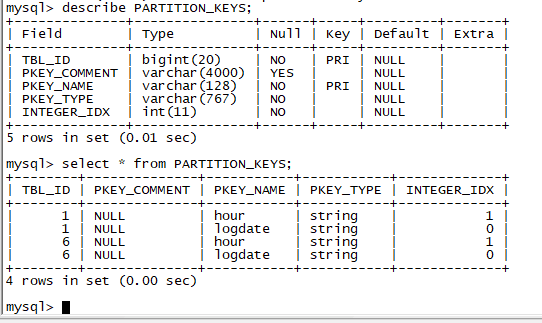
可是没办法改这个表的名字为partition啊(似乎是因为mysql关键字存在partition)!!

那我该如何存取数据进入这个hive表??
求帮助,谢谢。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
<p>从mysql导入到hive有几种办法,最简单的一个给你说下,你参考下</p>
1.我看你hive表内容是逗号分隔。然后建了分区,那么你可以在hdfs上找到对应目录了。
2.将mysql数据导出,用outfile或者程序导出都可以,导出成逗号分隔的文件,列和hive对应上。
3.将导出文件上传到hdfs对应分区。
这样就可以了
我是想从hdfs 加载数据到hive表内,,, 只是元数据放在mysql里面而已
<p>你的图挂了 ,看不出来问题。我把我的映射语句发出来,你做个参考吧</p>
-- 如果分区存在则删除
ALTER TABLE yourtable DROP IF EXISTS PARTITION (day=${day},hour=${hour});
ALTER TABLE yourtable ADD IF NOT EXISTS PARTITION (day=${day},hour=${hour}) LOCATION 'your hdfs location';
我很好奇我得图是不能刷出来吗?在其他人的视角里面到底是怎么样的? 我这边都能看见。。 感谢你的回答,虽然我暂时没有解决这个问题,但是并不完全影响我目前的实验。
<p>一摸一样的问题,搞了一天,请问楼主解决了吗</p>
我发现了,md,是mysql驱动包版本的原因,炸了。
