
本人使用pandas.read_csv()读取一个csv文件内容获取得到一个datafame
当我想替换列名的时候我尝试使用传参
opcsv=pandas.read_csv(f,header=0,dtype={'code':str},names=names)
获得一个报错
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 74, in <module>
openfile(inputdir)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 19, in openfile
openfile(fi_d)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 19, in openfile
openfile(fi_d)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 24, in openfile
tab(path,fi)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 45, in tab
opcsv=pandas.read_csv(f,header=0,dtype={'code':str},names=names)
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py", line 678, in parser_f
return _read(filepath_or_buffer, kwds)
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py", line 446, in _read
data = parser.read(nrows)
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py", line 1036, in read
ret = self._engine.read(nrows)
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\io\parsers.py", line 1848, in read
data = self._reader.read(nrows)
File "pandas\_libs\parsers.pyx", line 876, in pandas._libs.parsers.TextReader.read
File "pandas\_libs\parsers.pyx", line 891, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas\_libs\parsers.pyx", line 968, in pandas._libs.parsers.TextReader._read_rows
File "pandas\_libs\parsers.pyx", line 1028, in pandas._libs.parsers.TextReader._convert_column_data
pandas.errors.ParserError: Too many columns specified: expected 104 and found 103
也就是我的csv文件有103列,但是传入的参数name有104个值
当我再尝试使用
opcsv=pandas.read_csv(f,header=0,dtype={'code':str},names=names)
opcsv.columns=names
的时候也是同样的情况
Traceback (most recent call last):
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 74, in <module>
openfile(inputdir)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 19, in openfile
openfile(fi_d)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 19, in openfile
openfile(fi_d)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 24, in openfile
tab(path,fi)
File "C:/Users/Administrator/Desktop/computerXP/upEXdate.py", line 46, in tab
opcsv.columns=names
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py", line 4389, in __setattr__
return object.__setattr__(self, name, value)
File "pandas\_libs\properties.pyx", line 69, in pandas._libs.properties.AxisProperty.__set__
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\generic.py", line 646, in _set_axis
self._data.set_axis(axis, labels)
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals.py", line 3323, in set_axis
'values have {new} elements'.format(old=old_len, new=new_len))
ValueError: Length mismatch: Expected axis has 103 elements, new values have 104 elements
因为手上有一个项目目录里面的csv表列数稍有不同,最少100列最多104列因此我的思路是按照最长列数来同一读取csv表处理列名,对于100列的csv处理后多出来的4列的值让他都为NAN。
本人也尝试过干脆以100列来处理,但是发现超出100列的csv表会将前面的几列数据抛弃然后整体往前挪动补全(此时我想要的结果应该是抛弃的是后面多出来几列的数据而不是头部的几列数据)
请问有没有相关的处理思路,因为读取了文档和网上搜索都并没有遇见与我现在遇到的相关问题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
<div class="ref">
(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code
1,2,3,4,23
5,6,7,7,234
23,423,4,21,123
(tf) [root@bogon testpd]# python
Python 3.6.6 (default, Aug 13 2018, 18:24:23)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> names = ['A','x','C','D','code','xxx','yyy']
>>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str})
>>> opcsv
A B C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>> opcsv.columns = names[:len(opcsv.columns)]
>>> opcsv
A x C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>>
<pre>opcsv=pandas.read_csv(f,header=0,dtype={'code':str})
opcsv.reindex(columns=names)
请问我不太懂reindex(columns=names)是实现什么的 我尝试了一下似乎没有生效
<p>看下结果是不是你要的效果</p>
(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code
1,2,3,4,23
5,6,7,7,234
23,423,4,21,123
(tf) [root@bogon testpd]# python
Python 3.6.6 (default, Aug 13 2018, 18:24:23)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> names = ['A','B','C','D','code','xxx','yyy']
>>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str})
>>> opcsv
A B C D code
0 1 2 3 4 23
1 5 6 7 7 234
2 23 423 4 21 123
>>> newpocsv = opcsv.reindex(columns=names)
>>> newpocsv
A B C D code xxx yyy
0 1 2 3 4 23 NaN NaN
1 5 6 7 7 234 NaN NaN
2 23 423 4 21 123 NaN NaN
>>>
是的!这正是我想要的结果,但是不知道为什么我按照您给的代码尝试了一遍发现,列名并没有成功生效。
以下是我打印调试的结果,由上面的list替换下面dataframe的表头
但令我无奈的是他并没有生效,我也不清楚具体的原因
<p>是的!这正是我想要的结果,但是不知道为什么我按照您给的代码尝试了一遍发现,列名并没有成功生效。</p>

以下是我打印调试的结果,由上面的list替换下面dataframe的表头
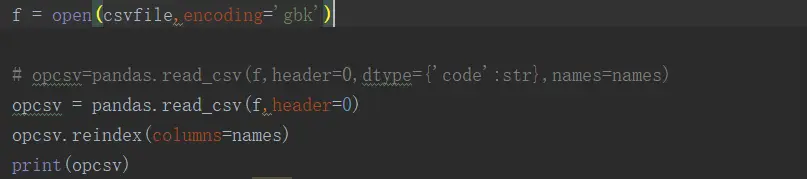
但令我无奈的是他并没有生效,我也不清楚具体的原因
回复 <a class="referer" target="_blank">@007</a> : 我通过回复成功实现了,但又引发了新的问题
opcsv = opcsv.reindex(columns=names)
<p><img height="502" src="https://oscimg.oschina.net/oscnet/7394ce4296a0d3a4bea1fa33fbfb32a641a.jpg" width="1782"></p>
原有的数据也被全部清空赋值NaN了。我不清楚具体原因,我现在正尝试断点debug查看问题所在
<p>当我在debug的时候发现了这样的报错</p>
Traceback (most recent call last):
File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1664, in <module>
main()
File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1658, in main
globals = debugger.run(setup['file'], None, None, is_module)
File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\pydevd.py", line 1068, in run
pydev_imports.execfile(file, globals, locals) # execute the script
File "E:\Program Files (x86)\PyCharm 2018.1.3\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "C:/Users/Administrator/Desktop/computerXP/hebing.py", line 2, in <module>
import pymysql,pandas,os,time,numpy
File "C:\ProgramData\Anaconda3\lib\site-packages\pandas\__init__.py", line 19, in <module>
"Missing required dependencies {0}".format(missing_dependencies))
ImportError: Missing required dependencies ['numpy']


我不知道是否是他的原因
<p>我似乎找到了原因</p>
frame = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'], columns=['c1', 'c2', 'c3']) print frame
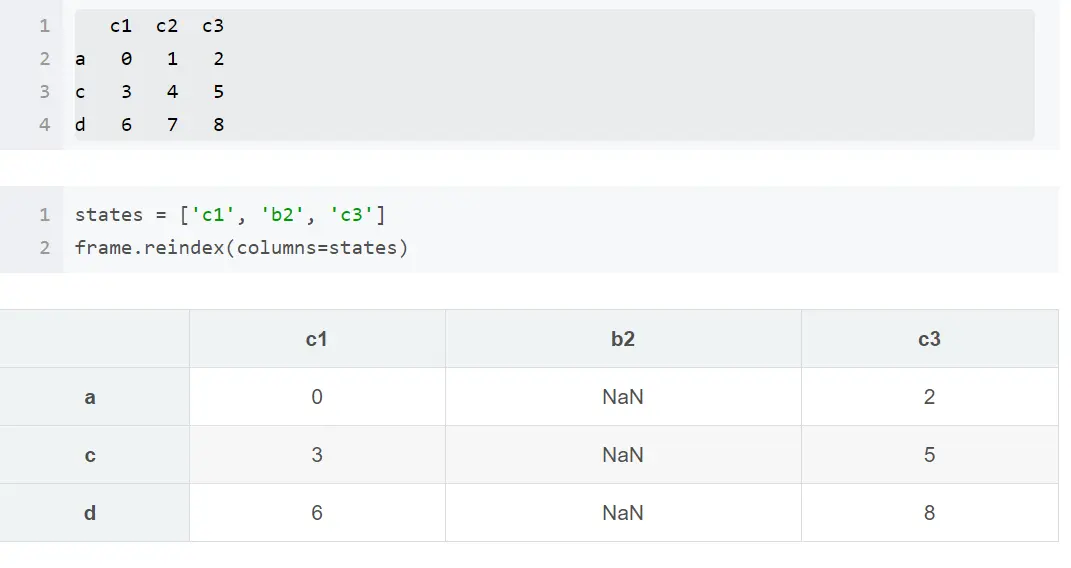
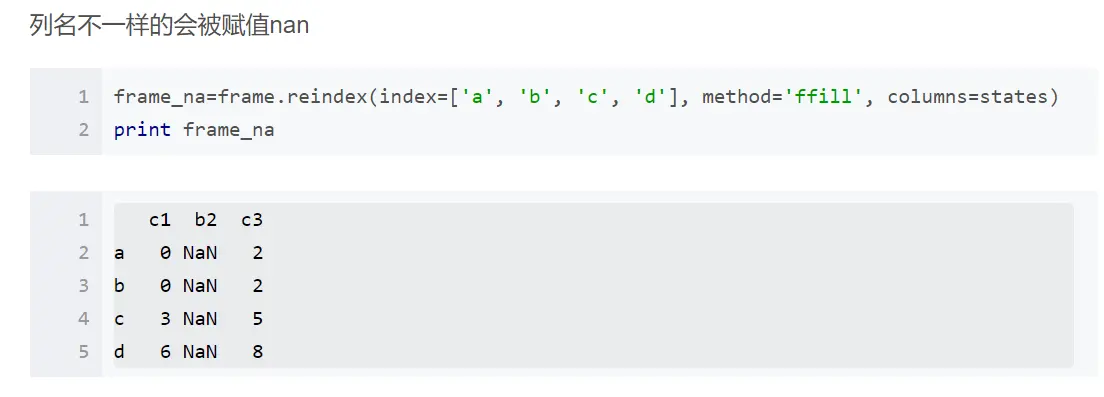
因为我本地读取的csv文件是
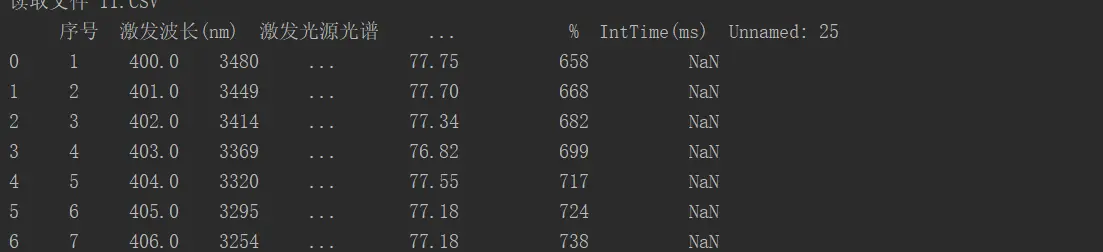
这样的中文列名,而我需要替换以下列名

因此就好在替换成功的同时将所有原来的数据变为NaN
因为如果从read_csv传参names来更改列名就必须要小于等于csv列数
或者如果只要解决names参数传入的元素少于csv列数dataframe从后抛弃数据这样是否可行?
<pre>(tf) [root@bogon testpd]# cat test.csv
A,B,C,D,code 1,2,3,4,23 5,6,7,7,234 23,423,4,21,123 (tf) [root@bogon testpd]# python Python 3.6.6 (default, Aug 13 2018, 18:24:23) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import pandas as pd >>> names = ['A','x','C','D','code','xxx','yyy'] >>> opcsv=pd.read_csv('test.csv', header=0, dtype={'code':str}) >>> opcsv A B C D code 0 1 2 3 4 23 1 5 6 7 7 234 2 23 423 4 21 123 >>> opcsv.columns = names[:len(opcsv.columns)] >>> opcsv A x C D code 0 1 2 3 4 23 1 5 6 7 7 234 2 23 423 4 21 123 >>>
<p>我的天,简直不敢相信,这正是我想要得完美结果,请问您是做了理解pandas多深才做到的。能分享一下您是怎么去剖析pandas得到的</p>
