使用来自不同分布的数据,进行训练和测试
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
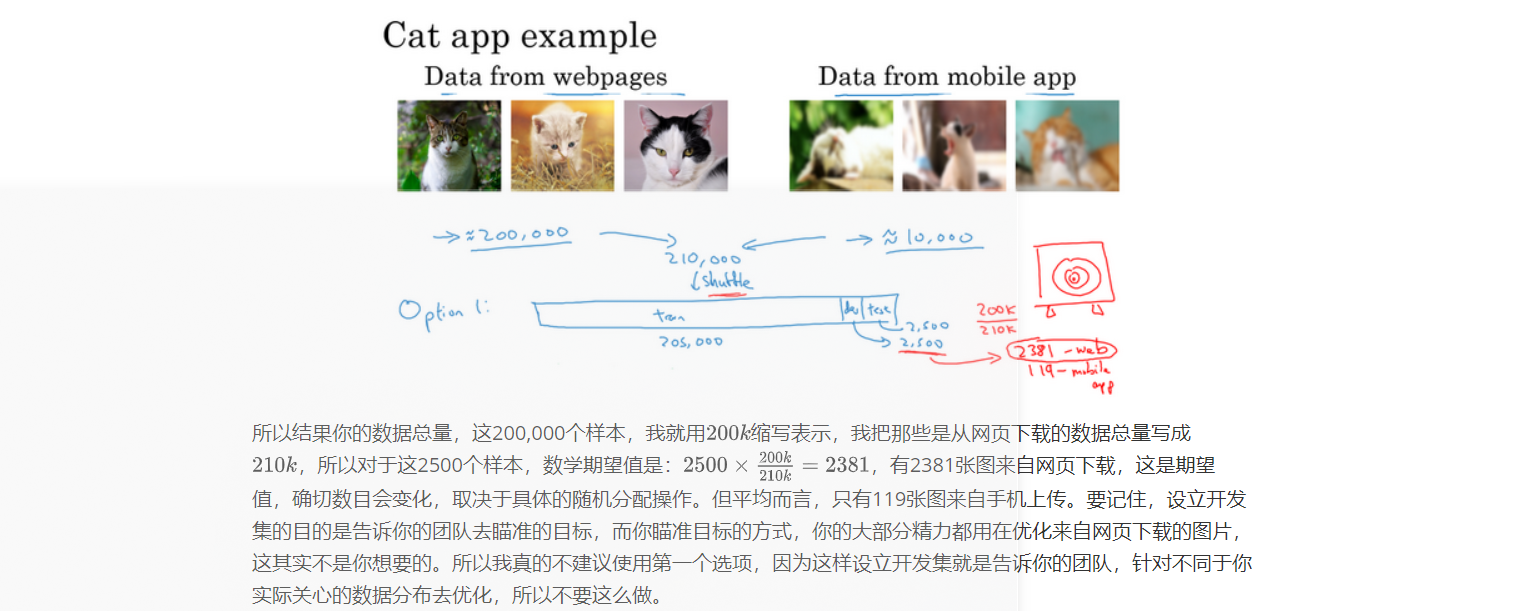
假设你在开发一个手机应用,用户会上传他们用手机拍摄的照片,你想识别用户从应用中上传的图片是不是猫。现在你有两个数据来源,一个是你真正关心的数据分布,来自应用上传的数据,比如右边的应用,这些照片一般更业余,取景不太好,有些甚至很模糊,因为它们都是业余用户拍的。另一个数据来源就是你可以用爬虫程序挖掘网页直接下载,就这个样本而言,可以下载很多取景专业、高分辨率、拍摄专业的猫图片。如果你的应用用户数还不多,也许你只收集到10,000张用户上传的照片,但通过爬虫挖掘网页,你可以下载到海量猫图,也许你从互联网上下载了超过20万张猫图。而你真正关心的算法表现是你的最终系统处理来自应用程序的这个图片分布时效果好不好,因为最后你的用户会上传类似右边这些图片,你的分类器必须在这个任务中表现良好。现在你就陷入困境了,因为你有一个相对小的数据集,只有10,000个样本来自那个分布,而你还有一个大得多的数据集来自另一个分布,图片的外观和你真正想要处理的并不一样。但你又不想直接用这10,000张图片,因为这样你的训练集就太小了,使用这20万张图片似乎有帮助。但是,困境在于,这20万张图片并不完全来自你想要的分布,那么你可以怎么做呢?
这里有一种选择,你可以做的一件事是将两组数据合并在一起,这样你就有21万张照片,你可以把这21万张照片随机分配到训练、开发和测试集中。为了说明观点,我们假设你已经确定开发集和测试集各包含2500个样本,所以你的训练集有205000个样本。现在这么设立你的数据集有一些好处,也有坏处。好处在于,你的训练集、开发集和测试集都来自同一分布,这样更好管理。但坏处在于,这坏处还不小,就是如果你观察开发集,看看这2500个样本其中很多图片都来自网页下载的图片,那并不是你真正关心的数据分布,你真正要处理的是来自手机的图片。