
1
条回答
 写回答
写回答
-

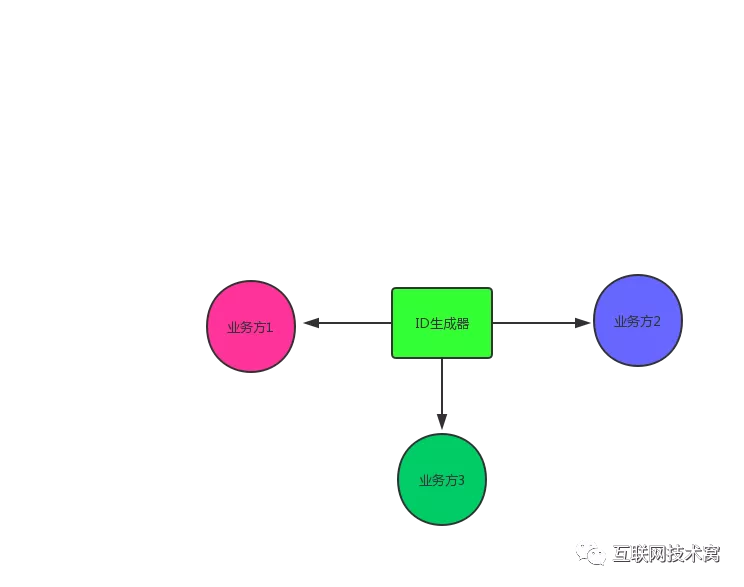
是的。确实如此,因此又有人说:“可以利用MySQL主从模式,主库挂了,使用从库。” 这只能算是一种比较low的策略,因为如果主库挂了,从库没来得及同步,就会生成重复的ID。有没有更好的方法呢?我们可以使用“双主模式“,也就是有两个MySQL实例,这两个都能生成ID。如图所示,我们原来的模式:
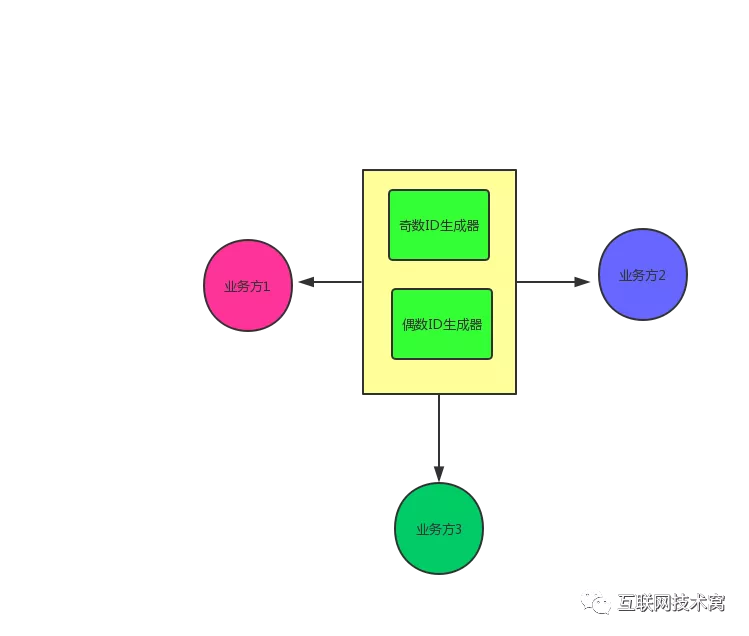
双主模式是该怎么样呢?如何保持唯一性?我们可以让一台实例生成奇数ID,另一台生成偶数ID。
奇数那一台:
set @@auto_increment_offset=1; --起始值 set @@auto_increment_increment=2; -- 步长偶数那一台:
set @@auto_increment_offset=2; --起始值 set @@auto_increment_increment=2; -- 步长当两台都OK的时候,随机取其中的一台生成ID;若其中一台挂了,则取另外一台生成ID。如图所示:
 细心会发现,N个节点,只要起始值为1,2,...N,然后步长为N,就会生成各不相同的ID。(PS:后文有推导公式)2020-04-24 11:16:15赞同 展开评论 打赏
细心会发现,N个节点,只要起始值为1,2,...N,然后步长为N,就会生成各不相同的ID。(PS:后文有推导公式)2020-04-24 11:16:15赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答
问答排行榜
最热
最新


推荐问答



