
Snowflake 算法购构成
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
下图是 Snowflake 算法的 ID 构成图: 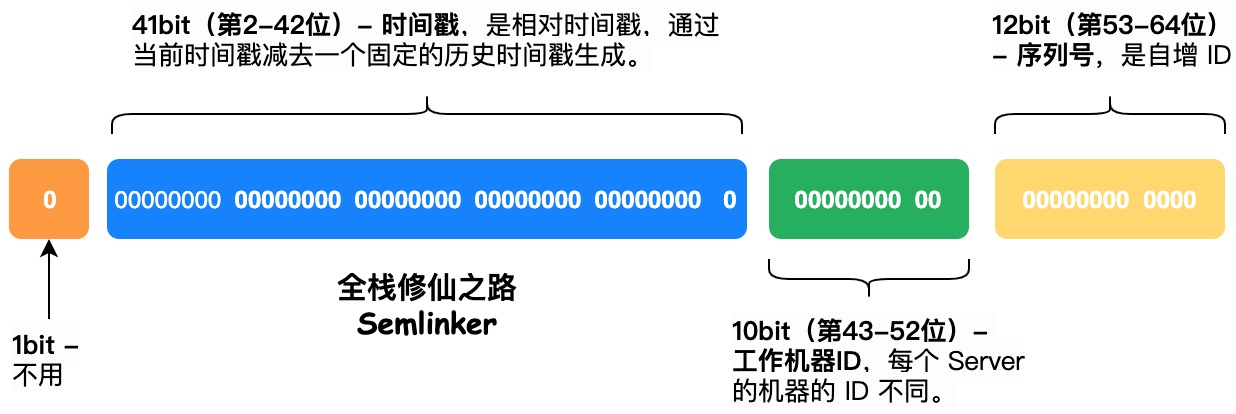
1 位标识部分,该位不用主要是为了保持 ID 的自增特性,若使用了最高位,int64_t 会表示为负数。在 Java 中由于 long 类型的最高位是符号位,正数是 0,负数是 1,一般生成的 ID 为正整数,所以最高位为 0;
41 位时间戳部分,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间减去固定的开始时间),这样可以使产生的 ID 从更小值开始;41 位的时间戳可以使用 69 年,(1L << 41) / (1000L 60 60 24 365) = (2199023255552 / 31536000000) ≈ 69.73 年;
10 位工作机器 ID 部分,Twitter 实现中使用前 5 位作为数据中心标识,后 5 位作为机器标识,可以部署 1024 (2^10)个节点;
12 位序列号部分,支持同一毫秒内同一个节点可以生成 4096 (2^12)个 ID;
Snowflake 算法生成的 ID 大致上是按照时间递增的,用在分布式系统中时,需要注意数据中心标识和机器标识必须唯一,这样就能保证每个节点生成的 ID 都是唯一的。我们不一定需要像 Twitter 那样使用 5 位作为数据中心标识,另 5 位作为机器标识,可以根据我们业务的需要,灵活分配工作机器 ID 部分。比如:若不需要数据中心,完全可以使用全部 10 位作为机器标识;若数据中心不多,也可以只使用 3 位作为数据中心,7 位作为机器标识。

