
大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么做的?分表分库了有什么问题?有用到中间件么?他们的原理知道么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
垂直分区:
根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。
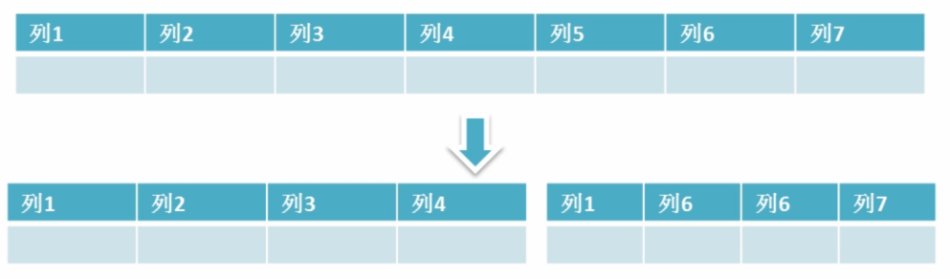
垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
垂直分表
把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中
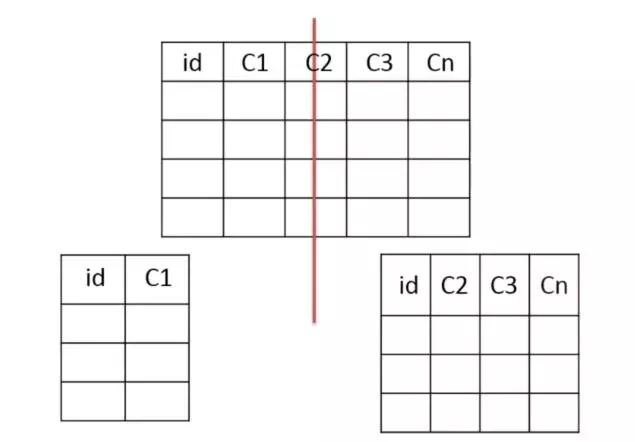
适用场景 1、如果一个表中某些列常用,另外一些列不常用 2、可以使数据行变小,一个数据页能存储更多数据,查询时减少I/O次数 缺点 有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差 对于应用层来说,逻辑算法增加开发成本 管理冗余列,查询所有数据需要join操作
水平分区:
保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
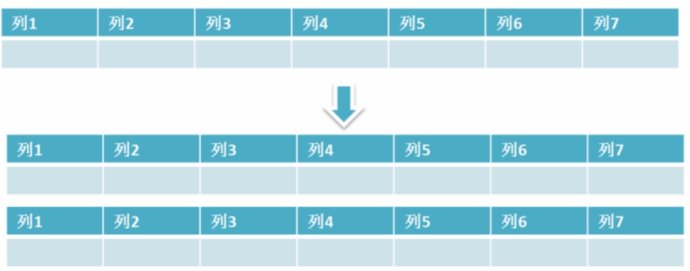
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水平拆分最好分库 。
水平拆分能够 支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨界点Join性能较差,逻辑复杂。
《Java工程师修炼之道》的作者推荐 尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度 ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
水平分表: 表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数
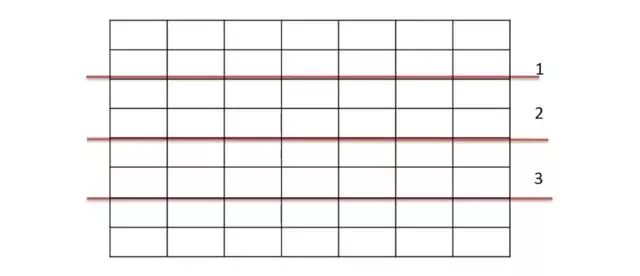
适用场景 1、表中的数据本身就有独立性,例如表中分表记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用。
2、需要把数据存放在多个介质上。
水平切分的缺点
1、给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需UNION操作
2、在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数 下面补充一下数据库分片的两种常见方案:
客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。 中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
事务支持 分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
跨库join
只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。 分库分表方案产品
跨节点的count,order by,group by以及聚合函数问题 这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
数据迁移,容量规划,扩容等问题 来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
ID问题
一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由. 一些常见的主键生成策略
