
【现象总结】手动触发major compaction后,用raw scan发现还有Delete标志存在。
找了一行有问题的行,然后手动major compact它所在的region,问题能重现。 已确认两点: 在对应的RegionServer的log里能确认Major compaction成功了,最后生成的新HFile也只有一个。 Delete标志没有在Memstore中,因为先触发flush再触发major compaction后还是能看到delete标志
用hfile工具打印底层的key value发现Delete标志确实还存在: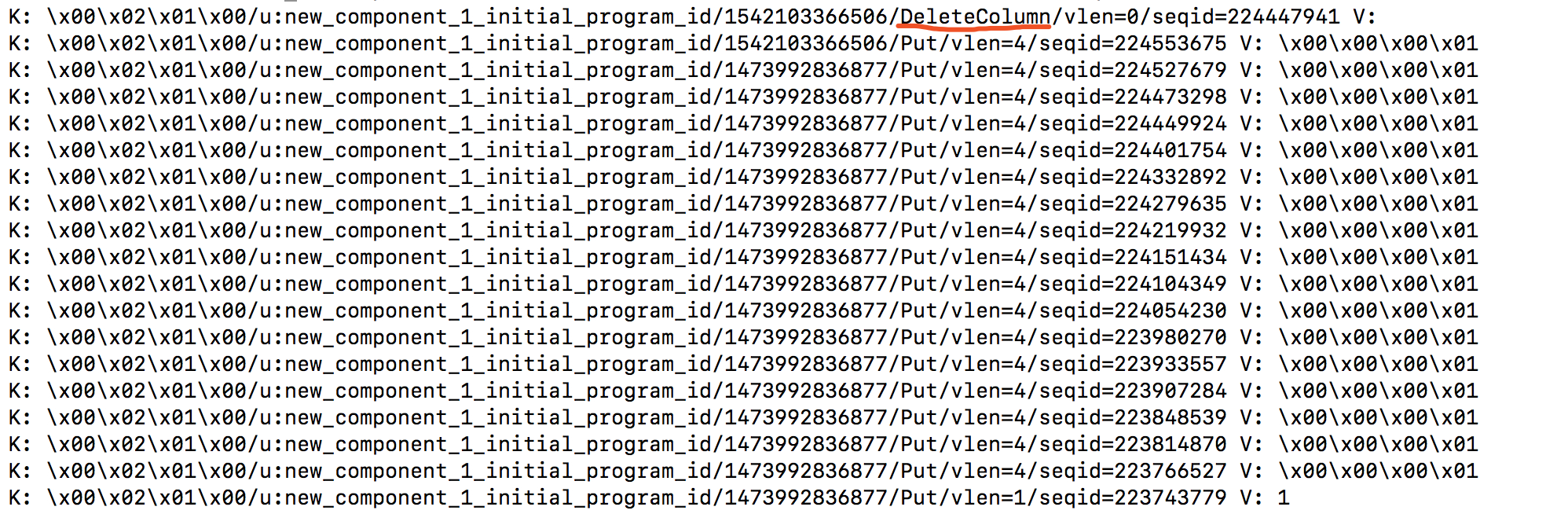 图中的两个时间戳,大的是1542103366506(Tue Nov 13 02:02:46 PST 2018);小的是1473992836877(Thu Sep 15 19:27:16 PDT 2016),都是合法时间戳。另外集群的 hbase.hstore.time.to.purge.deletes 配置是0。
图中的两个时间戳,大的是1542103366506(Tue Nov 13 02:02:46 PST 2018);小的是1473992836877(Thu Sep 15 19:27:16 PDT 2016),都是合法时间戳。另外集群的 hbase.hstore.time.to.purge.deletes 配置是0。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
/** Parameter name for # days to keep MVCC values during a major compaction / public static final String KEEP_SEQID_PERIOD = "hbase.hstore.compaction.keep.seqId.period"; /* At least to keep MVCC values in hfiles for 5 days */ public static final int MIN_KEEP_SEQID_PERIOD = 5;
就这个,会控制MVCC至少保留几天,默认值是5天,所以你现在再跑一次major compaction可能就没了
这个主要是解决replication乱序可能导致主备不一致的问题,比如你先put再delete,同步到备集群之后是先delete再put,如果在中间做了一个major compaction,delete没了,之后同步过去那个put就没法被删掉了,于是数据就不一致了
