
转载自:http://www.hbase.group/article/37
HBase是一个开源可伸缩的针对海量数据存储的分布式nosql数据库,它根据Google Bigtable数据模型来建模并构建在hadoop的hdfs存储系统之上。它和关系型数据库Mysql, Oracle等有明显的区别,HBase的数据模型牺牲了关系型数据库的一些特性但是却换来了极大的可伸缩性和对表结构的灵活操作。
在一定程度上,Hbase又可以看成是以行键(Row Key),列标识(column qualifier),时间戳(timestamp)标识的有序Map数据结构的数据库,具有稀疏,分布式,持久化,多维度等特点。
Base的数据模型介绍 HBase的数据模型也是由一张张的表组成,每一张表里也有数据行和列,但是在HBase数据库中的行和列又和关系型数据库的稍有不同。下面统一介绍HBase数据模型中一些名词的概念:
表(Table): HBase会将数据组织进一张张的表里面,但是需要注意的是表名必须是能用在文件路径里的合法名字,因为HBase的表是映射成hdfs上面的文件。 行(Row): 在表里面,每一行代表着一个数据对象,每一行都是以一个行键(Row Key)来进行唯一标识的,行键并没有什么特定的数据类型,以二进制的字节来存储。 列族(Column Family): 在定义HBase表的时候需要提前设置好列族, 表中所有的列都需要组织在列族里面,列族一旦确定后,就不能轻易修改,因为它会影响到HBase真实的物理存储结构,但是列族中的列标识(Column Qualifier)以及其对应的值可以动态增删。表中的每一行都有相同的列族,但是不需要每一行的列族里都有一致的列标识(Column Qualifier)和值,所以说是一种稀疏的表结构,这样可以一定程度上避免数据的冗余。例如:{row1, userInfo: telephone —> 137XXXXX869 }{row2, userInfo: fax phone —> 0898-66XXXX } 行1和行2都有同一个列族userinfo,但是行1中的列族只有列标识(Column Qualifier):移动电话号码,而行2中的列族中只有列标识(Column Qualifier):传真号码。 列标识(Column Qualifier): 列族中的数据通过列标识来进行映射,其实这里大家可以不用拘泥于“列”这个概念,也可以理解为一个键值对,Column Qualifier就是Key。列标识也没有特定的数据类型,以二进制字节来存储。 单元(Cell): 每一个 行键,列族和列标识共同组成一个单元,存储在单元里的数据称为单元数据,单元和单元数据也没有特定的数据类型,以二进制字节来存储。 时间戳(Timestamp): 默认下每一个单元中的数据插入时都会用时间戳来进行版本标识。读取单元数据时,如果时间戳没有被指定,则默认返回最新的数据,写入新的单元数据时,如果没有设置时间戳,默认使用当前时间。每一个列族的单元数据的版本数量都被HBase单独维护,默认情况下HBase保留3个版本数据。  有时候,你也可以把HBase看成一个多维度的Map模型去理解它的数据模型。正如下图,一个行键映射一个列族数组,列族数组中的每个列族又映射一个列标识数组,列标识数组中的每一个列标识(Column Qualifier)又映射到一个时间戳数组,里面是不同时间戳映射下不同版本的值,但是默认取最近时间的值,所以可以看成是列标识(Column Qualifier)和它所对应的值的映射。用户也可以通过HBase的API去同时获取到多个版本的单元数据的值。Row Key在HBase中也就相当于关系型数据库的主键,并且Row Key在创建表的时候就已经设置好,用户无法指定某个列作为Row Key。
有时候,你也可以把HBase看成一个多维度的Map模型去理解它的数据模型。正如下图,一个行键映射一个列族数组,列族数组中的每个列族又映射一个列标识数组,列标识数组中的每一个列标识(Column Qualifier)又映射到一个时间戳数组,里面是不同时间戳映射下不同版本的值,但是默认取最近时间的值,所以可以看成是列标识(Column Qualifier)和它所对应的值的映射。用户也可以通过HBase的API去同时获取到多个版本的单元数据的值。Row Key在HBase中也就相当于关系型数据库的主键,并且Row Key在创建表的时候就已经设置好,用户无法指定某个列作为Row Key。 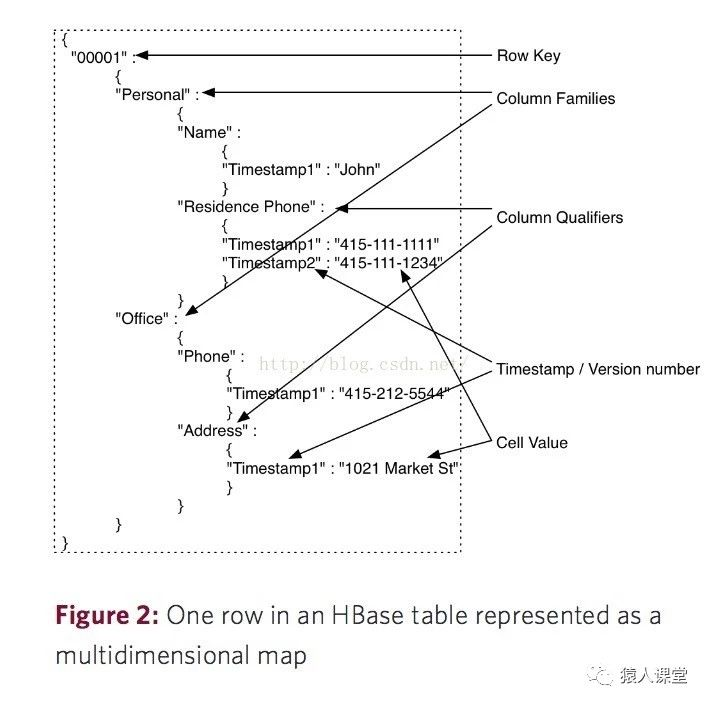 又有的时候,你也可以把HBase看成是一个类似Redis那样的Key-Value数据库。如下图,当你要查询某一行的所有数据时,Row Key就相当于Key,而Value就是单元中的数据(列族,列族里的列和列中时间戳所对应的不同版本的值);当深入到HBase底层的存储机制时,用户要查询指定行里某一条单元数据时,HBase会去读取一个数据块,里面除了有要查询的单元数据,可能同时也会获取到其它单元数据,因为这个数据块还包含着这个Row Key所对应的其它列族或其它的列信息,这些信息实际也代表着另一个单元数据,这也是HBase的API内部实际的工作原理
又有的时候,你也可以把HBase看成是一个类似Redis那样的Key-Value数据库。如下图,当你要查询某一行的所有数据时,Row Key就相当于Key,而Value就是单元中的数据(列族,列族里的列和列中时间戳所对应的不同版本的值);当深入到HBase底层的存储机制时,用户要查询指定行里某一条单元数据时,HBase会去读取一个数据块,里面除了有要查询的单元数据,可能同时也会获取到其它单元数据,因为这个数据块还包含着这个Row Key所对应的其它列族或其它的列信息,这些信息实际也代表着另一个单元数据,这也是HBase的API内部实际的工作原理  HBase提供了丰富的API接口让用户去操作这些数据。主要的API接口有3个,Put,Get,Scan。Put和Get是操作指定行的数据的,所以需要提供行键来进行操作。Scan是操作一定范围内的数据,通过指定开始行键和结束行键来获取范围,如果没有指定开始行键和结束行键,则默认获取所有行数据。
HBase提供了丰富的API接口让用户去操作这些数据。主要的API接口有3个,Put,Get,Scan。Put和Get是操作指定行的数据的,所以需要提供行键来进行操作。Scan是操作一定范围内的数据,通过指定开始行键和结束行键来获取范围,如果没有指定开始行键和结束行键,则默认获取所有行数据。
HBase的表设计中需要注意的问题
当开始设计HBase中的表的时候需要考虑以下的几个问题: 1. Row Key的结构该如何设置,而Row Key中又该包含什么样的信息(这个很重要,下面的例子会有说明) 2. 表中应该有多少的列族 3. 列族中应该存储什么样的数据 4. 每个列族中存储多少列数据 5. 列的名字分别是什么,因为操作API的时候需要这些信息 6. 单元中(cell)应该存储什么样的信息 7. 每个单元中存储多少个版本信息 在HBase表设计中最重要的就是定义Row-Key的结构,要定义Row-Key的结构时就不得不考虑表的接入样本,也就是在真真实应用中会对这张表出现什么样的读写场景。
除此之外,在设计表的时候我们也应该要考虑HBase数据库的一些特性。
1. HBase中表的索引是通过Key来实现的
2. 在表中是通过Row Key的字典序来对一行行的数据来进行排序的,表中每一块区域的划分都是通过开始Row Key和结束Row Key来决定的。
3. 所有存储在HBase表中的数据都是二进制的字节,并没有数据类型。
4. 原子性只在行内保证,HBase表中并没有多行事务。
5. 列族(Column Family)在表创建之前就要定义好
6. 列族中的列标识(Column Qualifier)可以在表创建完以后动态插入数据时添加。
接下来我们考虑一个这样的场景,我们要设计一张表,用来保存微博上用户互粉的信息。所以设计表之前,我们要考虑业务中的读写场景。
读场景中我们要考虑: 1. 每个用户都关注了谁 2. 用户A有没有关注用户B 3. 谁关注了用户A
写场景中我们要考虑: 1. 用户关注了另一个用户 2. 用户取消关注某个用户
下面我们来看几种表结构的设计:
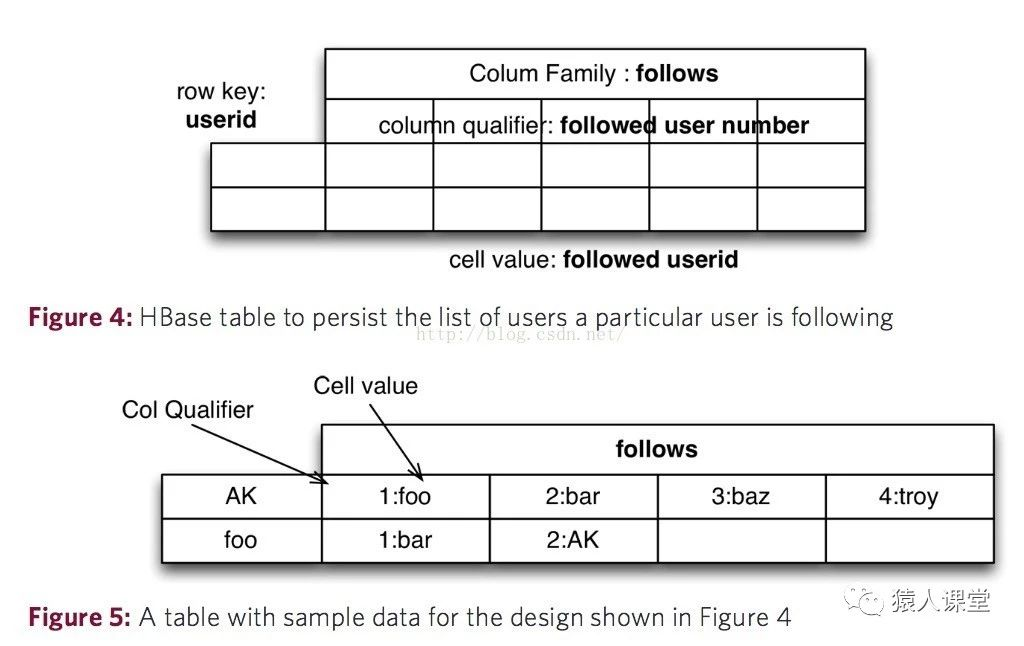
第一种表结构设计中,在这种表结构设计中,每一行代表着某个用户和所有他所关注的其它用户。这个用户ID就是Row Key,而每一个列标识(Column Qualifier)就是这个用户所关注的其他用户在列族里的序号,单元数据就是这个用户所关注的其他用户的用户ID。在这种表结构的设计下,“每个用户都关注了谁”这个问题很好解决,但对于“用户A有没有关注用户B”这个问题在列很多的时候,需要遍历所有单元数据去找到用户B,这样的开销会十分大。并且当添加新的被关注用户时,因为不知道给这个新用户分配什么样的列族序号,需要遍历整个列族中的所有列找出最后一个列,并将最后一个列的序号+1给新的被关注用户作为列族内的序号,这样的开销也十分大。
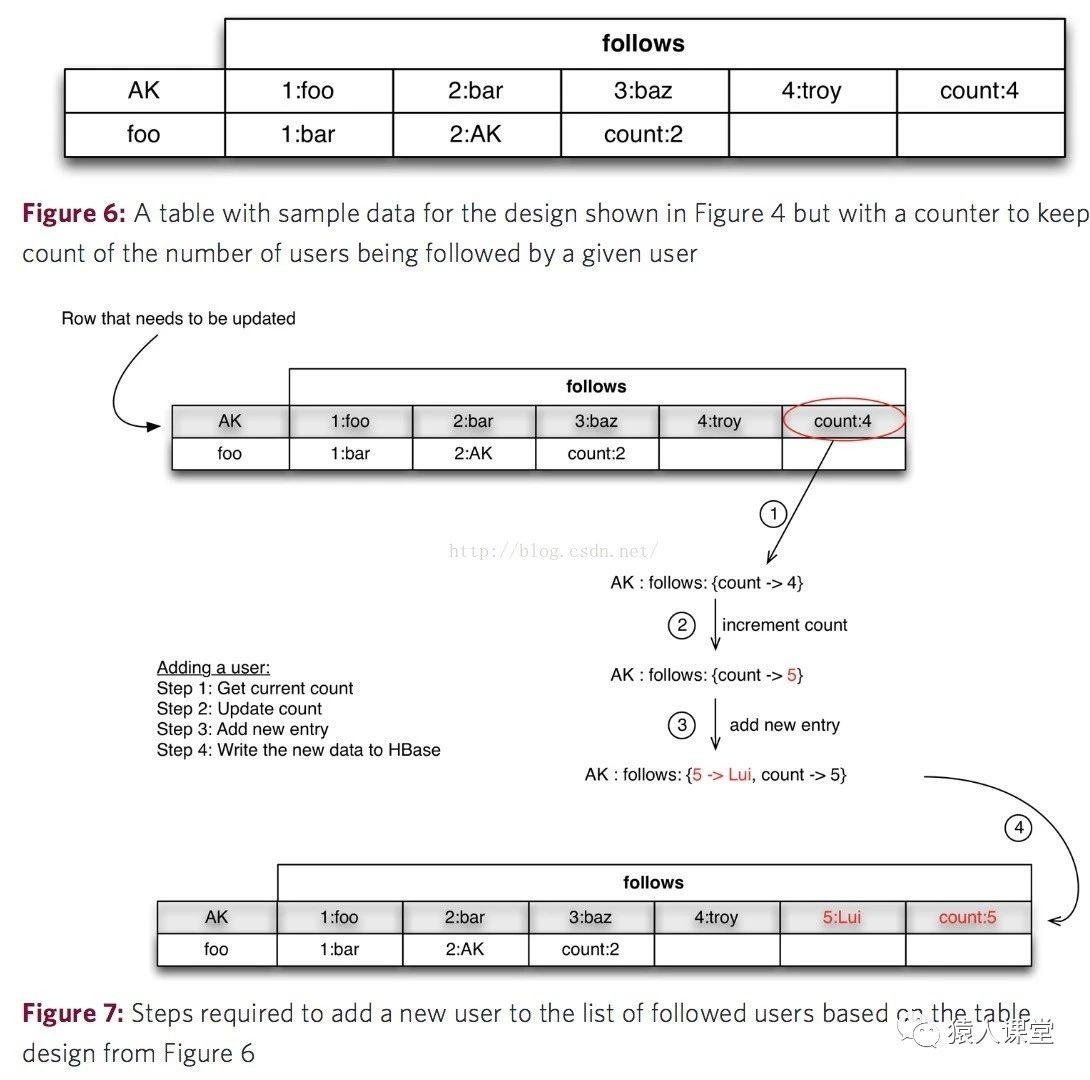
 所以衍生出了第二种表结构设计,如下图,添加一个counter记录列族中所有列的总数量,当添加新的被关注用户时,这个新用户的序号就是counter+1。但是当要取消关注某个用户时,一样得遍历所有的列数据,而且最大的问题是在于HBase不支持事务处理,这种通过counter来添加被关注用户的操作逻辑得写在客户端中。
所以衍生出了第二种表结构设计,如下图,添加一个counter记录列族中所有列的总数量,当添加新的被关注用户时,这个新用户的序号就是counter+1。但是当要取消关注某个用户时,一样得遍历所有的列数据,而且最大的问题是在于HBase不支持事务处理,这种通过counter来添加被关注用户的操作逻辑得写在客户端中。
 回想一下,列标识(Column Qualifier)存储的时候是二进制的字节,所以列标识可以存储任何数据,而且列标识还是动态增添的,基于这个特性我们再改进表的设计,如下图。这次以被关注的用户ID做为列标识(Column Qualifier),然后单元数据可以是任意数字,比如全部统一成1。
回想一下,列标识(Column Qualifier)存储的时候是二进制的字节,所以列标识可以存储任何数据,而且列标识还是动态增添的,基于这个特性我们再改进表的设计,如下图。这次以被关注的用户ID做为列标识(Column Qualifier),然后单元数据可以是任意数字,比如全部统一成1。
在这种表结构的设计下,添加新的被关注者,以及取消关注都会变得很简单。但是对于读场景中,谁关注了用户A这个问题,因为HBase数据库的索引只建立在Row Key上,这里不得不扫描全表去统计所有关注了用户A的用户数量,所以下面的这个表结构设计也存在一定的性能问题。这里也引出一个思路,被关注者需要以某种方式添加索引。  针对上面的表结构有三种优化方案,第一种是新建另一张表,里面保存某个用户和所有关注他的用户。第二种解决方案就是在同一张表中也存储某个用户和所有关注他的用户的信息,并从Row Key中区分开来,比如:Row key为Jame_001_following的这行保存着所有Jame关注的人的信息,而Row_Key为Jame_001_followed的这行保存着所有关注Jame的人的信息。
针对上面的表结构有三种优化方案,第一种是新建另一张表,里面保存某个用户和所有关注他的用户。第二种解决方案就是在同一张表中也存储某个用户和所有关注他的用户的信息,并从Row Key中区分开来,比如:Row key为Jame_001_following的这行保存着所有Jame关注的人的信息,而Row_Key为Jame_001_followed的这行保存着所有关注Jame的人的信息。
最后一种优化方案就是,如下图,将Row Key设计成“followerID+followedID”的形式,比如:“Jame+Emma”,这里的Row Key值就代表着Jame关注了Emma(其实这里应该是“Jame的ID+Emma的ID”,只是为了解释方便而直接用名字),同时包含了关注者和被关注者两个信息;还需要注意的一点就是列族的名字被设计成只有一个字母f,这样设计的好处就是减少了HBase对数据的I/O操作压力,同时减少了返回到客户端的数据字节,提高响应速度,因为每一个返回给客户端的KeyValue对象都会包含列族名字。
同时将被关注人的用户名称也保存在了表中作为Column Qualifier,这样做的好处就是节省了去用户表查找用户名的资源。在这种表结构设计下,“用户A取消关注某个用户B”,“用户A有没有关注用户B?”的业务处理就会变得简单高效。 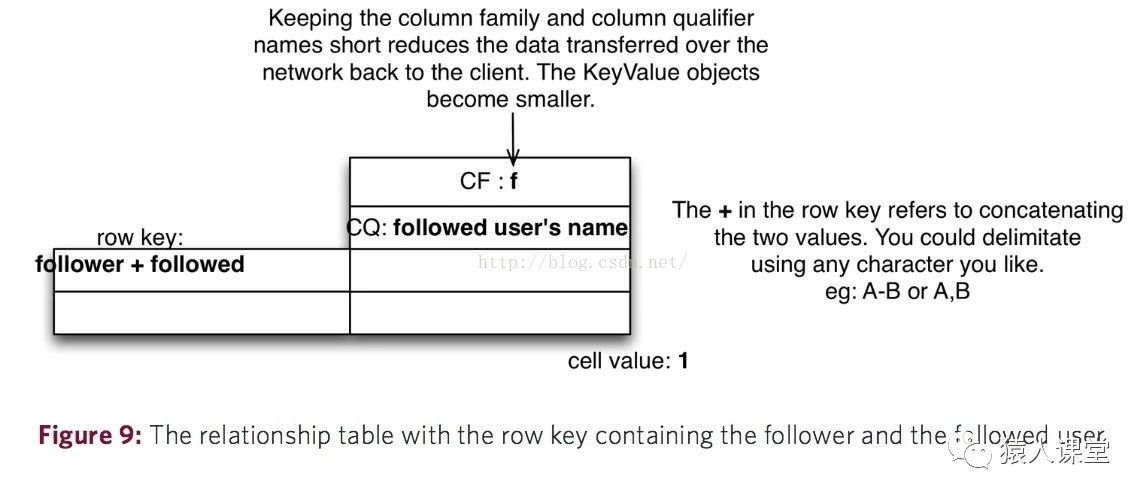 还有一个需要注意的问题,就是在实际的生产环境中,还需要将Row Key使用MD5加密,一方面是使Row Key的长度都一致,能提高数据的存取性能。这方面的优化不在本文的讨论范围内。
还有一个需要注意的问题,就是在实际的生产环境中,还需要将Row Key使用MD5加密,一方面是使Row Key的长度都一致,能提高数据的存取性能。这方面的优化不在本文的讨论范围内。 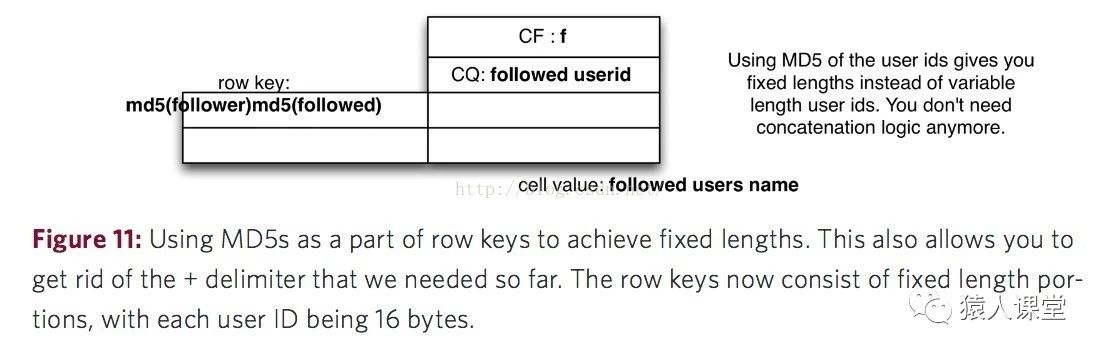 总结: 整篇文章概述了HBase的数据模型和基本的表设计思路。下面是HBase一些关键特性的总结: 1. Row Key是HBase表结构设计中很重要的一环,它设计的好坏直接影响程序和HBase交互的效率和数据存储的性能。 2. Base的表结构比传统关系型数据库更灵活,你能存储任何二进制数据在表中,而且无关数据类型。 3. 在相同的列族中所有数据都具有相同的接入模式 4. 主要是通过Row Key来建立索引 5. 以纵向扩张为主设计的表结构能快速简单的获取数据,但牺牲了一定的原子性,就比如上文中最后一种表结构;而以横向扩张为主设计的表结构,也就是列族中有很多列,比如上文中第一种表结构,能在行里面保持一定的原子性。 6. HBase并不支持事务,所有尽量在一次API请求操作中获取到结果 7. 对Row Key的Hash优化能获得固定长度的Row Key并使数据分布更加均匀一些,而不是集中在一台服务器上,但是也牺牲了一定的数据排序和读取性能。 8. 可以利用列标识(Column Qualifier)来存储数据。 9. 列标识(Column Qualifier)名字的长度和列族名字的长度都会影响I/O的读写性能和发送给客户端的数据量,所以它们的命名应该简洁!
总结: 整篇文章概述了HBase的数据模型和基本的表设计思路。下面是HBase一些关键特性的总结: 1. Row Key是HBase表结构设计中很重要的一环,它设计的好坏直接影响程序和HBase交互的效率和数据存储的性能。 2. Base的表结构比传统关系型数据库更灵活,你能存储任何二进制数据在表中,而且无关数据类型。 3. 在相同的列族中所有数据都具有相同的接入模式 4. 主要是通过Row Key来建立索引 5. 以纵向扩张为主设计的表结构能快速简单的获取数据,但牺牲了一定的原子性,就比如上文中最后一种表结构;而以横向扩张为主设计的表结构,也就是列族中有很多列,比如上文中第一种表结构,能在行里面保持一定的原子性。 6. HBase并不支持事务,所有尽量在一次API请求操作中获取到结果 7. 对Row Key的Hash优化能获得固定长度的Row Key并使数据分布更加均匀一些,而不是集中在一台服务器上,但是也牺牲了一定的数据排序和读取性能。 8. 可以利用列标识(Column Qualifier)来存储数据。 9. 列标识(Column Qualifier)名字的长度和列族名字的长度都会影响I/O的读写性能和发送给客户端的数据量,所以它们的命名应该简洁!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
