
每天更新一题 让大家在休息时间可以轻松学习!
下面是关于SQL的题目,每日更新~
(PS:大家要看清题号回答哦~需要答案的同学可以在下方留言题号,第一时间回复答案)
有如下一张表Person,其中ID是自增长
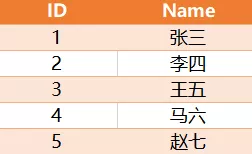
求解,如何将相邻两条记录的Name进行位置交换?预期结果如下:
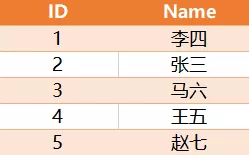
其中,最后一条记录如果是奇数则不交换。
考点:case when的灵活运用
从 survey_log 表中获得回答率最高的问题, survey_log 表包含这些列:uid, action, question_id, answer_id, q_num, timestamp。uid 表示用户 id;action 有以下几种值:"show","answer","skip";当 action 值为 "answer" 时 answer_id 非空, 而 action 值为 "show" 或者 "skip" 时 answer_id 为空;q_num 表示当前会话中问题的编号。请编写SQL查询来找到具有最高回答率的问题。示例:
输入:
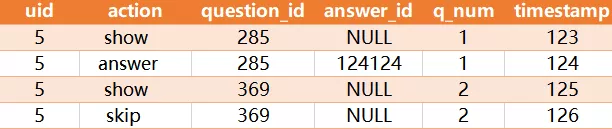
输出:

解释:
问题285的回答率为 1/1,而问题369回答率为 0/1,因此输出285。
注意: 回答率最高的含义是:同一问题编号中回答数占显示数的比例。对于每道题来说,不管被回答多少次,题目数量就是1,也就是分母是1,
那么将题目转化为求每道题被回答的次数,也就是answer_id不为NULL的次数
求解以下日期
每月的第一天,最后一天
上月的第一天,最后一天
每周的第一天,最后一天
每年的第一天,最后一天
要求使用系统日期,例如:
当前是2019-11-30 14:00:00:000
每月的第一天应该为 2019-11-01,最后一天应该为2019-06-30
上月的第一天应该为 2019-10-01,最后一天应该为2019-10-31
每周的第一天应该为 2019-11-25/2019-11-24,最后一天应该为2019-12-01/2019-11-30
在 微信 或者 QQ这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
表 request_accepted 存储了所有好友申请通过的数据记录,其中, requester_id 和 accepter_id 都是用户的编号。
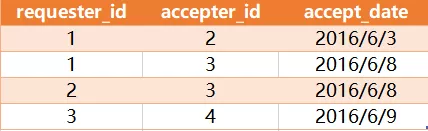
写一个查询语句,求出谁拥有最多的好友和他拥有的好友数目。对于上面的样例数据,结果为:

注意:保证拥有最多好友数目的只有 1 个人。好友申请只会被接受一次,所以不会有 requester_id 和 accepter_id 值都相同的重复记录。
解释:编号为 '3' 的人是编号为 '1','2' 和 '4' 的好友,所以他总共有 3 个好友,比其他人都多。
编写一个SQL查询,报告在首次登录后第二天再次登录的玩家的分数,四舍五入到小数点后两位。换句话说,你需要从首次登录日期开始计算至少连续两天登录的玩家数,把这个数字除以玩家总数。
查询结果格式如下所示:
Activity 表:
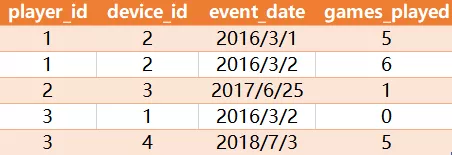
Result 表:
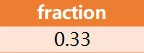
解释:只有ID为1的玩家在第一天登录后才重新登录,所以答案是1/3=0.33
有如下一张表Orders
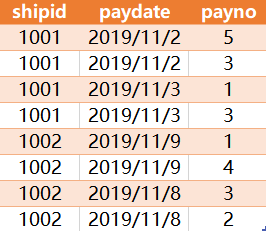
查询出每个发货单号(shipid),最早付款时间(paydate)和最小付款单号(payno)
结果如下:

考点:聚合函数和关联的灵活使用
表 point 保存了一些点在 X 轴上的坐标,这些坐标都是整数。
写一个查询语句,找到这些点中最近两个点之间的距离。
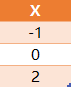
最近距离显然是 '1' ,是点 '-1' 和 '0' 之间的距离。所以输出应该如下:

注意:每个点都与其他点坐标不同,表 table 不会有重复坐标出现。
考点:题目看似简单,谨防陷阱
怎么把下面的表(tab)
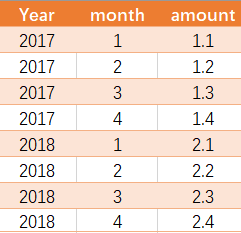
查成这样1个结果

考点:行列转换
有如下一组数据
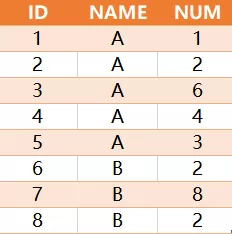
求出NAME中每组累加/每组总数的比例大于0.6的ID和NAME
预期的结果应该为
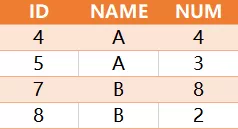
解释:从题目意思可以看出A组的总数为16,从ID为1到5分别累加后的结果分别为1,3,9,13,16,只有13和16除以总数16才大于0.6,所以返回的结果ID为4和5,同样B组为7和8
有如下一张
Activity 表:
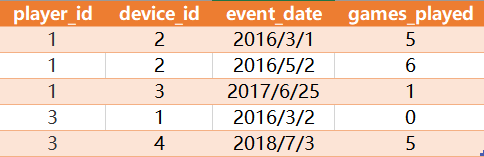
其中games_played是玩家登陆玩的游戏数量,
查询每个玩家每天累计玩的游戏数量有多少?结果如下:
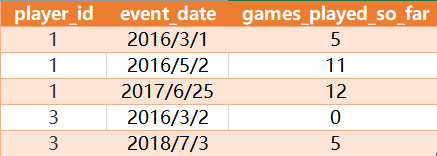
解释:玩家1第一次玩了5个,所以是5,第二次是6个,所以累计就是5+6=11,
第三次是1个,累计就是5+6+1=12
玩家2类似
写一条 SQL 查询语句,从 Customer 表中查询购买了 Product 表中所有产品的客户的 id。示例:Customer 表:
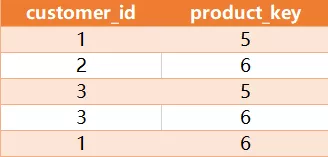
Product 表:
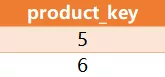
Result 表:

购买了所有产品(5 和 6)的客户的 id 是 1 和 3 。
有如下几张表:
Student
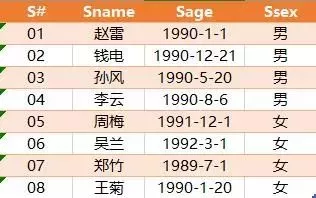
Course
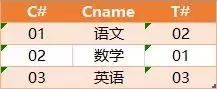
SC
查询"01 "课程比" 02 "课程成绩高的学生的信息及课程分数?
P.S. 题目较简单,希望大家能动手练习一下,锻炼自己逻辑思维能力。
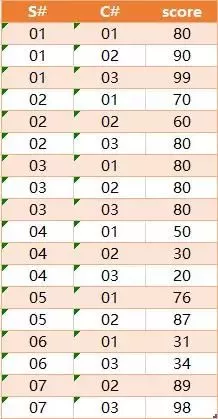
有一张成绩表SC,表结构为SC(StuID,CID,Course),分部对应是学生ID,课程ID和学生成绩,有如下测试数据
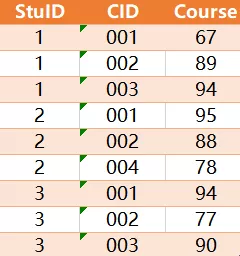
查询出既学过'001'课程,也学过'003'号课程的学生ID 预期结果为
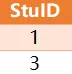
表 orders 定义如下:order_id(订单编号),customer_id(客户编号),order_date(下单日期)
有如下几条记录:
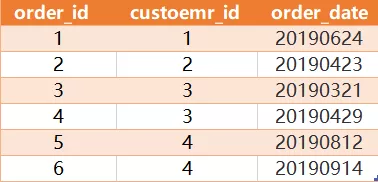
在表 orders 中找到订单数最多客户对应的 customer_id 。
预计的输出结果:
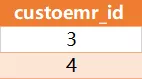
考点:聚合函数的灵活使用
用一条SQL 语句 查询出每门课都大于80 分的学生姓名,表格样式及数据如下:
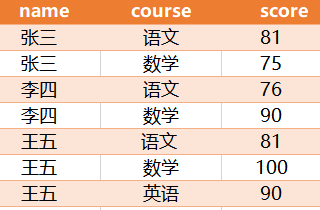
结果为:

请至少使用两种方法作答
给定一个表 tree,id 是树节点的编号, p_id 是它父节点的 id 。
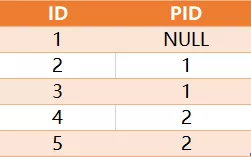
树中每个节点属于以下三种类型之一:叶子:如果这个节点没有任何孩子节点。根:如果这个节点是整棵树的根,即没有父节点。内部节点:如果这个节点既不是叶子节点也不是根节点。
写一个查询语句,输出所有节点的编号和节点的类型,并将结果按照节点编号排序。上面样例的结果为:
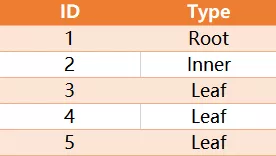
解释:
节点 '1' 是根节点,因为它的父节点是 NULL ,同时它有孩子节点 '2' 和 '3' 。节点 '2' 是内部节点,因为它有父节点 '1' ,也有孩子节点 '4' 和 '5' 。节点 '3', '4' 和 '5' 都是叶子节点,因为它们都有父节点同时没有孩子节点。注意 如果树中只有一个节点,你只需要输出它的根属性。
考点:自连接的灵活使用
有如下两张表
Project 表:
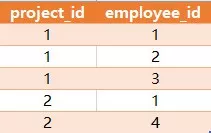
Employee 表:

查询出每个项目中经验最丰富(experience_years最大)的员工,返回的结果如下:
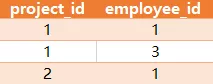
说明:员工1和3是project_id为1中exprerience_years最丰富的,而project_id为2的项目,员工id为1的是exprerience_years最丰富
有如下两张表
Books 表:

Orders 表:
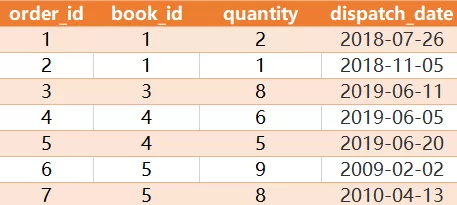
编写一个SQL查询,要求去年销售少于10本的书籍,不包括从今天起1个月内可供使用的书籍。假设今天是2019-06-23。
结果表:
从一张考勤表TAB中找出员工每天的上班,下班打卡的具体时间?
考勤表中相关字段如下:ID,NAME,NO,TIME
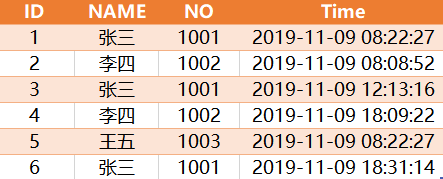
其中ID是主键,NAME为员工姓名,NO为工号,TIME为打卡时间
返回的结果如下:

考点:CONVERT转换函数
编写一个 SQL 查询,获取Employee 表中第二高的薪水(Salary) 。
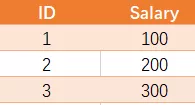
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
结果如下:

考点:LIMIT/TOP/ROW_NUMBER()的运用
有一张成绩表SC,表结构为SC(StuID,CID,Course),分部对应是学生ID,课程ID和学生成绩,有如下测试数据
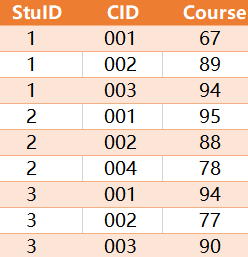
查询出'001'课程分数大于'002'课程分数的学生学号
预期结果为
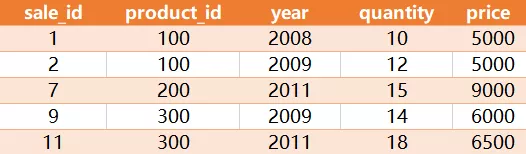
编写一个SQL查询,用于选择每种销售产品的第一年的产品ID、年份、数量和价格。查询结果格式如下所示:Sales table:
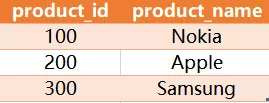
Product table:
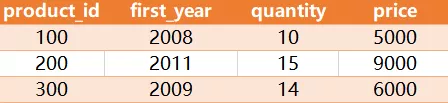
返回如下结果
Result table:
Employee 表包含所有员工。Employee 表有三列:员工Id,公司名和薪水。
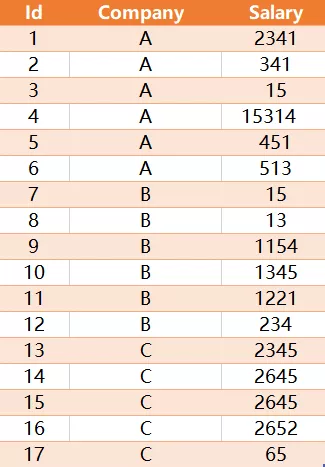
请编写SQL查询来查找每个公司的薪水中位数。挑战点:你是否可以在不使用任何内置的SQL函数的情况下解决此问题。
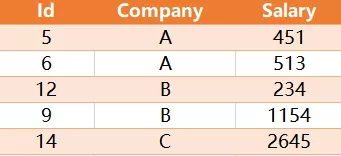
按 company 分组排序,记为 rk
计算各 company 的记录数除以2,记为 cnt
连接结果
找出符合中位数要求的记录
有 2 个要点:分组排序通过两个变量完成,注意 @com 的更新顺序要在 @rk 之后
按示例,若记录数为奇数,取一条,否则取两条,如记录数为7,则第4名是中位数,
记录数为6,则第3,4名是中位数。由于 cnt = 计数除以2,则对应序号可直接用 in (cnt+0.5,cnt+1,cnt) 来表达
给如下两个表,写一个查询语句,求出在每一个工资发放日,每个部门的平均工资与公司的平均工资的比较结果 (高 / 低 / 相同)。表:salary
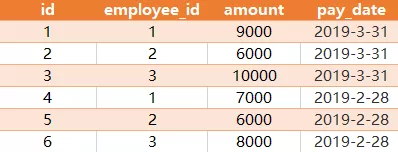
employee_id 字段是表 employee 中 employee_id 字段的外键。
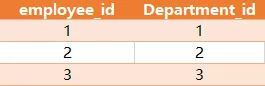
对于如上样例数据,结果为:
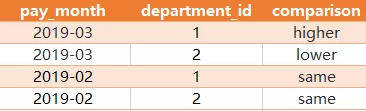
解释:
在三月,公司的平均工资是 (9000+6000+10000)/3 = 8333.33... 由于部门 '1' 里只有一个 employee_id 为 '1' 的员工,所以部门 '1' 的平均工资就是此人的工资 9000 。因为 9000 > 8333.33 ,所以比较结果是 'higher'。第二个部门的平均工资为 employee_id 为 '2' 和 '3' 两个人的平均工资,为 (6000+10000)/2=8000 。因为 8000 < 8333.33 ,所以比较结果是 'lower' 。在二月用同样的公式求平均工资并比较,比较结果为 'same' ,因为部门 '1' 和部门 '2' 的平均工资与公司的平均工资相同,都是 7000 。
有如下两张表
表: Candidate(候选人)
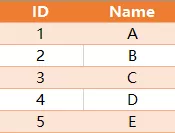
表: Vote(选票)
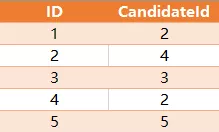
id 是自动递增的主键,
CandidateId 是 Candidate 表中的 id.
请编写 sql 语句来找到当选者的名字,即选票最多的候选者。上面的例子将返回当选者 B,因为他获得了2票,其他人获得了1票或0票。

注意:
你可以假设没有平局,换言之,最多只有一位当选者。
Numbers 表保存数字的值及其频率。
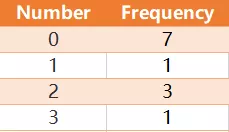
在此表中,数字为 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3,所以中位数是 (0 + 0) / 2 = 0。

请编写一个查询来查找所有数字的中位数并将结果命名为 median 。注意:什么是中位数?当一串数字是奇数个时,例如8,3,5,1,4。我们按顺序排列后为:1,3,4,5,8。那么4就是中位数 当一串数字为偶数个时,例如8,3,5,1,4,2。我们按顺序排列后为:1,2,3,4,5,8。那么(3+4)/2=3.5就是中位数。
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
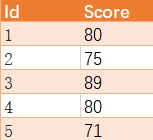
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
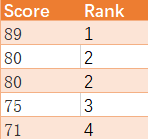
给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
例如,根据上述给定的 Weather 表格,返回如下 Id:
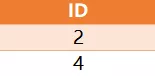
有如下一道面试题,表名Course,见下图
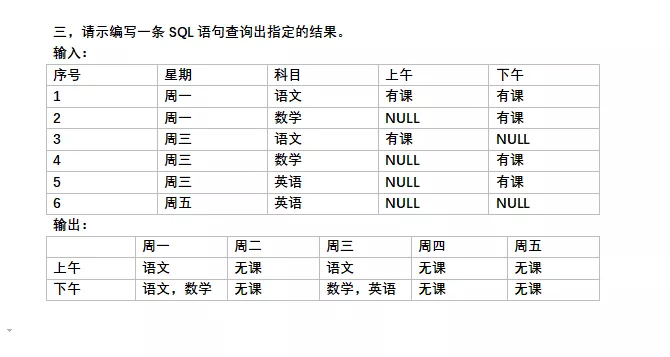
请写出具体的查询语句
有如下一张表City,
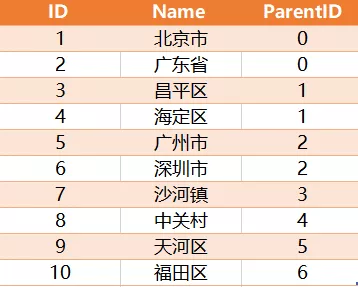
希望得到如下结果
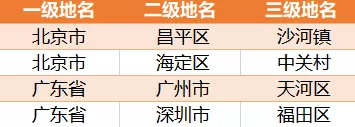
该如何写这个查询?
有如下一张表Person,其中ID是自增长
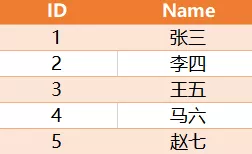
求解,如何将相邻两条记录的Name进行位置交换?预期结果如下:
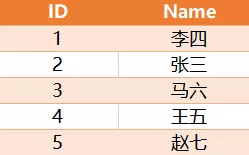
其中,最后一条记录如果是奇数则不交换。
有7个会议室,每个会议室每天都有人开会,某一天的开会时间如下:
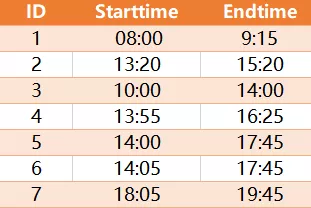
查询出开会时间有重叠的是哪几个会议室?上面预期结果是
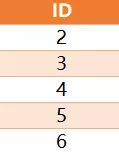
你能写一个 SQL 查询语句,找到只出现过一次的数字中,最大的一个数字吗?下面是测试数据
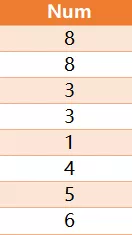
对于上面给出的样例数据,你的查询语句应该返回如下结果:
有如下一张表
ActorDirector 表:
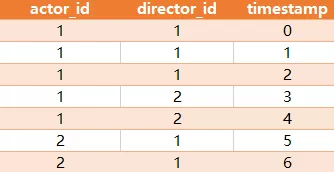
写一条SQL查询语句获取合作过至少三次的演员和导演的 id 对 (actor_id, director_id)
结果:

唯一的 id 对是 (1, 1),他们恰好合作了 3 次。
有如下两张表
Project 表:
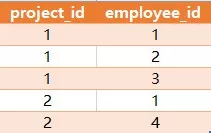
Employee 表:
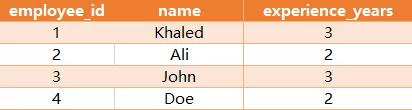
查询出每个项目中经验最丰富(experience_years最大)的员工,返回的结果如下:
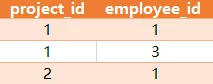
说明:员工1和3是project_id为1中exprerience_years最丰富的,
而project_id为2的项目,员工id为1的是exprerience_years最丰富
有如下ABC三列和几组数据
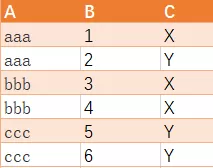
想得到如下结果
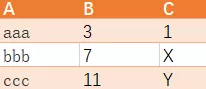
该如何写查询?
提示:可以使用聚合函数或者lag函数来求解
几个朋友来到电影院的售票处,准备预约连续空余座位。
你能利用表 cinema ,帮他们写一个查询语句,获取所有空余座位,并将它们按照 seat_id 排序后返回吗?
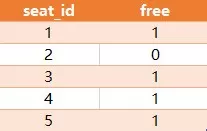
对于如上样例,你的查询语句应该返回如下结果。
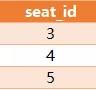
注意:
seat_id 字段是一个自增的整数,free 字段是布尔类型('1' 表示空余, '0' 表示已被占据)。
连续空余座位的定义是大于等于 2 个连续空余的座位。
有如下一张记录表,如何查询出每隔15分钟的记录数
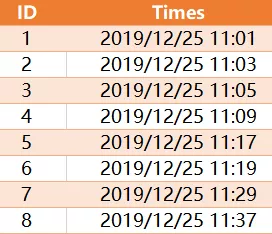
预期结果如下:

考点:日期函数的灵活运用
编写一个 SQL 查询,查找所有至少连续出现两次的数字。
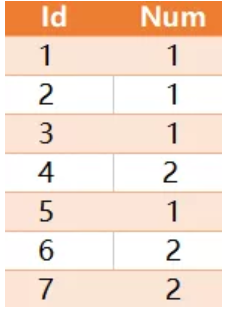
例如,给定上面的 Logs 表, 1 和2是连续出现至少两次的数字。
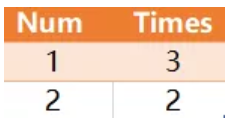
考点:连续记录问题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
38题 select * , case when id%2 =1 and name_2 is not null then name_2 when id%2 =0 then name_4 else name_id end as name_3 from ( select *,Lead(name_id) over(order by id) as name_2 ,Lag(name_id) over(order by id) as name_4 from test )a
insert overwrite TABLE q11 values('1','monday','chinese','Y','Y'), ('2','tuesday','math',NULL,'Y'), ('3','wednesday','chinese','Y',NULL), ('4','wednesday','math',NULL,'Y'), ('5','wednesday','english',NULL,'Y'), ('6','friday','english',NULL,NULL);
with q11_temp as ( SELECT t,str_to_map(concat_ws('&',collect_set(concat_ws('=',day,subj))),'&','=') as mp from ( SELECT day,t,concat_ws(',',collect_set(subj)) subj from ( SELECT day,'morning' t,if(morning='Y',subject,morning) subj FROM q11 union ALL SELECT day,'afternoon' t,if(afternoon='Y',subject,afternoon) subj FROM q11 ) a WHERE subj IS NOT NULL GROUP BY day,t
) b GROUP BY t
)
select t,if(array_contains(map_keys(mp),'monday'),mp['monday'],'noclass'), if(array_contains(map_keys(mp),'tuesday'),mp['tuesday'],'noclass'), if(array_contains(map_keys(mp),'wednesday'),mp['wednesday'],'noclass'), if(array_contains(map_keys(mp),'thursday'),mp['thursday'],'noclass'), if(array_contains(map_keys(mp),'friday'),mp['friday'],'noclass'), if(array_contains(map_keys(mp),'saturday'),mp['saturday'],'noclass'), if(array_contains(map_keys(mp),'sunday'),mp['sunday'],'noclass') from q11_temp
---11. 如果是oracle,想到的就是pivot行专列,listagg合并多个到一个字段内
select aaa, nvl(周一, '无课') as 周一, nvl(周二, '无课') 周二, nvl(周三, '无课') 周三, nvl(周四, '无课') 周四, nvl(周五, '无课') 周五 from (select '上午' as aaa, a.week, a.class_name from lx_11 a where a.morning = '有课' union all select '下午' as aaa, a.week, a.class_name from lx_11 a where a.afternoon = '有课') pivot(listagg( class_name, ',') within group(order by class_name) for week in('周一' as 周一, '周二' AS 周二, '周三' AS 周三, '周四' AS 周四, '周五' AS 周五));
--12
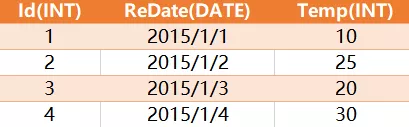
select * from lx_12 a, lx_12 b where a.redate = b.redate -1 and a.temp < b.temp
--13
--如果是Oracle就是判断row_number()、rank()、dense_rank() 的区别
select a.score, dense_rank() over(partition by a.aa order by a.score desc) from (select '1' as aa, score from lx_13) a
33
SELECT shipid, paydate, payno
FROM (
SELECT *,
row_number() OVER (PARTITION BY shipid ORDER BY paydate) AS rn_dt,
row_number() OVER (PARTITION BY shipid ORDER BY payno) AS rn_no
FROM orders
)
WHERE rn_dt = 1
AND rn_no = 1
胜哥
作者出的题目建表的sql能提供下吗?
select sum(count) as num,id from (
select count(*) count,requester_id as id from request_accepted GROUP BY requester_id
UNION
select count(*) count ,accepter_id as id from request_accepted GROUP BY accepter_id
)t
GROUP BY id
ORDER BY num desc
limit 1
1.初始化:
CREATE TABLE `Orders` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`shop_id` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
`pay_date` datetime DEFAULT NULL,
`pay_no` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (1, '1001', '2020-01-11 16:43:25', 5);
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (2, '1001', '2020-01-10 16:43:57', 3);
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (3, '1002', '2020-01-17 16:44:09', 4);
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (4, '1002', '2020-01-11 16:44:24', 2);
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (5, '1002', '2020-01-11 16:44:24', 1);
INSERT INTO `Orders`(`id`, `shop_id`, `pay_date`, `pay_no`) VALUES (6, '1002', '2020-01-12 16:44:24', 0);
2.SQL
方法1:GROUP_CONCAT实现(数据库版本[5.7.16])
select * from Orders
where id in (
select SUBSTRING_INDEX(GROUP_CONCAT(id ORDER BY pay_date,pay_no),',',1) from Orders
GROUP BY shop_id
)
方法2:子查询实现(数据库版本[5.6.16])
select t.* from (
select * from Orders ORDER BY pay_date ,pay_no
)t
GROUP BY t.shop_id;
方法2有可能是不行的,不知道是数据库版本问题还是哪里设置没有
3.注意: GROUP_CONCAT有长度限制,记录过多需要注意设置以下配置 SET @@global.group_concat_max_len=数字
30题:select player_id,event_date,sum(games_palyed)over(partition by event_date)as games_palyed_so_far from Activity
32. SELECT year, sum(case when mounth = 1 then amount else '' end), sum(case when mounth = 2 then amount else '' end), sum(case when mounth = 3 then amount else '' end), sum(case when mounth = 4 then amount else '' end) FROM t32 GROUP BY year ;
31 select id,name,num from (select id,name,num,sum(num) over(partition by name order by id asc) as sum1,sum(num) over(partition by name) as sum2 from q31) as t1 where sum1/sum2>0.6 group by id,name,num;
#hive
1.
CREATE table IF NOT EXISTS q1( id STRING, num STRING );
insert into q1 values(1,1),(2,1),(3,1),(4,2),(5,1),(6,2),(7,2);
SELECT num,count(1) c from (SELECT id,num,row_number()over(PARTITION BY num ORDER BY id) r, id-row_number()over(PARTITION BY num ORDER BY id) bz FROM q1 ) a GROUP BY num,bz having c>1
2.
CREATE table IF NOT EXISTS q2( id STRING, time STRING );
insert overwrite table q2 values(1,'2019/12/25 11:01'),(2,'2019/12/25 11:03'),(3,'2019/12/25 11:05'),(4,'2019/12/25 11:09'),(5,'2019/12/25 11:17'),(6,'2019/12/25 11:19'),(7,'2019/12/25 11:29'),(8,'2019/12/25 11:37');
SELECT from_unixtime(floor(unix_timestamp(time,'yyyy/MM/dd hh:mm')/60/15)*60*15,'yyyy/MM/dd hh:mm'),count(1) FROM q2 GROUP BY floor(unix_timestamp(time,'yyyy/MM/dd hh:mm')/60/15);
3.同第一题
4. 对于相同的A列,C列相同则取该值,不同则置为1?
CREATE TABLE q3( a STRING, b STRING, c STRING );
insert into q3 values('aaa','1','x'),('aaa','2','y'), ('bbb','3','x'),('bbb','4','x'), ('ccc','5','y'),('ccc','6','y');
select t.a,t.b+t2.b,if(t.c=t2.c,t.c,1) from( SELECT a,b,c FROM q3 where b%2=1 ) t left join (select a,b,c from q3 ) t2 where t.a=t2.a and t.b+1=t2.b
5.
rank(),dense_rank()
select project_id,employee_id,dense_rank() over(partition by project_id,employee_id order by experience_years desc) rk from (select project_id,employee_id from project) p left join (select employee_id,experience_years from employee ) e on p.employee_id=e.employee_id where rk=1
6.
7.
8.
create table if not exists q8( id string, starttime string, endtiem string);
insert overwrite table q8 values(1,'08:00','09:15'),(2,'13:20','15:20'),(3,'10:00','14:00'),(4,'13:55','16:25'),(5,'14:00','17:45'),(6,'14:05','17:45'),(7,'18:05','19:45');
SELECT DISTINCT bid FROM (SELECT id aid,starttime ast,endtiem aet from q8) a LEFT JOIN (SELECT id bid,starttime bst,endtiem bet from q8) b where (aid<>bid and unix_timestamp(ast,'hh:mm')<unix_timestamp(bst,'hh:mm') and unix_timestamp(aet,'hh:mm')>unix_timestamp(bst,'hh:mm')) or (aid<>bid and unix_timestamp(ast,'hh:mm')<unix_timestamp(bet,'hh:mm') and unix_timestamp(aet,'hh:mm')>unix_timestamp(bst,'hh:mm'))
9.
CREATE TABLE q5( id int, name STRING );
INSERT INTO q5 VALUES(1,'张三'),(2,'李四'),(3,'王五'),(4,'马六'),(5,'赵七');
SELECT * from (SELECT id,lag(name,1,name)over() FROM q5) a WHERE a.id%2=1 UNION ALL SELECT * from (SELECT id,lead(name,1,name)over() FROM q5) b WHERE b.id%2=0
10.
25题: SELECT * FROM students_score t1 WHERE NOT EXISTS (SELECT 1 FROM students_score t WHERE t1.NAME = t.NAME AND t.SCORE < 80 GROUP BY NAME )
