
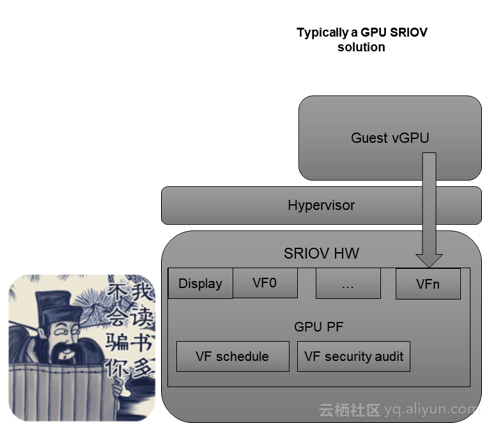
GPU SRIOV原理
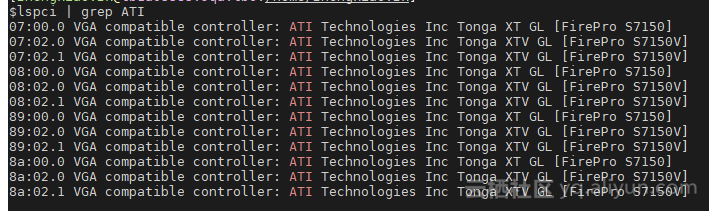
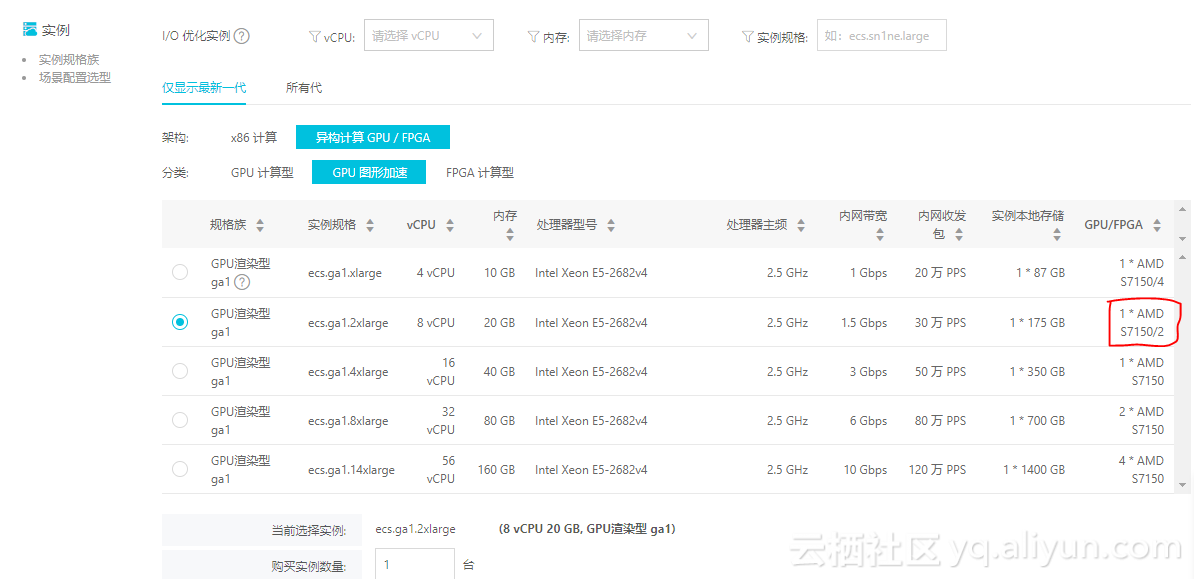
谈起GPU SRIOV那么这个世界上就只有两款产品:S7150和MI25。都出自AMD,当然AMD的产品规划应该是早已安排到几年以后了,未来将看到更多的GPU SRIOV产品的升级换代。S7150针对的是图形渲染的客户群体,而MI25则针对机器学习,AI的用户群体。本文以围绕S7150为主。因为S7150的SRIOV实例在各大公有云市场上都有售卖,而MI25目前看来尚未普及(受限于AMD ROCm生态环境的完备性)。
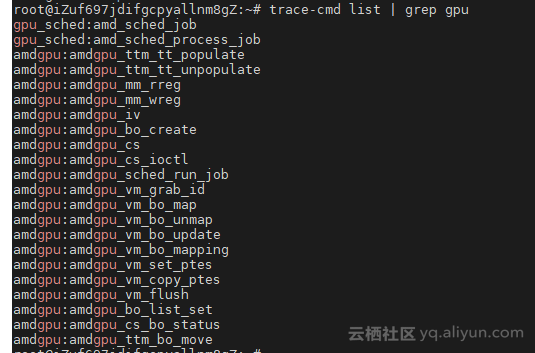




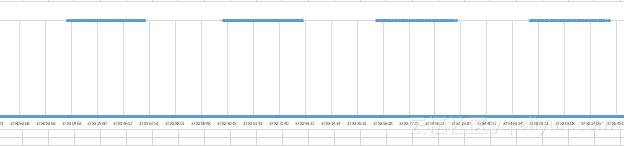
事件时间ns | 间隔 | |
1437.803888 1437.810159 | 6.271ms | 无GPU活动 |
1437.816378 1437.822720 | 6.342ms | 无GPU活动 |
1437.829105 1437.835127 | 6.022ms | 无GPU活动 |
1437.841587 1437.847506 | 5.919ms | 无GPU活动 |
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
