
为什么会出现数据库新增10条数据,但是redis却只写入了一个id这种现象啊。数据库写入的数据没有重复。
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
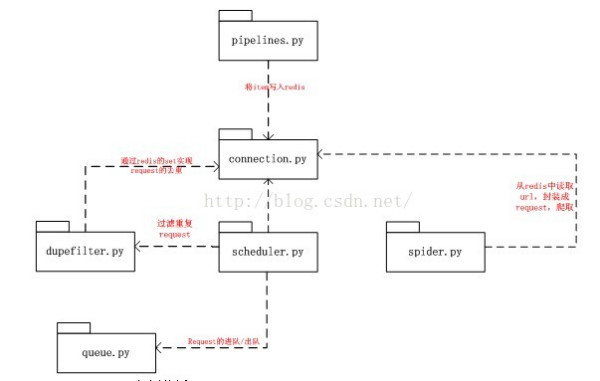
scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式。分别是由模块scheduler和模块pipelines实现。 一、Scrapy-redis各个组件介绍 (I) connection.py 负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块。 (II) dupefilter.py 负责执行requst的去重,实现的很有技巧性,使用redis的set数据结构。但是注意scheduler并不使用其中用于在这个模块中实现的dupefilter键做request的调度,而是使用queue.py模块中实现的queue。 当request不重复时,将其存入到queue中,调度时将其弹出。 (III)queue.py 其作用如II所述,但是这里实现了三种方式的queue: FIFO的SpiderQueue,SpiderPriorityQueue,以及LIFI的SpiderStack。默认使用的是第二中,这也就是出现之前文章中所分析情况的原因(链接)。 (IV)pipelines.py 这是是用来实现分布式处理的作用。它将Item存储在redis中以实现分布式处理。 另外可以发现,同样是编写pipelines,在这里的编码实现不同于文章(链接:)中所分析的情况,由于在这里需要读取配置,所以就用到了from_crawler()函数。 (V)scheduler.py 此扩展是对scrapy中自带的scheduler的替代(在settings的SCHEDULER变量中指出),正是利用此扩展实现crawler的分布式调度。其利用的数据结构来自于queue中实现的数据结构。 scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式就是由模块scheduler和模块pipelines实现。上述其它模块作为为二者辅助的功能模块。 (VI)spider.py 设计的这个spider从redis中读取要爬的url,然后执行爬取,若爬取过程中返回更多的url,那么继续进行直至所有的request完成。之后继续从redis中读取url,循环这个过程。 二、组件之间的关系
 三、scrapy-redis实例分析 (1) spiders/ ebay_redis.py classEbayCrawler(RedisMixin,CrawlSpider): """Spiderthat reads urls from redis queue (mycrawler:start_urls).""" name = 'ebay_redis' redis_key = ' ebay_redis:start_urls' rules = ( # follow all links # Rule(SgmlLinkExtractor(),callback='parse_page', follow=True), Rule(sle(allow=('[^\s]+/itm/', )), callback='parse_item'), ) #该方法是最关键的方法,该方法名以下划线开头,建立了和redis的关系 def _set_crawler(self, crawler): CrawlSpider._set_crawler(self, crawler) RedisMixin.setup_redis(self) # 解析sku页面 defparse_item(self,response): sel =Selector(response) base_url =get_base_url(response) item = EbayphoneItem() print base_url item['baseurl'] =[base_url] item['goodsname'] =sel.xpath("//h1[@id='itemTitle']/text()").extract() return item 该类继承了RedisMixin(scrapy_redis/spiders.py中的一个类)和CrawlSpider,加载配置文件的各项,建立和redis的关联,同时进行抓取后的解析。关键方法为_set_crawler(self, crawler),关键属性是redis_key,该key如果没有初始化则默认为spider.name:start_urls _set_crawler()方法是如何被调用的: scrapy/crawl.py/Crawler: crawl() -> scrapy/crawl.py/Crawler:create_spider () -> CrawlSpider:from_crawler() –> scrapy/spiders/Spider: from_crawler() -> ebay_redis.py :set_crawler() (2) setting.py SPIDER_MODULES= ['example.spiders'] NEWSPIDER_MODULE= 'example.spiders' ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline':300, #通过配置下面该项RedisPipeline'会将item写入key为 #spider.name:items的redis的list中,供后面的分布式处理item 'scrapy_redis.pipelines.RedisPipeline':400, } SCHEDULER= "scrapy_redis.scheduler.Scheduler" #不清理redisqueues, 允许暂停或重启crawls SCHEDULER_PERSIST= True SCHEDULER_QUEUE_CLASS= 'scrapy_redis.queue.SpiderPriorityQueue' #该项仅对queueclass is SpiderQueue or SpiderStack生效,阻止spider被关闭的最大空闲时间 SCHEDULER_IDLE_BEFORE_CLOSE= 10 #连接redis使用 REDIS_HOST = '123.56.184.53' REDIS_PORT= 6379 (3) process_items.py: defmain(): pool =redis.ConnectionPool(host='123.56.184.53', port=6379, db=0) r = redis.Redis(connection_pool=pool) while True: # process queue as FIFO, change
三、scrapy-redis实例分析 (1) spiders/ ebay_redis.py classEbayCrawler(RedisMixin,CrawlSpider): """Spiderthat reads urls from redis queue (mycrawler:start_urls).""" name = 'ebay_redis' redis_key = ' ebay_redis:start_urls' rules = ( # follow all links # Rule(SgmlLinkExtractor(),callback='parse_page', follow=True), Rule(sle(allow=('[^\s]+/itm/', )), callback='parse_item'), ) #该方法是最关键的方法,该方法名以下划线开头,建立了和redis的关系 def _set_crawler(self, crawler): CrawlSpider._set_crawler(self, crawler) RedisMixin.setup_redis(self) # 解析sku页面 defparse_item(self,response): sel =Selector(response) base_url =get_base_url(response) item = EbayphoneItem() print base_url item['baseurl'] =[base_url] item['goodsname'] =sel.xpath("//h1[@id='itemTitle']/text()").extract() return item 该类继承了RedisMixin(scrapy_redis/spiders.py中的一个类)和CrawlSpider,加载配置文件的各项,建立和redis的关联,同时进行抓取后的解析。关键方法为_set_crawler(self, crawler),关键属性是redis_key,该key如果没有初始化则默认为spider.name:start_urls _set_crawler()方法是如何被调用的: scrapy/crawl.py/Crawler: crawl() -> scrapy/crawl.py/Crawler:create_spider () -> CrawlSpider:from_crawler() –> scrapy/spiders/Spider: from_crawler() -> ebay_redis.py :set_crawler() (2) setting.py SPIDER_MODULES= ['example.spiders'] NEWSPIDER_MODULE= 'example.spiders' ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline':300, #通过配置下面该项RedisPipeline'会将item写入key为 #spider.name:items的redis的list中,供后面的分布式处理item 'scrapy_redis.pipelines.RedisPipeline':400, } SCHEDULER= "scrapy_redis.scheduler.Scheduler" #不清理redisqueues, 允许暂停或重启crawls SCHEDULER_PERSIST= True SCHEDULER_QUEUE_CLASS= 'scrapy_redis.queue.SpiderPriorityQueue' #该项仅对queueclass is SpiderQueue or SpiderStack生效,阻止spider被关闭的最大空闲时间 SCHEDULER_IDLE_BEFORE_CLOSE= 10 #连接redis使用 REDIS_HOST = '123.56.184.53' REDIS_PORT= 6379 (3) process_items.py: defmain(): pool =redis.ConnectionPool(host='123.56.184.53', port=6379, db=0) r = redis.Redis(connection_pool=pool) while True: # process queue as FIFO, change blpopto brpop to process as LIFO source, data =r.blpop(["ebay_redis:items"]) item = json.loads(data) try: print u"Processing: %(name)s<%(link)s>" % item except KeyError: print u"Error procesing:%r" % item if__name == 'main': main() 该模块是从redis对应的list中取出item,进行处理,可以运行多个进程分布式处理items (4)执行过程如下: 首先在redis服务器端打开redis服务: ./redis-server 其次执行 ./redis-cli lpush ebaycrawler:start_urls http://www.ebay.com/sch/Cell-Phones-Smartphones-/9355/i.html 然后运行爬虫: scrapy runspiderebay_redis.py 可以执行多个爬虫,同时对ebay_redis:start_urls中的url进行分布式爬取,爬取后的结果都存入了ebay_redis:items的list中,供后续再次处理 最后可以查看items队列中的内容 ./redis-cli llen ebay_redis:items 可以看到该items中总的个数
“答案来源于网络,供您参考” 希望以上信息可以帮到您!
