
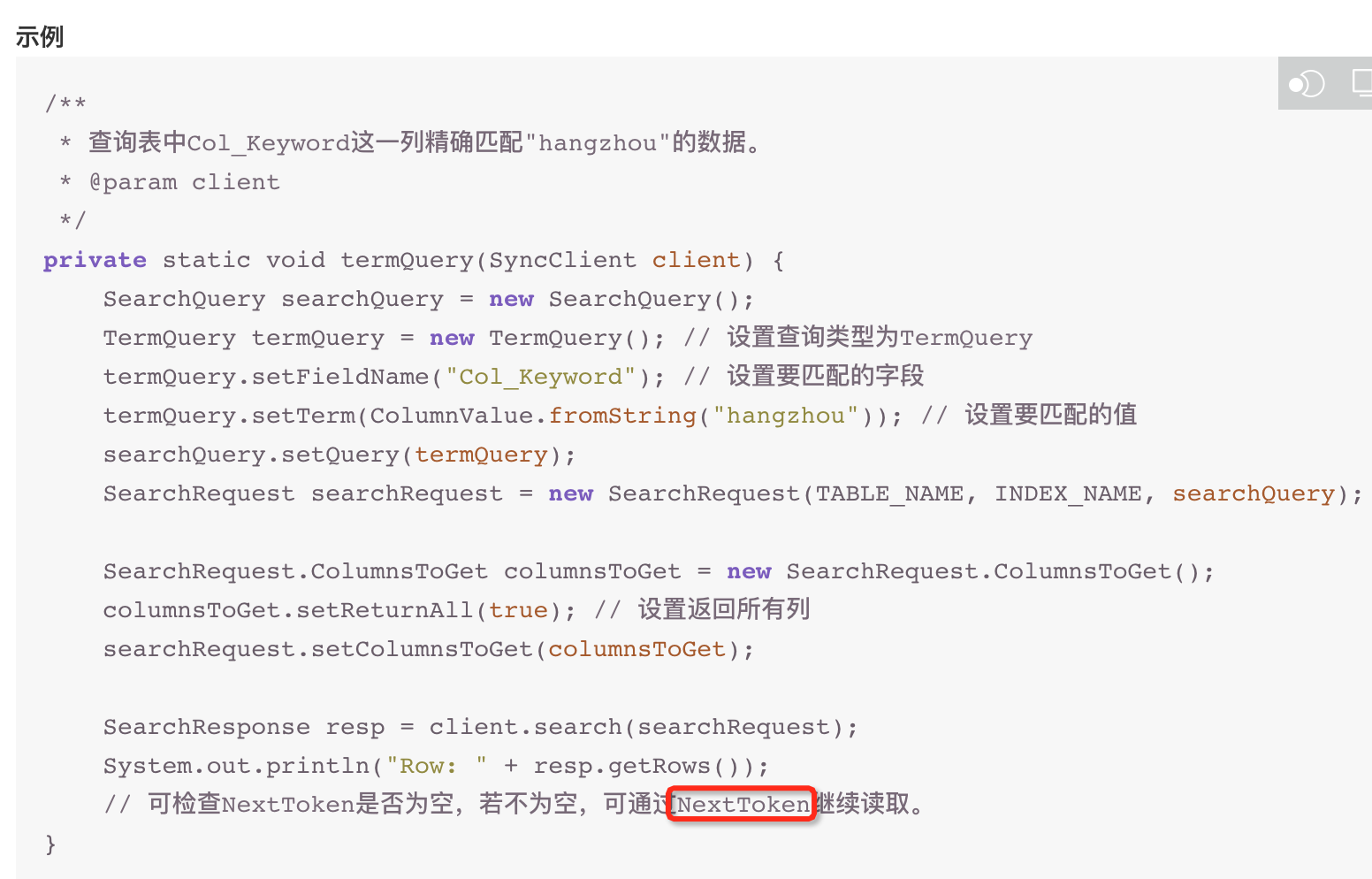
使用多元索引时的精确查询时,需要使用nexttoken继续读取,但是文档没有给出如何使用,请问这里该怎么用?
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云的某些服务中,如表格存储(Table Store,原OTS)等,在进行大数据量查询时,如果结果集超过单次请求的最大限制,服务会返回一个NextToken用于获取下一页数据。这个机制允许你分页读取大量数据,而无需一次性加载所有数据到内存中,特别适用于处理大数据查询场景。
使用NextToken进行精确查询的步骤通常如下:
发起初始查询请求:在你的查询请求中,除了指定查询条件外,还需要设置好每页返回的结果数量(如通过Limit参数)。如果结果集超过这个限制,服务响应中会包含一个NextToken字段。
检查响应中的NextToken:在收到首次查询的响应后,检查是否有NextToken。如果有,表示还有更多数据待读取。
使用NextToken进行下一页查询:在下一次查询请求中,除了保持原有的查询条件不变,还需添加一个NextToken参数,其值就是上一次查询响应中的NextToken。这样,服务就会从上一次查询结束的位置继续返回数据。
重复步骤2和3:直到查询响应中不再包含NextToken,表明所有数据已经遍历完毕。
以Python SDK为例,如果你正在使用表格存储,代码示例可能如下:
from tablestore import *
ots_client = OTSClient('<your instance endpoint>', '<your access key id>', '<your access key secret>', '<your instance name>')
# 初始化查询条件
primary_key = [('Name', 'John'), ('Age', 20)]
columns_to_get = ['Column1', 'Column2']
inclusive_start_key = primary_key
exclusive_end_key = [('Name', 'Mary'), ('Age', 21)] # 假设这是你的范围查询边界
# 第一次查询
response = ots_client.get_range(
table_name='<your table name>',
direction=Direction.FORWARD,
inclusive_start_primary_key=inclusive_start_key,
exclusive_end_primary_key=exclusive_end_key,
columns_to_get=columns_to_get,
limit=100 # 假设每页100条记录
)
results = response['rows']
while 'next_start_primary_key' in response:
# 使用next_start_primary_key作为下一次查询的inclusive_start_primary_key
inclusive_start_key = response['next_start_primary_key']
# 发起下一页查询
response = ots_client.get_range(
table_name='<your table name>',
direction=Direction.FORWARD,
inclusive_start_primary_key=inclusive_start_key,
exclusive_end_primary_key=exclusive_end_key,
columns_to_get=columns_to_get,
limit=100
)
results.extend(response['rows'])
# results现在包含了所有满足条件的数据
请注意,上述代码是基于假设的示例,实际使用时需要根据你使用的具体阿里云服务及其SDK文档调整参数和方法名。务必参考对应服务的官方文档,因为不同的服务和SDK可能会有不同的实现细节。
