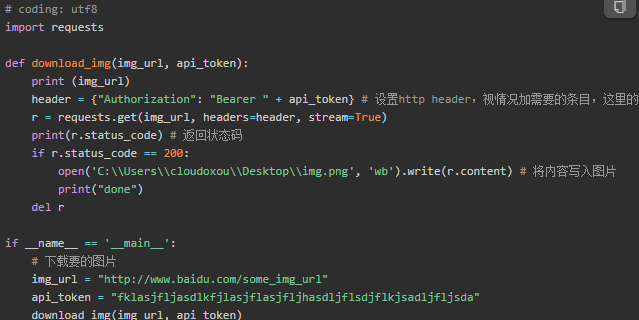
怎么下载python 批量下载图片
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
给你个文章参考一下https://www.cnblogs.com/helloxia/p/6374099.html
先来例程:
正则表达式法:(不推荐)
[python] view plain copy
# -- coding: utf-8 --
"""
Created on Thu Jun 1 16:22:10 2017
@author: qiu
"""
import urllib
import re
def get_content(url):
'''''
@url:需要下载的网址
下载网址
'''
html = urllib.request.urlopen(url)
content = html.read().decode('utf-8')#转码
html.close()#记得要将打开的网页关闭,否则会出现意想不到的问题 return content
def get_image(info):
'''''
@info:网页信息
查看下载内容的编码格式
<img pic_type="0" class="BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=69832ccb83025aafd3327ec3cbecab8d/ea2b2834349b033be32596d114ce36d3d539bd09.jpg"
width="560" height="315" changedsize="true">
利用正则表达式学习样式规则
下载图片
'''
#正则表达式写法是重点
regx = r'pic_type="0" class="BDE_Image" src="(.+?\.jpg)"'
pat = re.compile(regx)
image_code = re.findall(pat,info)
print(type(image_code))
#一个一个保存
i=1
for image_url in image_code:
print(image_url)
urllib.request.urlretrieve(image_url,"C:\\Users\\qiu\\Desktop\\python源\\桌面图片\\%s.jpg"%(i))
i+=1
url = "https://tieba.baidu.com/p/2218566379"
info = get_content(url)
get_image(info)
BeautifulSoup法:
[python] view plain copy
# -- coding: utf-8 --
"""
Created on Thu Jun 1 19:38:11 2017
@author: qiu
"""
import urllib
from bs4 import BeautifulSoup
def get_content(url):
'''''
@url:需要下载的网址
下载网址
'''
html = urllib.request.urlopen(url)
content = html.read().decode('utf-8')#转码
html.close()#记得要将打开的网页关闭,否则会出现意想不到的问题 return content
def get_image(info):
'''''
利用Soup第三方库实现抓取
'''
soup = BeautifulSoup(info,"lxml")#设置解析器为“lxml”
all_image = soup.find_all('img',class_ = "BDE_Image")
x=1
for image in all_image:
print(all_image)
urllib.request.urlretrieve(image['src'],"C:\\Users\\qiu\\Desktop\\python源\\桌面图片\\%s.jpg"%(x))
x+=1
url = "https://tieba.baidu.com/p/2218566379"
info = get_content(url)
print (info)
get_image(info)
总结:
1、首先熟悉网页编程,至少能知道图片对应程序中的位置,将所需要的图片的程序内容单独拿出来,并比较和其他噪声图片的区别,包括class,pic_type等,能够保证所需下载内容程序书写上的唯一性。
2、利用"re"正则表达式或者all_image = soup.find_all('img',class_ = "") 方法实现唯一化表达
3、一些技巧总结:print (type( ))利用查看返回值类型,列表?字典?对象?等,如果是class,一定有方法,利用print (dir( )) 查看对象的方法。或者直接看官网文档。
问题:
1、一些动态网页需要另外技巧了,例如百度图片(康复机械臂)上的图片如何下载,是另外一个需要解决的问题。
更好的方法:scrapy(爬虫框架)
不过安装有点麻烦,当然我还是pip法:库