

目录
人工智能的大语言模型(LLMs)—AI下一代浪潮?Bigger is better?大力出奇迹?
人工智能的大语言模型(LLMs)—AI下一代浪潮?Bigger is better?大力出奇迹?
大型语言模型(LLMs)是在包含巨大数据量的大规模数据集上训练的。中国工程院院士王恩东表示:“人工智能如何发展出像人类具备逻辑、意识和推理的认知能力,是人工智能研究一直探索的方向。目前来看,通过大规模数据训练超大参数量的巨量模型,被认为是非常有希望实现通用人工智能的一个重要方向。”随着巨量模型的兴起,巨量化已成为未来人工智能发展非常重要的一个趋势。而巨量化的一个核心特征就是模型参数多、训练数据量大。
2018 年谷歌发布BERT,从此,预训练模型(Pre-trained Models, PTMs)逐渐成为自然语言处理领域的主流。当然,预训练模型如今已经成为深度学习研究中的一种主流范式。
2020年,GPT-3 横空出世,这个具有 1750 亿参数规模的预训练模型所表现出来的零样本与小样本学习能力刷新了人们的认知。作为一个语言生成模型,GPT-3 不仅能够生成流畅自然的文本,还能完成问答、翻译、创作小说等一系列 NLP 任务,甚至进行简单的算术运算,并且其性能在很多任务上都超越相关领域的专有模型,达到 SOTA 水平。从此,OpenAI开始引爆了 2021 年 AI 大模型研究的热潮,大模型成为几乎所有全球头部AI公司的追逐目标。
在大模型的赛道上,算力公司、算法公司、数据公司,研究机构正在展开新一轮竞赛。
国内外AI头部公司,包括谷歌、微软、英伟达、智源人工智能研究院、阿里、百度、华为、腾讯、浪潮等国内外科技巨头和机构纷纷展开大模型研究和探索。
2021年,人工智能正式迈向“炼大模型”阶段,开展了超大规模预训练模型的“军备竞赛”。通过设计先进的算法、整合尽可能多的数据、汇聚大量算力、集约化地训练大模型,供大量企业使用。2021年,也被很多业界同行称为超大规模预训练模型的“爆发之年”。自去年 OpenAI 发布英文领域超大规模预训练语言模型 GPT-3 后,中文领域同类模型的训练进程备受关注。
2021年1月,Google 推出的 Switch Transformer 模型以高达 1.6 万亿的参数量打破了 GPT-3 作为最大 AI 模型的统治地位,成为史上首个万亿级语言模型。
2021年6月20日,举办的 2021 深度学习开发者峰会 WAVE SUMMIT 上,依托飞桨核心框架,百度文心 ERNIE 最新开源四大预训练模型:多粒度语言知识增强模型 ERNIE-Gram、长文本理解模型 ERNIE-Doc、融合场景图知识的跨模态理解模型 ERNIE-ViL、语言与视觉一体的模型 ERNIE-UNIMO。针对传统预训练技术现存的难点痛点,此次文心ERNIE开源的四大预训练模型不仅在文本语义理解、长文本建模和跨模态理解三大领域取得突破,效果上超越谷歌、微软等业界模型,还拥有广泛的应用场景和前景,进一步助力产业智能化升级。
2021年6月,第三届北京智源大会上,北京智源人工智能研究院发布了超大规模智能模型“悟道 2.0”,达到1.75 万亿参数,超过 Switch Transformer 成为全球最大的预训练模型。
随着处理能力和数据源的增长,深度学习中曾经的趋势已经成为一个原则:越大越好。近年来,语言模型的规模越来越大,只有像Google、Microsoft、NVIDIA等大公司才可以玩转千亿/万亿级的大模型,而且事实证明以大模型为基础探索通用智能的道路也远远没有到尽头,国内产业和学术界在对大模型的探索上也亦步亦趋,大规模的AI设备集群和通用性的软硬件生态协同越来越成为信息时代急需的基础设施,未来制约人工智能发展的不仅仅是对人才的竞争,大科学装置和对多场景应用的通用全栈式技术生态的不断发展进化,也越来越重要。
2021年底总结的时候,Jeff说到,这些大模型通常使用自监督学习方法,这个趋势令人兴奋。一方面可以大大减少工作量,另一方面在长尾任务中也能取得更好表现。
单体模型VS混合模型
现在业界提高模型参数量有两种技术路线,产生两种不同的模型结构,一种是单体模型,一种是混合模型。如华为的盘古大模型、百度的文心大模型、英伟达联合微软发布的自然语言生成模型 MT-NLG 、浪潮的源大模型等走的都是单体模型路线;而智源的悟道模型、阿里 M6 等走的是混合模型路线。
大模型的意义
- 大模型被大多数专家认为是走向AGI的重要途径之一。超大规模预训练模型是从弱人工智能向通用人工智能的突破性探索,解决了传统深度学习的应用碎片化难题,引发科研机构和企业重点投入。
- 大模型泛化能力强可减少数据标注依赖。可以吸收海量知识,从里面提高模型的泛化能力,可以减少对领域数据标注的依赖。
- 大模型的预先学习可减轻特定领域的数据量。超大规模预训练模型在海量通用数据上进行预先学习和训练,能有效缓解AI领域通用数据的激增与专用数据匮乏的矛盾,具备通用智能的雏形。
- 大模型具有强通用性和少样本学习能力。预训练大模型普适性强,可满足垂直行业的共性需求。预训练大模型迁移性好,可满足典型产品的技术要求。GPT-3凸显了一种小样本学习以及泛化能力,而且两个层面的能力都非常优秀。
- 大模型提高了模型使用效率。业内普遍认为“一次开发,终身使用”。拥有更通识的大模型将为细分任务奠定基础,后续应用无需投入大量标注数据及从头训练调参,效率明显提升。
- 大模型承上启下,深刻影响底层技术和上层应用的发展;向下驱动数据技术和计算架构能力的提升,支撑模型训练、部署和优化,向上支撑上层应用的服务转型。
- 模型的参数规模越大,优势越明显。
- AIGC(AI生成内容)就是大模型落地的一个重要方向(内容消费/创意设计)。
AIGC(AI Generated Content,人工智能创造内容/虚拟内容/虚拟人),借助大模型的跨模态综合技术能力,可以激发创意,提升内容多样性,降低制作成本,将会实现大规模应用。随着深度学习的发展,AI生成虚拟内容AIGC正渗透在图像、视频、CG、AI训练数据等各类领域,甚至同时覆盖多模态的虚拟人技术。其中虚拟数字人,指存在于非物理世界中,由图形渲染、动作捕捉、语音合成等计算机手段创造及使用,并具有多重人类特征的综合产物。目前分为「CG建模+真人驱动」和「深度合成+计算驱动」两类。
大模型的局限性
- 资本门槛:大模型的训练,以GPT-3为例,训练一次的成本是1200万美金;
- 技术门槛:AI框架的深度优化和并行能力要求很高。
- 跨领域门槛:大模型多方向问题亟待解决,生态建设不容小觑。未来预训练大模型将重点解决应用、可信、跨学科合作、资源不平衡和开放共享等问题。
大模型的四个障碍
Andrew NG 认为,构建越来越大的模型的努力带来了自己的挑战。庞大模型的开发人员必须克服四个巨大的障碍。
- 数据:大型模型需要大量数据,但网络和数字图书馆等大型来源可能缺乏高质量数据。例如,研究人员发现 BookCorpus 是一个包含 11,000 本电子书的集合,已被用于训练 30 多个大型语言模型,可能会传播对某些宗教的偏见,因为它缺乏讨论基督教和伊斯兰教以外信仰的文本。 AI 社区越来越意识到数据质量至关重要,但尚未就编译大规模、高质量数据集的有效方法达成共识。
- 速度:今天的硬件难以处理庞大的模型,当位反复进出内存时,这些模型可能会陷入困境。为了减少延迟,Switch Transformer 背后的 Google 团队开发了一种方法,可以为每个令牌处理模型层的选定子集。他们最好的模型的预测速度比参数数量只有其 1/30 的模型快 66%。同时,微软开发了 DeepSpeed 库,它并行处理数据、单个层和层组,并通过在 CPU 和 GPU 之间划分任务来减少冗余处理。
- 能源:训练如此庞大的网络会消耗大量的电能。 2019 年的一项研究发现,使用化石燃料,在 8 个 Nvidia P100 GPU 上训练一个 2 亿参数的变压器模型,在五年的驾驶过程中排放的二氧化碳几乎与一辆普通汽车一样多。新一代有望加速人工智能的芯片,如 Cerebras 的 WSE-2 和谷歌最新的 TPU,可能有助于减少排放,同时风能、太阳能和其他清洁能源增加以满足需求。
- 交付:这些庞大的模型太大而无法在消费者或边缘设备上运行,因此大规模部署它们需要互联网访问(较慢)或精简实施(能力较弱)。
未来的AI蓝图要拥抱绿色低碳—绿色AI
众所周知,全球变暖是人类的行为造成地球气候变化的后果。2020年9月,中国提出努力争取在2060年前实现碳中和。为了能够早日实现我国关于“碳中和”以及“碳达峰”的战略目标,在今后的40年当中,中国在产业、消费、能源以及区域结构等方面都会做出重大整顿。
随着“碳中和”逐步被提高到国家战略的高度之上,人工智能行业,包括机器学习模型当然也要倡导追求碳中和。不可否认,数据集和模型规模的增长,带来了多种语言任务上准确率的显著提升,并通过NLP 基准任务上的全面改进证明了这一点,但是不应该把模型性能当作唯一标准。未来的AI蓝图要拥抱绿色低碳,助力实现碳达峰碳中和目标。
随着AI技术加速与各行各业融合创新,数据中心和大规模AI计算实现了重要的经济和社会价值,但其能耗和对环境的影响不容忽视,亟需发展对环境更友好的“绿色AI”技术,降低模型训练和使用的能耗。
针对该问题,来自谷歌和美国加州大学伯克利分校的研究人员最近联合发表一项研究论文,着重评估并比较了 5 个大型自然语言处理(NLP)模型的能耗和碳排放量,其中包括 T5、Meena、GShard、Switch Transformer 和 GPT-3。该论文提出,如果推出同时考量模型准确性和碳排放的标准,我们就可以想象一个良性循环,通过加速算法、系统、硬件、数据中心以及碳中和在效率和成本方面的创新,即可减缓机器学习任务碳足迹的日益增长。
未来几年,“绿色AI”相关技术将持续蓬勃发展,围绕高能效的架构设计、训练和推理策略、数据利用等构建体系,形成兼顾性能和能耗的评价标准。算力更高、能耗较低的AI芯片将不断涌现;领军AI企业构建集约化的大算力和大模型,改善下游性能,降低整体能耗成本。
相关文章:
《Carbon Emissions and Large Neural Network Training》 http://arxiv.org/abs/2104.10350v2
2017年以来,大规模语言模型发展史
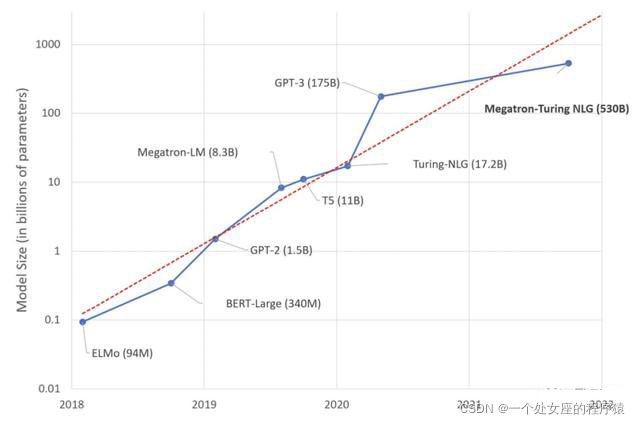
发布时间 |
大模型 |
参数量 |
训练数据 |
多模态 |
功能 |
机构 |
| 2017年 | GPT-1 | 1.1亿 | 文本 | OpenAI | ||
2018年 10月 |
Bert | 3.4亿 | 文本 | |||
2019年 08月 |
GPT-2 | 15亿 | 文本 | OpenAI | ||
2019年 08月 |
MegatronLM | 83亿 | 文本 | NVIDIA | ||
| 2020年01月 | Turing-NLG | 170 亿 | 文本 | Microsoft | ||
| 2020年05月 | GPT-3 | 1750 亿 | 45TB | 文本 | NLU,文本生成 | OpenAI |
| 2020年06月 | GShard | 6190 亿 | 比拥有 1750 亿参数的 GPT-3 消耗的能源少约 53 倍,净碳排放量少约 127 倍,这主要得益于 GShard 在算法+硬件上的多重优化。 | |||
| 2021 年 01月 | Switch Transformer | 1.6万亿 | ||||
| 2021年03月 | CPM-1 (悟道2.0,文源) |
26亿 | 文本 | NLU,文本生成 | 智源研究院 | |
2021年04月 |
PLUG |
270亿 |
>1.1TB high-quality |
文本 |
NLU,文本生成 |
阿里达摩院 |
2021年04月 |
盘古-α |
2000亿 |
1.1TB high-quality 80TB raw |
文本 |
NLU,文本生成 |
华为&循环智能 |
2021年04月 |
孟子(BERT, T5,Oscar) |
10亿 |
300GB |
文本,图像 |
NLU,文本生成 图像生成文本 |
澜舟科技 |
2021年06月 |
M6 |
1000亿 |
1.9TB images 292GB texts |
文本,图像 |
NLU,文本生成 图像生成文本文本生成图像 |
阿里达摩院 |
2021年06月 |
CPM-2 (悟道2.0) CPM-MoE |
总共1.75万亿 其中110亿中文模型 110亿中英模型 1980亿中英MoE模型 |
2.3TB Chinese 300GB English |
文本 |
NLU,文本生成 |
智源研究院 |
2021年06月 |
CogView(悟道-文汇) |
40亿 |
30 million high-quality (Chinese) text-image pairs |
文本,图像 |
文本生成图像 图像生成文本 |
智源研究院 |
2021年07月 |
ERNIE3.0 |
100亿 |
4TB text and KG |
文本 |
NLU,文本生成 |
百度 |
2021年09月 |
源1.0 |
2457亿 |
5TB high-quality |
文本 |
NLU,文本生成 |
浪潮 |
| 2021年10月 | Megatron Turing-NLG 威震天-图灵 |
5300亿 | 文本 |
NLU |
Microsoft+NVIDIA | |
2021年10月 |
神农 |
10亿 |
数百GB |
文本 |
NLU,文本生成 |
腾讯 |
2021年12月 |
Gopher |
2800亿 |
10.5TB 的MassiveText语料库 | 文本 |
Gopher在 124 项评估任务中的 100 项中优于当前最先进的技术。 | DeepMind |
| 2021年12月 | ERNIE3.0 Titan |
2600亿 | 百度 | |||
| 2021年12月 | GLaM | 1.2 万亿 | 通用稀疏语言模型 |
7 项小样本学习领域的性能超过 GPT-3 |
注:该表将持续更新
未来趋势
清华大学教授、智源大模型技术委员会成员刘知远说: “大规模预训练模型是人工智能的最新技术高地,是对海量数据、高性能计算和学习理论原始创新的全方位考验”。
大小模型协同进化。大模型参数竞赛,在未来某个时刻,会进入冷静期,大小模型将在云边端协同进化。达摩院认为,因性能与能耗提升不成比例,受效率问题的限制,大模型参数竞赛将进入冷静期,大小模型云边端协同进化会是未来趋势。 大模型向边、端的小模型输出模型能力,小模型负责实际的推理与执行,同时小模型再向大模型反馈算法与执行成效,让大模型的能力持续强化,形成有机循环的智能体系。
相关文章
NLP之PLUG:阿里达摩院发布最大中文预训练语言模型PLUG的简介、架构组成、模型训练、使用方法之详细攻略_一个处女座的程序猿-CSDN博客
