把这几天零散的笔记收集一下,内容比较重要,虽然似乎很简单,一个是字符串切片,一个是数据结构,都是比较重要的语法。主要是集中一下常用的操作,没有什么难度,对代码输出就明白了。代码中也备了注释。看代码吧!
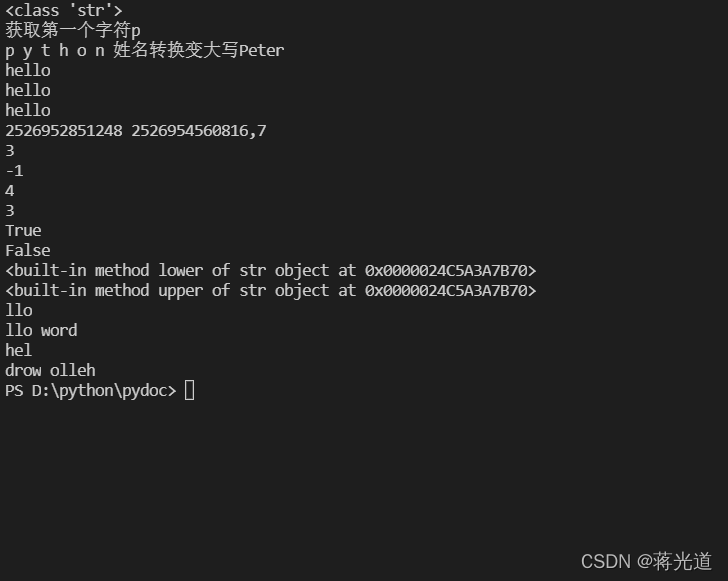
一:字符串以及切片相关
#py字符串操作 # 切片语法[start:end:step] step默认是1 #下表会越界,但是切片不会 Test = "python" print(type(Test)) print('获取第一个字符%s'%Test[0]) for item in Test : print(item,end=' ') name = 'Peter' print("姓名转换变大写%s"%name.capitalize())#首字母变大写 a = ' hello ' b = a.strip()#去除字符串中存在地空格 c = ' hello ' d = c.lstrip() #去除左边的空格 e = 'hello ' f =e.rstrip()#去除右边的空格 print(b) print(d) print(f) #id函数,查看一个对象的内存地址 g = id(a); g1 = id(b) print(g,g1,end=',') dataStr = 'i love python' h1 = dataStr.find('p')#查找p是再字符串当中所对应的下标值(一般返回第一次出现的位置) h2 = dataStr.find('o') h3 = dataStr.find('m') #如果没有找到就会返回-1 print(h1) print(h2) print(h3) print(dataStr.index('v'))#也是一种查找的方式,和find方式很相似 print(dataStr.index('o')) # print(dataStr.index('m'))#index如果没有找到就会返回异常 print(dataStr.startswith('i'))#判断想要查找的字符串是否以某字符开头 print(dataStr.endswith('y'))#判断要查找的字符串是否以某字符结尾 print(dataStr.lower)#将字符串都变成小写 print(dataStr.upper)#将字符串都转换为大写 #进行切片的操作 strMsg = "hello word" #下面进行切片,也就是取字符串当中部分数据 print(strMsg[2:5])#不包含5下标(切片,左闭右开) print(strMsg[2:])#从第二个下标一直取到最后(从第三个字符到最后) print(strMsg[0:3])#从第一个字符取到第三个字符 print(strMsg[::-1])#倒序输出
二:数据结构
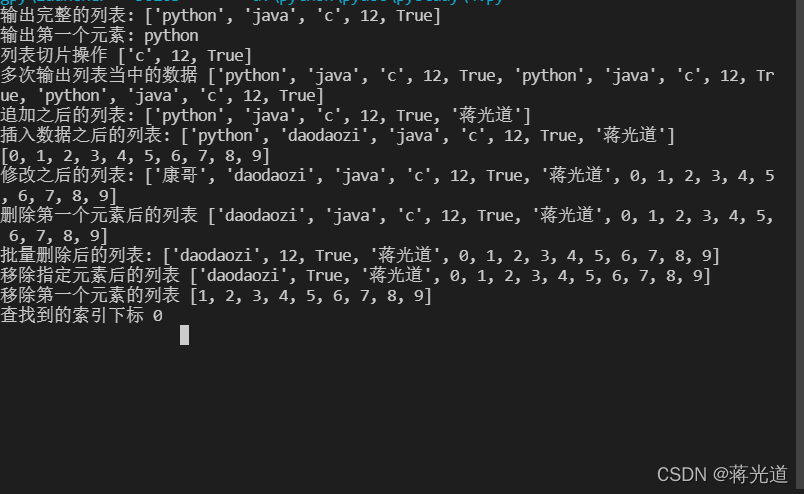
1:列表(list)
from typing import List listA = ["python","java","c",12,True] print("输出完整的列表:",listA) print("输出第一个元素:",listA[0]) print("列表切片操作",listA[2:5]) print("多次输出列表当中的数据",listA*3) listA.append("蒋光道")#给列表追加入数据 print("追加之后的列表:",listA) listA.insert(1,'daodaozi')#列表插入数据 print("插入数据之后的列表:",listA) listB =list(range(10)) print(listB) listA.extend(listB)#扩展listA,批量添加 listA[0] = '康哥'#修改列表相应的值 print("修改之后的列表:",listA) del listA[0] #删除列表第一个元素 print("删除第一个元素后的列表",listA) del listA[1:3] #进行批量范围删除 print("批量删除后的列表:",listA) listA.remove(12)#移除指定元素 print("移除指定元素后的列表",listA) listB.pop(0)#移除第一个元素 print("移除第一个元素的列表",listB) n = listB.index(1)#查找元素所在的索引下标 print("查找到的索引下标",n)
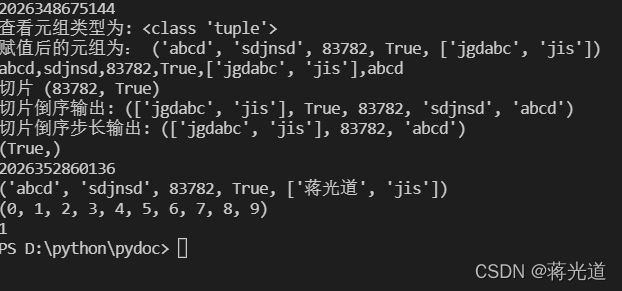
2:元组(tuple)
#py数据结构元组 # 特点 : 1:不可变 # 2:用小括号来创建元组类型 # 3:用,号来分割可以是任何的类型 # 4:当元组中只有一个元素时,要加入逗号,不然解释器会当作整型来进行处理 # 4:元组同样支持切片操作 tupleA = () print(id(tupleA)) print("查看元组类型为:",type(tupleA))#查看元组类型 tupleA = ("abcd","sdjnsd",83782,True,["jgdabc","jis"]) print("赋值后的元组为:",tupleA) # 遍历元组 for item in tupleA : print(item,end=",") #取元组的元素 print(tupleA[0]) #切片元组 print("切片",tupleA[2:4]) print("切片倒序输出:",tupleA[::-1]) print("切片倒序步长输出:",tupleA[::-2])#倒序输出每个两个字符取一次 print(tupleA[-2:-1:])#要考虑到左闭右开,不指定步长的话默认步长为1 print(id(tupleA) ) #打印元组的内存地址id tupleA[4][0] = "蒋光道" #尝试对元组中的列表元素进行修改 print(tupleA) tuple_c = tuple(range(10)) #强转 print(tuple_c) print(tuple_c.count(1)) #统计数据项中指定元素的出现个数
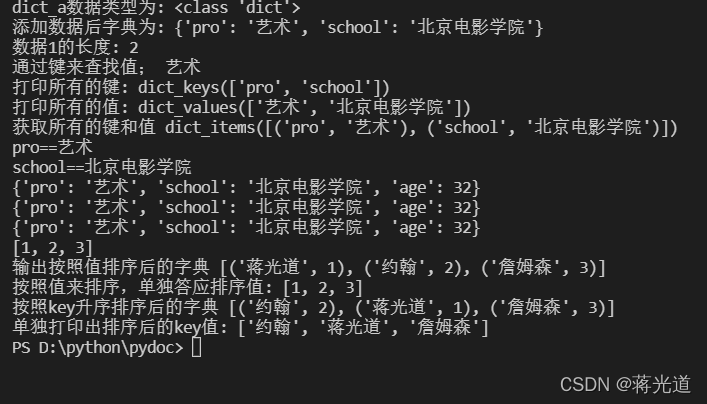
3:字典(dict)
#python数据结构字典 # 字典是由键值对组成得集合,通常使用键来进行对数据得访问。 # 特点: """ 不是序列类型,没有下标得概念,是一个无无序的键值组合 {}表示字典对象,每个键用逗号分隔 键必须是不变的类型 每个键必须是唯一,如果重复,则后者会被覆盖 """ # 创建字典 dict_a = {} print("dict_a数据类型为:",type(dict_a)) dict_a['name']='jgdabc'#说明可以通过键值进行追加 dict_a['post']="歌手" # 另一个添加方式 dict_a={"pro":"艺术","school":"北京电影学院"} print("添加数据后字典为:",dict_a) print("数据1的长度:",len(dict_a)) # 通过键来查找值 print("通过键来查找值;",dict_a['pro']) print("打印所有的键:",dict_a.keys()) print("打印所有的值:",dict_a.values()) print("获取所有的键和值",dict_a.items()) for key,Value in dict_a.items() : print(key+"=="+Value) dict_a.update({"age":32}) #可以添加或者更新 print(dict_a) # 删除操作 #del dict_a['age'] print(dict_a) #另一种删除 #dict_a.pop("school") print(dict_a) # 排序操作 dict_a = {"蒋光道":1,"约翰":2,"詹姆森":3} new_dict_aa = sorted(dict_a.values())#按照值牌序 print(new_dict_aa) new_dict_bb = sorted(dict_a.items(),key=lambda d:d[1],reverse=False) print("输出按照值排序后的字典",new_dict_bb) print("按照值来排序,单独答应排序值:",new_dict_aa) new_dict_a = sorted(dict_a.items(),key=lambda d:d[0],reverse=False)#按照key升序排序,ASCII码排序 print("按照key升序排序后的字典",new_dict_a) new_dict_a_1 = sorted(dict_a) print("单独打印出排序后的key值:",new_dict_a_1)