1.索引基础
-阐述一些概念
1.1 单词-文档矩阵
文档1 |
文档2 |
|
单词1 |
||
单词2 |
搜索引擎的索引其实就是实现单词-文档矩阵的具体数据结构
实现方式包括:
1.倒排索引
2.签名文件
3.后缀树
等
1.2 倒排索引基本概念
- 文档(document):以文档形式存在的存储索引对象
- 文档集合(document collection):文档集合,海量网页、一批索引对象都属于此
- 文档编号(document id):文档的唯一内部id DocID
- 单词编号(word id):唯一表征某个单词的编号
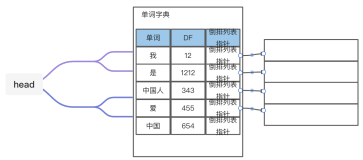
- 倒排索引(inverted Index):单词-文档矩阵的一种具体存储形式,包括:单词词典+倒排文件
- 单词词典(Lexicon):文档集合中出现过的所有单词,词典中包括:单词本身+指向倒排列表的指针
- 倒排列表(PostingList):某个单词存在的所有文档的文档列表+出现在文档中的位置,列表中每条记录成为一个倒排想
- 倒排文件(InvertedFile):存储倒排列表的文件
- 单词词频(TF)
- 文档频率信息:文档集合中有多少个文档包含某个单词

倒排索引基本概念示意图
1.3 倒排索引简单实例
单词ID |
单词 |
文档频率 |
倒排索引(DocID;TF;<POS>) |
1 |
谷歌 |
2(文档列表中有两个文档包含该词) |
(1;2;<11,20>),(12,1,<7>) 文档id;单词词频;出现在文档中的位置 |
2 |
百度 |
4 |
2.单词词典
-维护文档集合中所有单词的相关信息+倒排列表位置信息,常用数据结构:哈希+链表、树形词典
这两个结构很简单 一个是hash表+链表(hash冲突拉链)、树形词典(B树、B+树)
3.倒排列表(Posting List)
构建过程前面已经阐述了
在实际搜索引擎中,不存储实际文档编号,代之以文档编号差值(D-gap)

4.建立索引
-给定一个文档集合,如何建立起来索引呢?
4.1 两边文档遍历 (2-pass in memory inversion)
此方法完全在内存里完成索引构建
- 第一遍文档遍历(资源准备阶段)
获得统计信息,分配内存资源,建立好单词相对应倒排列表地在内存中位置信息
- 第二遍文档遍历
生成单词的倒排列表信息,填充内存过程
建立每个单词的倒排列表信息,统计例如:
1.单词每个文档id
2.单词在文档中出现次数
缺点:两次遍历,读取磁盘文件,构建速度慢,内存大小不可控
4.2 排序法(Sort-based inversion)
-分配固定内存,逐步将文档加载,构建 单词词典+倒排文件,内存填满后刷入内存临时文件伴随排序过程,所以叫排序法
- 中间结果内存排序
- 逐一读取文档 在内存中 构建单词词典+文档对应的倒排列表项(三元组)
- 内存沾满后,对中间结果排序输入磁盘临时文件(排序原则:主键(单词id)、次建(文档id))、清空内存
- 合并中间结果
- 若干磁盘文件刷入内存缓冲区
- 归并排序
- 清空缓冲区中已排序数据
- 生成最终索引文件

缺点:构建过程中,词典和倒排列表共享内存,但是词典是不会刷入磁盘的,导致占用内存越来越多,后期中间结果可用内存越来越少。
4.3 归并法(Merge-based InVersion)
-两步走,跟排序法类似,但是构建过程步骤不太一样

- 完整的内存索引结构
- 相比排序法,归并法会在内存中构建完整的索引(部分),占满后刷入磁盘,清空内存
- 磁盘临时文件中包含:部分词典+部分索引
- 索引合并,合并临时文件中的 部分词典->最终词典 部分索引->最终索引
5.动态索引
-索引构建完成后,会有新文档加入,需要索引实现动态更新,这是个流程控制

6.索引更新策略
-针对5中介绍临时索引占用内存的问题,需要定期刷入磁盘中,因此提出若干策略:
完全重建策略、再合并策略、原地更新策略、混合策略
6.1 完全重建策略(Complete Re-Build)
思路:新增文档数量>阈值,合并文档,并重建索引,构建完成后替换老索引
适用范围:小文档集合
6.2 再合并策略(Re-Merge)
思路:内存中增量索引,新增文档数量>阈值 或 内存>阈值,触发合并
由于倒排列表中存放顺序按照单词字典顺序从低到高排序了,增量索引在遍历词典时候也按照字典序从低到高遍历,老倒排文档一遍扫描即可

缺点:需要一次读取老索引,写入新缩影,消耗相对较大
6.3 原地更新策略(In-Place)
-思路:索引构建过程中不同单词之间预留空间,合并过程填充进老索引的空隙中,预留空间不足,将该单词倒排列表迁移到磁盘另一连续存储区中(破坏单词连续性)
-缺点:索引合并时不能顺序读取,需要维护单词到倒排文件相应位置的映射表
6.4 混合策略(Hybrid)
-思路:依据倒排列表单词长度,采取不同更新策略
长倒排列表单词:原地更新
短倒排列表单词:再合并
7.查询处理
-在索引构建完成后,如何利用呢?这就是查询处理过程要解决的问题
-需要注意,最终的目标是得到文档的相关性得分
7.1 一次一文档(Doc at a time)
-按照文档为单位,依次计算文档的相关性得分(文档相关性得分一次性被计算出来)

7.2 一次一单词(Term at a time)
-按照单词为单位,依次计算文档的相关性得分(单词相关性得分一次性被计算出来)

7.3 跳跃指针(Skip Pointers)
-多查询词情况,对查询文档采取交集操作,理想情况是在索引中存储稳定id,直接取交。但是多数情况是以 文档编号差值(D-Gap)+压缩编码方式实现,此时取交操作就变得复杂,因此引入跳跃指针
- 思路:
- 倒排列表数据切分若干数据块
- 数据块添加原信息(数据块初始文档id + 下一个原信息位置指针)

好处:
1.不需要将整个倒排索引文件都解压
2.搜索过程中只需要解压当前数据块头部元信息和下一数据块头部原信息,定位是否为目标数据块即可
数据块划分策略:倒排列表长度L开方;
8.多字段索引
-文档会区分字段类型提供搜索,例如:论文检索中,按照 标题、作者、正文等多个字段,搜索关键词出现在不同字段里代表权重不同(出现在标题中的权重比正文中的大),这直接影响着文档相关性评分。为实现多字段索引方式如下:多索引方式、倒排列表方式、扩展列表方式
8.1 多索引方式
-针对不同字段,单独建立索引
8.2 倒排列表方式
-在倒排列表中添加字段信息标识
word |
[1:2:"001"] |
[2:1:"010"] |
[3:2:"001,101"] |
8.3 扩展列表方式
-倒排列表中存放单词所在文档中位置,添加字段的扩展列表,标注文档中对应字段单词所在位置

9.短信查询
-对于短语的检索强调单词之间的顺序(你懂得和懂你的语义就不一样),但是目前的倒排列表结构中并没有维护单词之间顺序关系的信息,短语查询就是用来解决这个问题的。包括:位置信息索引、双刺索引、短语索引
9.1 位置信息索引(Position Index)
-倒排列表中添加单词位置信息。判断单词位置是否连续实现
-缺点:存储位置信息,索引长句剧增,消耗存储空间,磁盘读取效率
9.2 双词索引(Nextword Index)
-针对两次短语提供的快速查询方案
思路:
- 双词拆分为首词和下词,首词词典持有下词词典指针,下词词典指针指向短语的倒排列表
- 查询过程按照首词,下词依次流转

如图发现文档5是满足要求的
缺点:词典从一维扩展为二维,倒排列表个数爆炸性增长。
应用场景:对计算代价高的短语建立双词索引,例如:我、的这种停用词
9.3 短语索引(Pharse Index)
-直接给短语加索引。
思路:
- 挖掘热门短语
- 针对热门短语单独建立索引
9.4 混合方法
- 位置索引适合常规短语查询(计算代价较小的短语)
- 双词索引适合计算代价大的常用词
- 短语索引适合高频短语、热门短语查询
三者互补,混合方法就是充分利用三种索引方式不同优势