Pandas中为数据分类的需求提供专门的类型category,可以由多种方式创建,并结合dataframe或Series进行使用。
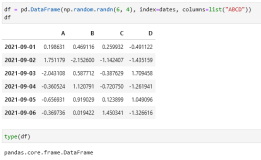
首先生成样本数据:
df = pd.DataFrame(
{"id": [1, 2, 3, 4, 5, 6]})
df
1. 创建
category可以从不同方式创建,本文以给样本添加分类列,列名为grade逐一进行说明。
1.1 Series创建
创建一个类型为category的Series,再将其作为样本数据的grade列
g = pd.Series(
["a", "b", "c", "a","e"],
dtype="category")
# 再将该Series作为dataframe中一列
df["grade"]=g
1.2DataFrame创建
创建一个dataframe,其中grade类型为category,然后将两个dataframe进行拼接
df1 = pd.DataFrame({
"grade":
["a","b","c","a","e",np.nan]},
dtype="category")
df = pd.concat([df,df1],axis=1)
df
1.3 Categorical创建
使用pd.Categorical创建分类,再作为Series放到Dataframe里面。
g = pd.Categorical(
["a", "b", "c", "a","e",np.nan],
categories=["a", "b", "c","e"],
ordered=False)
df["grade"]=pd.Series(g)
1.4 CategoricalDtype创建
CategoricalDtype是pandas的数据类型对象,指定dtype='category'时,就等同于dtype = CategoricalDtype()。包含以下参数:
categories:所有不重复分类值ordered:设定分类排序,默认值为False。
创建CategoricalDtype类型c,并将df.grade转为该类型
from pandas.api.types import CategoricalDtype
c = CategoricalDtype(
["a", "b", "c","e"])
df["grade"]=pd.Series(
["a", "b", "c", "a","e",np.nan])
df.grade = df.grade.astype(c)
2. 使用
2.1 分类的描述性统计
describe可以统计分类数据做描述性统计,返回以下值:
count:统计数量unique:统计分类值个数top:出现最多次的值。此处是a。freq:出现最多次值出现的次数。此处是a出现了2次。

2.2 分类CRUD
可以对分类数据进行相应的CRUD操作,逐一进行说明。
2.2.1 增加分类
使用add_categories增加新的分类
df.grade.cat.add_categories(["d"])
2.2.2 设置分类
使用set_categories重新设置分类
df.grade = df.grade.cat.set_categories(["a","b","c","d"])
df.grade
2.2.3 删除分类
使用 remove_categories删除分类, 删除的值将替换为 np.nan
df.grade = df.grade.cat.remove_categories(["b"])
df.grade