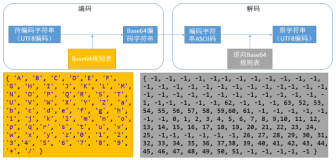
看一段代码,了解下java中编码
import java.io.UnsupportedEncodingException;
public class Test{
public static void main(String[] args)
throws UnsupportedEncodingException {
System.out.println(System.getProperty("file.encoding")); //gbk
String s = "中文";
System.out.println(s);
System.out.println(s.length());
String t = new String(s.getBytes(),"utf-8");
System.out.println(t);
System.out.println(t.length());
}
}
其中,Test.java源文件是utf-8编码的,系统默认编码是GBK输出结果如下所示:
E:\testencoding>java Test
GBK
涓枃
3
中文
2
我的理解是当用javac Test.java命令时,由于没有指定编码格式,jdk采用系统默认的编码格式将源程序编译成unicode字节码,形成class文件保存。本例中,源文件中的字符串"中文"本来是以utf-8编码保存的一串字节流,但是编译时,按照gbk的格式转换成unicode,因此程序执行时输出s时会乱码,刚好“中文”字符串中两个汉字以utf-8格式保存在文件中,各占用3个字节,而gbk编码格式中这两个汉字各占2个字节,所以将6个字节,按照gbk格式转换成java中的字符串时,长度为3。后面将s先按照当前系统的编码格式(gbk)编码,然后按照utf-8格式解码,这与源文件中最初的"中文"编码、解码一致,不会出现乱码的问题了