通过讲解PCA算法的原理,使大家明白降维算法的大致原理,以及能够实现怎么样的功能。结合应用降维算法在分类算法使用之前进行预处理的实践,帮助大家体会算法的作用。
0 相关源码
1 PCA算法及原理概述
1.1 何为降维?
◆ 从高维度变为低维度的过程就是降维
◆ 例如拍照就是把处在三维空间中的人或物从转换到作为二 维平面的
照片中
◆ 降维有线性的、也有非线性的方法。在机器学习中可以简化运算,减少特征量
1.2 PCA算法介绍
◆ PCA算法是一种常用的线性降维算法,算法类似于"投影”
◆ 降维简化了数据集,故可以视为一个压缩过程,在压缩过程中可能;会有信息丢失
◆ PCA除可以用来精简特征,还可以应用在图像处理中
例如基于PCA算法的特征脸法,它可以用来人脸识别
1.3 PCA算法原理简介
◆ PCA是基于K-L变换实现的一种算法
◆ PCA算法在实现上用到了协方差矩阵,以及矩阵的特征分解
◆ 基本主要内容在于求出协方差矩阵,然后求协方差矩阵的特征值与特征向量
1.4 PCA算法步骤
◆ 输入n行m列的矩阵X ,代表m条n维数据
◆ 将矩阵X的每一行进行零均值化处理
◆ 求出X的协方差矩阵C
◆ 求出协方差矩阵C的特征值 与特征向量
◆ 将特征向量按照特征值的大小从上至下依次排列,取前k行,作为矩阵P
◆ 求出P与X矩阵叉乘的结果,即为降维值k维的m条数据
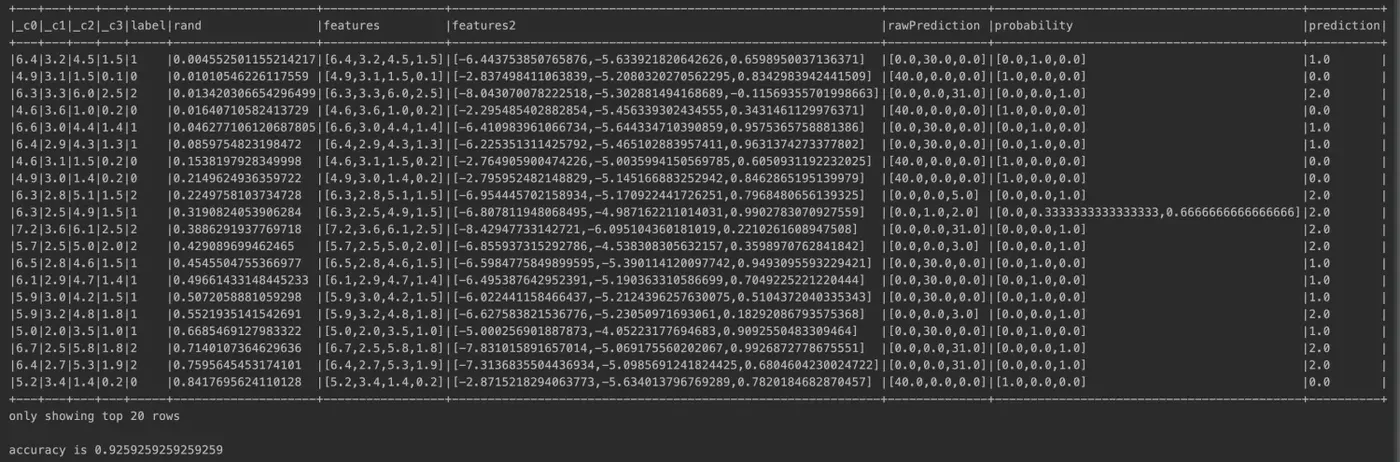
2 实战PCA算法实现降维
- 代码
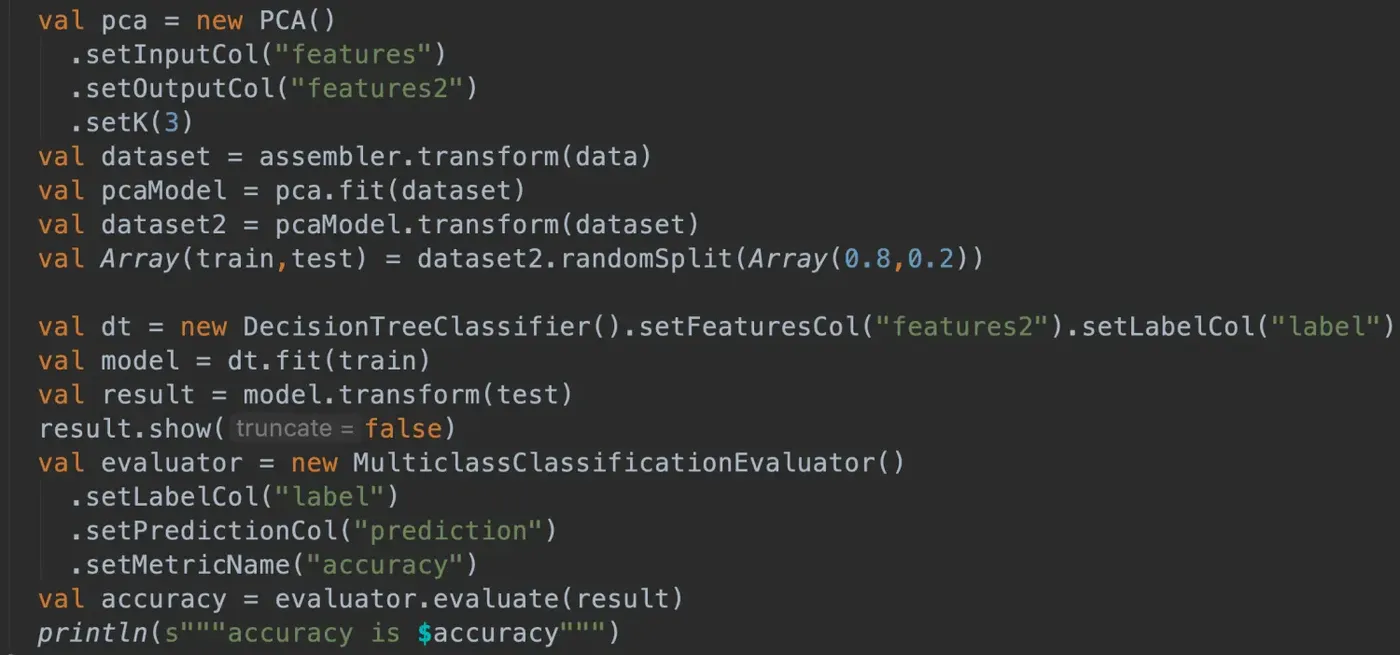
- 特征列降维成3个