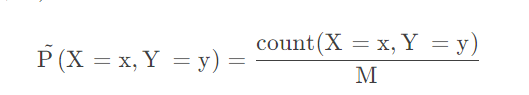机器学习就是需要找到模型的鞍点,也就是最优点。因为模型很多时候并不是完全的凸函数,所以如果没有好的优化方法可能会跑不到极值点,或者是局部极值,甚至是偏离。所以选择一个良好的优化方法是至关重要的。首先是比较常规的优化方法:梯度下降。以下介绍的这些算法都不是用于当个算法,可以试用于能可微的所有算法。
Gradient Descent
常见会用在logistics regression或者是linear regression里面。比如logistics regression,这个模型直接等于0是求不出解析解的,所有只能用一些迭代方法求解。当样本的label是
每一个样本正确概率:
最大似然函数 化简:
化简:
target function就是如上的 ,要做的就是优化上面的损失函数。
,要做的就是优化上面的损失函数。




这个就是当前点的梯度,而函数的更新方向就是向着梯度的负方向进行的,所以最后是要减:

最优点很明显是在左边,而待优化点是



梯度下降有三种:全量梯度下降,所有是数据一起做迭代更新。数据量很大的话速度回很慢。小批量梯度下降,一部分一部分数据的就行迭代数据。随机梯度下降SGD,随机选取几个进行迭代,可能迭代的方向会有偏差,但是随着时间流逝大方向还是一样的。代码实现前面的logistics regression中已经有了,不再重复。
给予这种不足,给出了牛顿法的改进。
NewTon Method
既然梯度下降做的是一阶拟合,那么试一下二阶拟合。泰勒展开二阶: 两边对
两边对 求导数:
求导数:

 代换一下:
代换一下:
牛顿法有点像坐标上升的方法,先迭代一个坐标,再迭代另一个,和SMO类似。可以看到牛顿法这个时候就是二次曲线的拟合了:





代码实现
def sigmoid(
x1, x2, theta1, theta2, theta3):
z = (theta1*x1+ theta2*x2+theta3).astype("float_")
return 1.0 / (1.0 + np.exp(-z))
'''cross entropy loss function
'''
def cost(
x1, x2, y, theta_1, theta_2, theta_3):
sigmoid_probs = sigmoid(x1,x2, theta_1, theta_2,theta_3)
return -np.mean(y * np.log(sigmoid_probs)
+ (1 - y) * np.log(1 - sigmoid_probs))
sigmoid函数和cost函数,使用牛顿法代替梯度下降做逻辑回归。
def gradient(
x_1, x_2, y, theta_1, theta_2, theta_3):
sigmoid_probs = sigmoid(x_1,x_2, theta_1, theta_2,theta_3)
return np.array([np.sum((y - sigmoid_probs) * x_1),
np.sum((y - sigmoid_probs) * x_2),
np.sum(y - sigmoid_probs)])
一阶导数,数据就是二维的,再加上一个偏置值就是三个导数了。
'''calculate hassion matrix'''
def Hassion(
x1, x2, y, theta1, theta2, theta3):
sigmoid_probs = sigmoid(x1,x2, theta1,theta2,theta3)
d1 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x1 * x1)
d2 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x1 * x2)
d3 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x1 )
d4 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x2 * x1)
d5 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x2 * x2)
d6 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x2 )
d7 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x1 )
d8 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x2 )
d9 = np.sum((sigmoid_probs * (1 - sigmoid_probs)))
H = np.array([[d1, d2,d3],[d4, d5,d6],[d7,d8,d9]])
return H
方法比较笨,直接一个一个迭代。
'''update parameter by newton method'''
def newton_method(x1, x2, y):
#initialize parameter
theta1 = 0.001
theta2 = -0.4
theta3 = 0.6
delta_loss = np.Infinity
loss = cost(x1, x2, y, theta1, theta2, theta3)
kxi = 0.0000001
max_iteration = 10000
i = 0
print('while i = ', i, ' Loss = ', loss, 'delta_loss = ', delta_loss)
while np.abs(delta_loss) > kxi and i < max_iteration:
i += 1
g = gradient(x1, x2, y, theta1, theta2, theta3)
hassion = Hassion(x1, x2, y, theta1, theta2, theta3)
H_inverse = np.linalg.inv(hassion)
delta = H_inverse @ g.T
delta_theta_1 = delta[0]
delta_theta_2 = delta[1]
delta_theta_3 = delta[2]
theta1 += delta_theta_1
theta2 += delta_theta_2
theta3 += delta_theta_3
loss_new = cost(x1, x2, y, theta1, theta2, theta3)
delta_loss = loss - loss_new
loss = loss_new
print('while i = ', i, ' Loss = ', loss, 'delta_loss = ', delta_loss)
return np.array([theta1, theta2, theta3])
运行函数。
def get_param_target(self):
np.random.seed(12)
num_observations = 5000
x1 = np.random.multivariate_normal([0, 0], [[1, .75], [.75, 1]], num_observations)
x2 = np.random.multivariate_normal([1, 4], [[1, .75], [.75, 1]], num_observations)
simulated_separableish_features = np.vstack((x1, x2)).astype(np.float32)
simulated_labels = np.hstack((np.zeros(num_observations),
np.ones(num_observations)))
return (simulated_separableish_features[:, 0], simulated_separableish_features[:, 1], simulated_labels)
生成数据。


对于牛顿法的这个问题还是有改进方法的。对于
线搜索
步长最小化意味着 ,
, 就是方向了,这里的
就是方向了,这里的 都是常数,所以可以看做是一个的函数。
都是常数,所以可以看做是一个的函数。
二分搜索算法



假设 ,如果是一个凸函数,需要
,如果是一个凸函数,需要 ,因为
,因为 ,p就当前的梯度下降的方向,所以向着梯度的反方向得:
,p就当前的梯度下降的方向,所以向着梯度的反方向得: ,假如我们知道一个
,假如我们知道一个 ,那么就可以知道肯定有一个
,那么就可以知道肯定有一个 使得
使得 ,所以二分搜索的流程很简单:
,所以二分搜索的流程很简单:
①k = 0, ,
,
② ,如果
,如果
如果
如果 ,否则就继续循环。
,否则就继续循环。
二分搜索也叫精确搜索,因为这样不断的迭代下去是可以很精确的搜索到一个合适的值,使用二分查找法来求步长的计算复杂度很高, 因为在最小化f(x)f(x)的每次迭代中我们都需要执行一次线搜索, 而每次线搜索都要用上述的二分查找算法,因为这个精确的值在一些凸函数里面会是很小很小的,甚至后面多加一个小数,这样算起来复杂度非常高的。我们可以在牺牲一定的精度的条件下来加快计算速度, 回溯线搜索是一种近似线搜索算法。
回溯线搜索
对于上诉二分法的问题,这里提出了改进,牺牲掉一些精度,求一个大概的范围就好,于是有: 上诉条件称为充分下降条件,
上诉条件称为充分下降条件,
 这两个准则就是Armijo-Goldstein准则,①目标函数值应该有足够的下降;②一维搜索的步长α不应该太小。这两个目标其实很明显,足够的下降其实就是式子1:
这两个准则就是Armijo-Goldstein准则,①目标函数值应该有足够的下降;②一维搜索的步长α不应该太小。这两个目标其实很明显,足够的下降其实就是式子1:

为什么
①对于
的选择是一定要在(0,0.5)之间的,如果没有这个条件,会影响算法的超线性收敛性。这个怎么收敛的我就不知道了,还得看看其他的凸优化书籍。
②做泰勒展开,
,去掉高阶无穷小,
,和上式就是相差了一个
而已,这样就保证了小于的这个条件。
③由于,所以
,而且
,所以有
,这就保证了a不能太小

综上,这就得到了Armijo-Goldstein准则。后面用的Armijo搜索只是用了第一条式子进行搜索。
阻尼牛顿法
回到刚刚的牛顿法,提到有可能会存在Hession Matrix不是正定的情况,我们可以加一点阻碍,也就是加上一个步长的限制,这个步长就是由Arimji搜索得到,这里只是会用到第一条准则,第二三条先不用。
class DampedNewton(object):
def __init__(self, feature, label, iterMax, sigma, delta):
self.feature = feature
self.label = label
self.iterMax = iterMax
self.sigma = sigma
self.delta = delta
self.w = None
def get_error(self, w):
return (self.label - self.feature*w).T * (self.label - self.feature*w)/2
def first_derivative(self):
m, n = np.shape(self.feature)
g = np.mat(np.zeros((n, 1)))
for i in range(m):
err = self.label[i, 0] - self.feature[i, ]*self.w
for j in range(n):
g[j, ] -= err*self.feature[i, j]
return g
def second_derivative(self):
m, n = np.shape(self.feature)
G = np.mat(np.zeros((n, n)))
for i in range(m):
x_left = self.feature[i, ].T
x_right = self.feature[i, ]
G += x_left * x_right
return G
def get_min_m(self, d, g):
m = 0
while True:
w_new = self.w + pow(self.sigma, m)*d
left = self.get_error(w_new)
right = self.get_error(self.w) + self.delta*pow(self.sigma, m)*g.T*d
if left <= right:
break
else:
m += 1
return m
def newton(self):
n = np.shape(self.feature)[1]
self.w = np.mat(np.zeros((n, 1)))
it = 0
while it <= self.iterMax:
g = self.first_derivative()
G = self.second_derivative()
d = -G.I * g
m = self.get_min_m(d, g)
self.w += pow(self.sigma, m) * d
if it % 100 == 0:
print('it: ', it, ' error: ', self.get_error(self.w)[0, 0])
it += 1
return self.w
求海塞矩阵换了一个写法,好看一点,但是效果都是一样的。
线性回归的损失函数:
线性回归的一阶导数:
线性回归的二阶导数:
对照上面的公式是可以一一对应的。对于Armrji搜索只是用了第一条公式:一旦超过这个限制就可以退出了。

到这里线搜索还没有完。
Wolfe-Powell准则
有Armijo-Goldstein准则还是不够的,如下图:

Wolfe-Powell准则也有两个表达式,第一个表达式就是

 倍。,而初始点( α=0 的点)处的切线是比 e 点处的切线要“斜”的,由于
倍。,而初始点( α=0 的点)处的切线是比 e 点处的切线要“斜”的,由于



线搜索的总结
线搜索到这里基本就结束了。寻找一个最佳步长就是要求优化之后的函数值是要最小的,于是给出的目标函数就是:。解决这个问题有两种方法,一种就是二分法的查找,这种方法可能非常的精确搜索到一个最佳的值,但是他的计算复杂度有点高;有时候我们其实不太需要太过精确的值,我们只是需要一个大概模糊的就好了,于是出现了回溯搜索,这是属于模糊搜索,给出的就是Armijo-Goldstein准则,但是这两个准则也有不好的地方,有时候会把极值点排除在外,于是引入曲率条件,把Armijo-Goldstein准则的第二条式子换掉,就出现了Wolfe-Powell准则,条件再强一点两边加上绝对值,这样就出现了最终的Wolfe-Powell准则。
对于步长的研究并不针对某一个算法,对于优化下降的算法都可以使用,梯度下降,牛顿法,拟牛顿法都可以用到,具有很强的普适性。梯度下降的步长也是可以通过这种方式进行选择最优步长,牛顿法用Armijo搜索的方法是可以得到全局牛顿法,也叫阻尼牛顿法,这样可以使得迭代方向可以避免向错误的方向进行,增加点阻力。
这篇文章主要的研究对象还是牛顿法,所以下面的三个算法分别就是DFP,BFGS,LBFGS。
DFP
前面的阻尼牛顿法解决的就是对于迭代方向的问题,但是对于计算复杂度这个问题还没有得到解决,因为矩阵求拟是一个很大的工程量,如果维度一多是计算复杂度是很大的,所以拟牛顿法基本上都是构造一个和Hession矩阵相似的矩阵来替代。但是问题来了,用近似矩阵替代,效果可能会不好,给出如下证明:
首先由牛顿法可以得到:



由于 ,所以右边也是要求小于0,那么自然就是大于0了,这也就证明了Hession矩阵的正定性。在逐步寻找最优解的过程中要求函数值是下降的,但是有时候Hession矩阵不一定是半正定的,可能会使得函数值不降反升。 拟牛顿法可以使目标函数值沿下降方向走下去,并且到了最后,在极小值点附近,可使构造出来的矩阵与Hesse矩阵“很像”了,这样,拟牛顿法也会具有牛顿法的二阶收敛性。
,所以右边也是要求小于0,那么自然就是大于0了,这也就证明了Hession矩阵的正定性。在逐步寻找最优解的过程中要求函数值是下降的,但是有时候Hession矩阵不一定是半正定的,可能会使得函数值不降反升。 拟牛顿法可以使目标函数值沿下降方向走下去,并且到了最后,在极小值点附近,可使构造出来的矩阵与Hesse矩阵“很像”了,这样,拟牛顿法也会具有牛顿法的二阶收敛性。
推导证明
涉及到Hession矩阵,自然就涉及到二阶导数矩阵了,Hession矩阵只是对于多变量二阶导数的一种描述方式。Taylor展开: 还是用二次导数做近似,很多函数都可以用二次导数做近似。去掉高次项两边求导数:
还是用二次导数做近似,很多函数都可以用二次导数做近似。去掉高次项两边求导数:
上面那个方程就是拟牛顿方程。上面那个矩阵就是一个近似矩阵。近似矩阵有很多种,如果按照上面那种方式进行计算,复杂度没有降多少,所以比较常见的方法就是迭代计算,比较常见的迭代方式:
那么接下来问题来了, 要这么设计。一般给出的设计就是
要这么设计。一般给出的设计就是 因为希望每次迭代h能有一个微小的变化而不是巨大的变化,这样才有可能收敛。而且这个结构设计的也很简单,也是对称的。
因为希望每次迭代h能有一个微小的变化而不是巨大的变化,这样才有可能收敛。而且这个结构设计的也很简单,也是对称的。
代入上面的拟牛顿方程: 仔细看一下这个式子,右边的
仔细看一下这个式子,右边的 是一个nx1的向量,而
是一个nx1的向量,而 均为实数,也就是点积。可以直接假设
均为实数,也就是点积。可以直接假设 ,于是有
,于是有 。
。
代入上面的式子: 一开始我看到这个推导过程,我是一脸懵逼的。原来数学家也有猜的时候,这个过程和前面假设H的形式在凸优化里面,是用"很显然"来描述的,嗯,很显然!我就是他妈的没看出来显然在哪了,后面的LBFGS也是,真的很显然,但是这个我是真的不知道。看到网上的很多解释都离不开特殊情况,也就是为0或者是直接假设
一开始我看到这个推导过程,我是一脸懵逼的。原来数学家也有猜的时候,这个过程和前面假设H的形式在凸优化里面,是用"很显然"来描述的,嗯,很显然!我就是他妈的没看出来显然在哪了,后面的LBFGS也是,真的很显然,但是这个我是真的不知道。看到网上的很多解释都离不开特殊情况,也就是为0或者是直接假设 的,都差不多的解释。
的,都差不多的解释。
已知初始正定矩阵H,从一个初始点开始(迭代),用式子  来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序中止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序中止条件。
来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序中止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序中止条件。
所以整一个流程:
①给定一个初值
②搜索方向:
③利用搜索得到步长,可以使用上面提到的Armrji搜索或者等等的改进方法。
④更新一波
⑤计算
⑥,转回去继续更新。
DFP还是有缺点的:

BFGS
BFGS和DFP其实是属于对偶的解法,一个直接求海赛矩阵逆矩阵(DFP),另一个就是求海赛矩阵(BFGS)。还是使用拟牛顿公式: ,而DFP使用的是
,而DFP使用的是 ,直接求出来的就是逆矩阵了。推导过程其实很简单,和上面DFP类似,差别不大,甚至除了换一下没什么差别的。
,直接求出来的就是逆矩阵了。推导过程其实很简单,和上面DFP类似,差别不大,甚至除了换一下没什么差别的。
推导证明
假设都和上面DFP的一样。还是 ,E就是矫正矩阵。E的形式和之前的是一样的。代入上面的公式:
,E就是矫正矩阵。E的形式和之前的是一样的。代入上面的公式: 同样假设
同样假设 ,同样选取特殊情况,
,同样选取特殊情况, ,代进矫正函数的表达式:
,代进矫正函数的表达式: 仔细看一些这个式子,和DFP那个式子是换了一下位置而已,所以这个过程和步骤真的没有什么好说的。按照常规套路,一般是这样:
仔细看一些这个式子,和DFP那个式子是换了一下位置而已,所以这个过程和步骤真的没有什么好说的。按照常规套路,一般是这样:
所以整一个流程:
①给定一个初值
②搜索方向:
③利用搜索得到步长,可以使用上面提到的Armrji搜索或者等等的改进方法。
④更新一波
⑤计算
⑥ ,转回去继续更新。
,转回去继续更新。
然而,如果是这样,复杂度还是存在的,还是得求个导数啊。所以这样的做法自然是不行的,因为拟牛顿法的改进有一个很重要的诱因就是计算复杂度的问题了。
对于求逆矩阵,有一个非常重要的公式——Sherman-Morrison公式:
用Sherman-Morrison公式改造一下: 至于是怎么改造的,有兴趣自己看吧,原谅我并没有看懂,懂了我也想不出来。
至于是怎么改造的,有兴趣自己看吧,原谅我并没有看懂,懂了我也想不出来。
根据这个结果改造一下:
所以整一个流程:
①给定一个初值
②搜索方向:
③利用搜索得到步长,可以使用上面提到的Armrji搜索或者等等的改进方法。
④更新一波
⑤计算
⑥,转回去继续更新。
完美的达到了降低复杂度的目标。但是我还是不知道BFGS为什么相对DFP来说对于纠正方向要更快一点。这两个是对偶式子,难到是因为用了Sherman-Morrison公式吗?
代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from DataProcesser import DataProcesser
def bfgs(feature, label, lam, maxCycle):
n = np.shape(feature)[1]
w0 = np.mat(np.zeros((n, 1)))
rho = 0.55
sigma = 0.4
Bk = np.eye(n)
k = 1
while (k < maxCycle):
print('Iterator: ', k, ' error: ', get_error(feature, label, w0))
gk = get_gradient(feature, label, w0, lam)
dk = np.mat(-np.linalg.solve(Bk, gk))
m = 0
mk = 0
while (m < 20):
newf = get_result(feature, label, (w0 + rho**m*dk), lam)
oldf = get_result(feature, label, w0, lam)
if (newf < oldf + sigma * (rho ** m)*(gk.T*dk)[0, 0]):
mk = m
break
m += 1
#BFGS
w = w0 + rho**mk * dk
sk = w-w0
yk = get_gradient(feature, label, w, lam) - gk
if (yk.T * sk > 0):
Bk = Bk - (Bk * sk * sk.T * Bk) / (sk.T * Bk * sk) + (yk * yk.T) / (yk.T * sk)
k = k + 1
w0 = w
return w0
def get_error(feature, label, w):
return (label - feature * w).T*(label - feature * w)/2
def get_gradient(feature, label, w, lam):
err = (label - feature * w).T
left = err * (-1) * feature
return left.T + lam * w
def get_result(feature, label, w, lam):
left = (label - feature * w).T * (label - feature * w)
right = lam * w.T * w
return (left + right)/2
最主要的部分也就是公式那部分了,没有什么好讲的。实现效果:


L-BFGS
L-BFGS的出现还是为了节省,但这次是为了节省内存。每一次存储高纬度的数据需要的空间太多了,所以LBFGS的主要作用就是减少内存的开销。不再完整的存储整一个矩阵了,它对BFGS算法做了近似,而是存储计算时所需要的 ,然后利用哪两个向量的计算来近似代替。对于也不是存储所有的,而是只保存那么后面的m个,也就是最新的m个就好。这样就把空间复杂度
,然后利用哪两个向量的计算来近似代替。对于也不是存储所有的,而是只保存那么后面的m个,也就是最新的m个就好。这样就把空间复杂度 降到
降到 。
。
毫无疑问,LBFGS是从BFGS演化而来的。对于逆矩阵的公式:
假设 ,改造一下上式:
,改造一下上式:
假设:
递推一下:

根据推论,一般的有:
可以看的出,当前的海赛矩阵的逆矩阵是可以由 给出的,所以直接存储对应的
给出的,所以直接存储对应的 即可,上面提到过为了压缩内存,可以只是存储后面的m个,所以更新一下公式:
即可,上面提到过为了压缩内存,可以只是存储后面的m个,所以更新一下公式:
公式长是有点长,但是已经有大神给出了一个很好的算法解决这个问题,two-loop-recursion算法:




end for





这个式子到底行不行呢?证明一下理论:




这样就证明这个算法的正确性。然而其实我根本不关心这个算法正确性,我只是想知道
这是怎么想出来的,说实话第一眼看根本没有get到这个算法就是实现了LBFGS,所以如果有大神知道麻烦私信我!渣渣感激不尽。
按照上面算法得到方向之后就可以使用线搜索得到合适的步长最后结合更新了。
代码实现
前面求梯度都一样的,就是后面的更新有不同:
def lbfgs(feature, label, lam, maxCycle, m = 10):
n = np.shape(feature)[1]
w0 = np.mat(np.zeros((n, 1)))
rho = 0.55
sigma = 0.4
H0 = np.eye(n)
s = []
y = []
k = 1
gk = get_gradient(feature, label, w0, lam)
dk = -H0 * gk
while (k < maxCycle):
print('iter: ', k, ' error:', get_error(feature, label, w0))
m1 = 0
mk = 0
gk = get_gradient(feature, label, w0, lam)
while (m1 < 20):
newf = get_result(feature, label, (w0 + rho ** m1 * dk), lam)
oldf = get_result(feature, label, w0, lam)
if newf < oldf + sigma * (rho ** m1) * (gk.T * dk)[0, 0]:
mk = m1
break
m1 = m1 + 1
w = w0 + rho ** mk * dk
if k > m:
s.pop(0)
y.pop(0)
sk = w - w0
qk = get_gradient(feature, label, w, lam)
yk = qk - gk
s.append(sk)
y.append(yk)
t = len(s)
a = []
for i in range(t):
alpha = (s[t - i -1].T * qk) / (y[t - i - 1].T * s[t - i - 1])
qk = qk - alpha[0, 0] * y[t - i -1]
a.append(alpha[0, 0])
r = H0 * qk
for i in range(t):
beta = (y[i].T * r) / (y[i].T * s[i])
r = r + s[i] * (a[t - i - 1] - beta[0, 0])
if yk.T * sk > 0:
dk = -r
k = k + 1
w0 = w
return w0


数据比较少,所以效果差别都不大。
总结
首先提到的是梯度下降,梯度下降算法虽然很简单,但是下降的方向会有所偏差,可能胡局部不稳定,速度不会特别快,但是最终是会到达终点。于是改进一下,梯度下降是一阶拟合,那么换牛顿法二阶拟合,但是牛顿法问题来了,迭代的方向有可能是错误的,所以改进一下,加点阻力,就算是不准确的,用linear search也可以调整一下。但是对于阻尼牛顿法还是存在了计算复杂度的问题,于是改进一下,用DFP直接做近似逆矩阵,达到了降低复杂度的问题,但是对于方向梯度的问题还是不是特别好,于是又出来了BFGS,用了比较牛逼的Sherman-Marrion公式求出了逆矩阵。问题又来了,每次都存储这么大的矩阵,有没有办法降低一些呢?于是改进了一下,就出现了LBFGS,用两个nx1的矩阵来表示逆矩阵,并且只存储后m个更新的内容,改进一下出现了two-loop-recursion算法。后面又继续改进了一下。这部分的知识比较靠近数值优化我心脏已经受不了了。
GitHub代码:https://github.com/GreenArrow2017/MachineLearning/tree/master/MachineLearning/Linear%20Model/LogosticRegression/LinearRegaression