

分不清谭卓和郝蕾?各来200张照片,让深度学习帮我们识别吧。
问题
《如何用Python和深度神经网络识别图像?》一文中,我给你展示了如何用深度学习,教电脑区分机器人瓦力和哆啦a梦。
很快就有用户在后台留言,问:
老师,我想自己训练一个图片分类器,到哪里去批量下载带标注的训练图像呢?
说说我写教程的时候,是如何找图片的吧。
最大的图片库,当然就是 Google 了。
在 Google 图像栏目下,键入"Walle"。
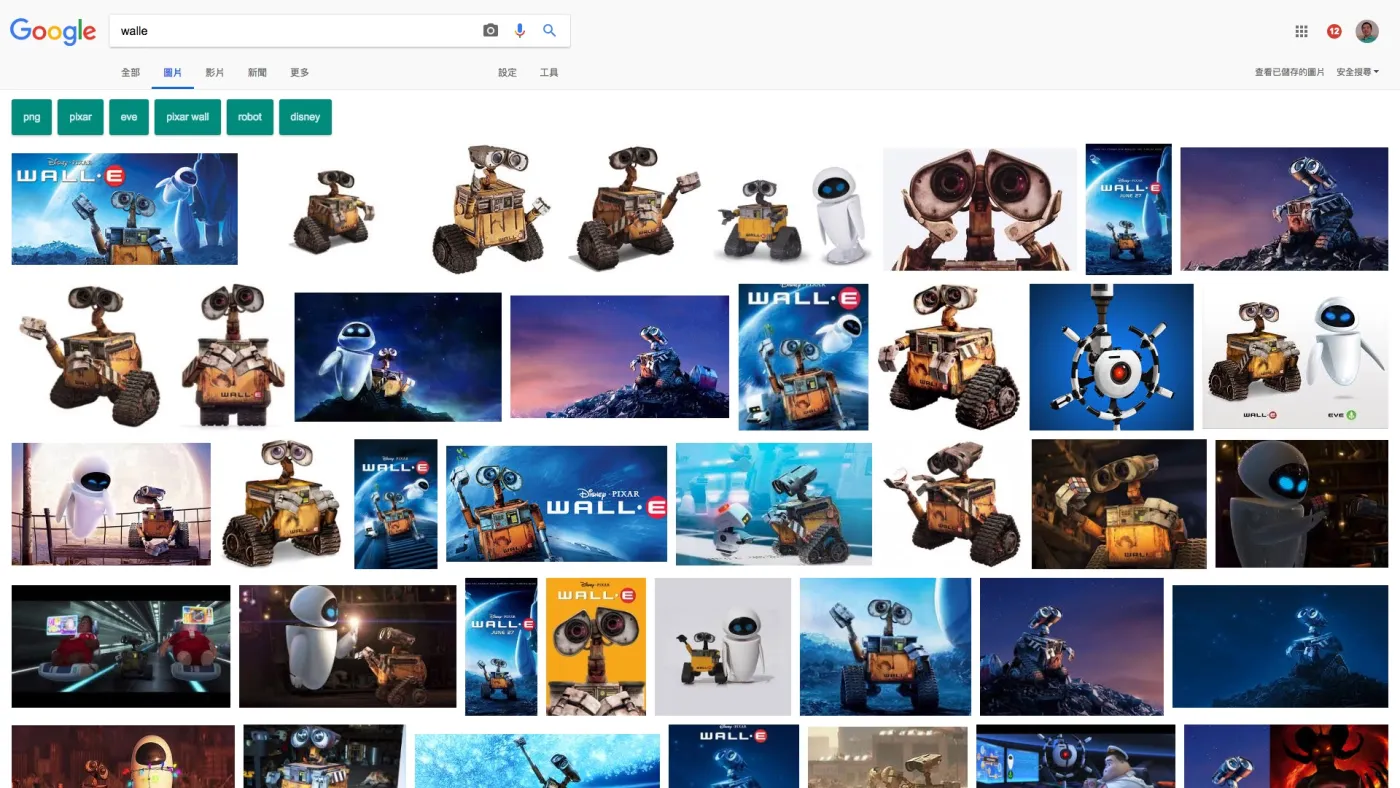
怎么样?搜索结果很符合需求吧。
你不但找到了一批高质量图片,而且它们的标注, Google 都帮你打好了。
下面一步,自然就是把这些图片下载下来了。
我让学生实际动手做,每个人找两个与别人不同的图像集合,尝试根据教程做深度学习分类。
我提供给他们的方案(几款不同的 Chrome 浏览器插件),效果都不好。
有的才下了几张,就停工,甚至把浏览器整崩溃了。
有的下载图片,都是重复的。
学生告诉我,经验证,最简单有效的方法,是一张张手动点击下载……
这显然不是正经办法。
痛点
渴望从 Google 图片库高效批量获得优质带标注图像,不会是个案。
这个大众痛点,真的没有人尝试解决吗?
今天,一个偶然的机会,我发现了一个特别棒的 Github 项目,叫做 google-images-download。
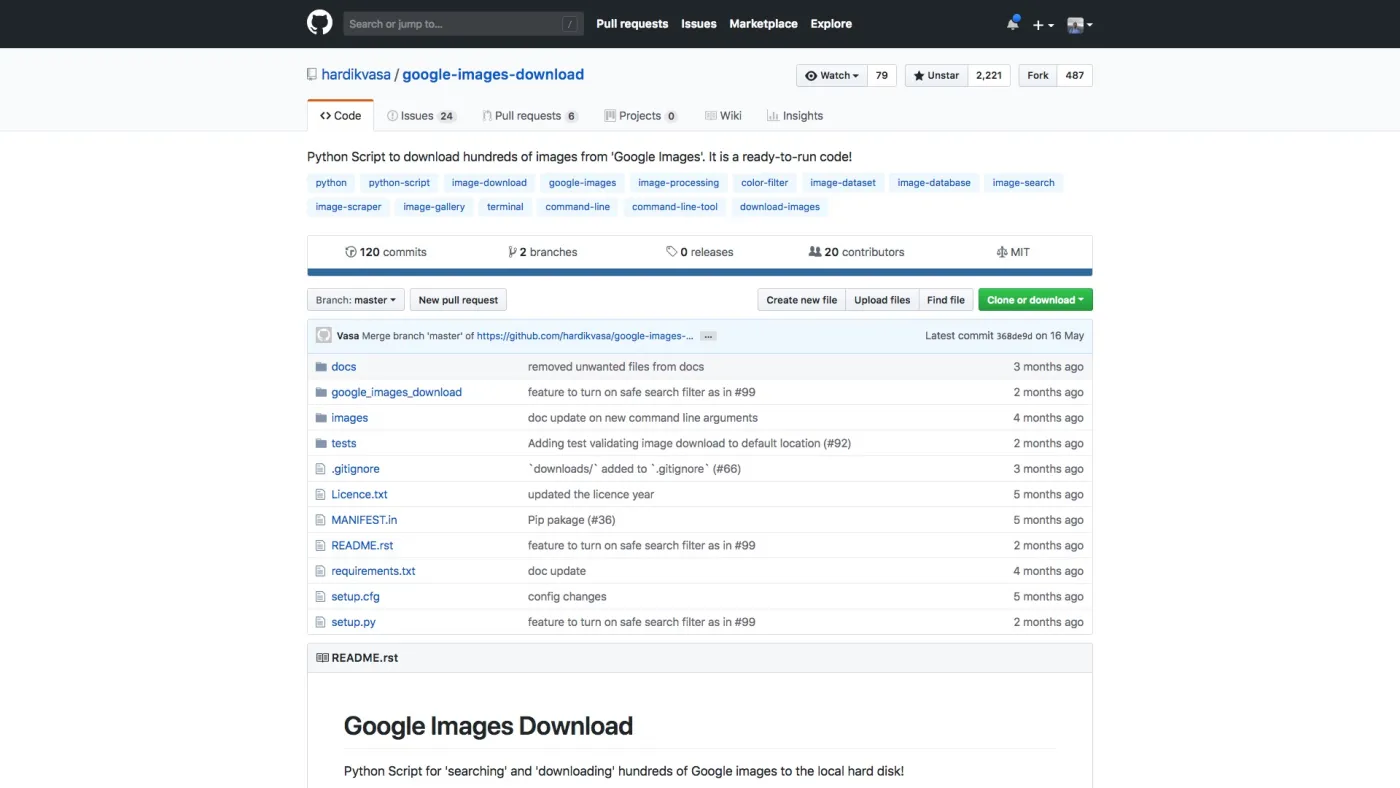
Github repo 链接在这里。
项目发布至今,只有短短5个月的时间,星标数量居然已经上了2000,看来确实非常受欢迎。
google-images-download 是个 Python 脚本。
使用它,你可以一条命令,就完成 Google 图片搜索和批量下载功能。
而且,这工具还跨平台运行,Linux, Windows 和 macOS 都支持。
简直是懒人福音。
安装
google-images-download 安装很简单。
以 macOS 为例,只需要在终端下,执行以下命令:
pip install google_images_download
安装就算完成了。
当然,这需要你系统里已经安装了 Python 环境。
如果你还没有安装,或者对终端操作命令不太熟悉,可以参考我的《如何安装Python运行环境Anaconda?(视频教程)》一文,学习如何下载安装 Anaconda ,和进行终端命令行操作。
尝试
进入下载目录:
cd ~/Downloads
我们尝试下载一些图片。
《我不是药神》里面有个叫谭卓的女演员,演的不错。可是我一开始,把她当成郝蕾了。

咱们尝试下载一些谭卓的图片吧。
终端里面执行:
googleimagesdownload -k "谭卓" -l 20
解释一下,这里的 -k 指的是 "keyword",也就是“关键词”,后面用双引号括起来要查找的关键词。
你可以看出,使用中文关键词,也没问题。
后面的 -l ,指的是"limit",也就是图片数量限定,你需要指定自己要下载多少张图像。
本例中,我们要20张。
下面是执行过程:
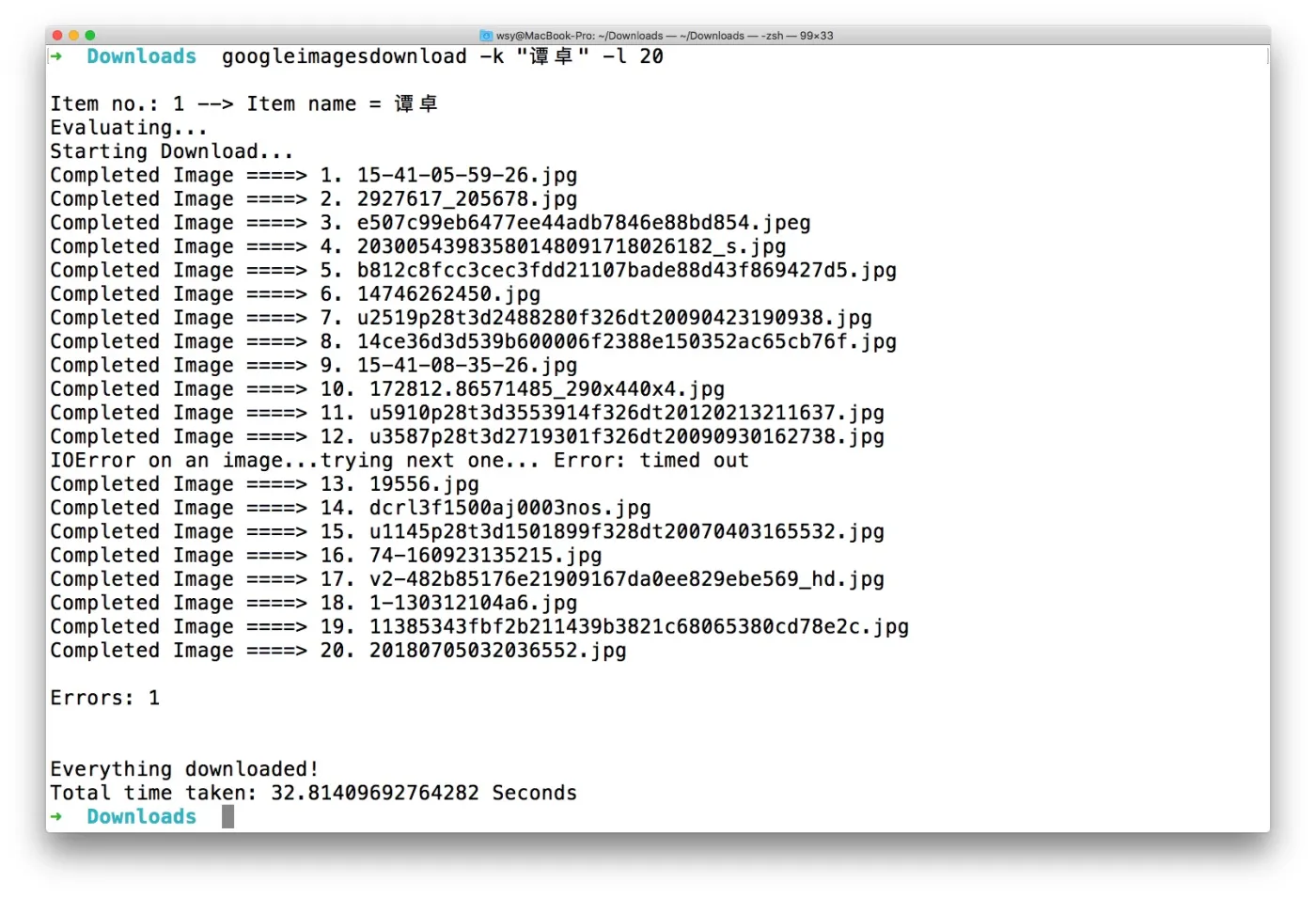
执行完毕。
可以看到,下载过程中,发生了一个错误。
但程序依然锲而不舍,帮我们把下载流程运行完毕。
我们看看结果。
下载的图片都存放在 ~/Downloads/downloads/谭卓 下面,google-images-download 非常贴心地,为我们建立子目录。
我们在 Finder 里打开看看:
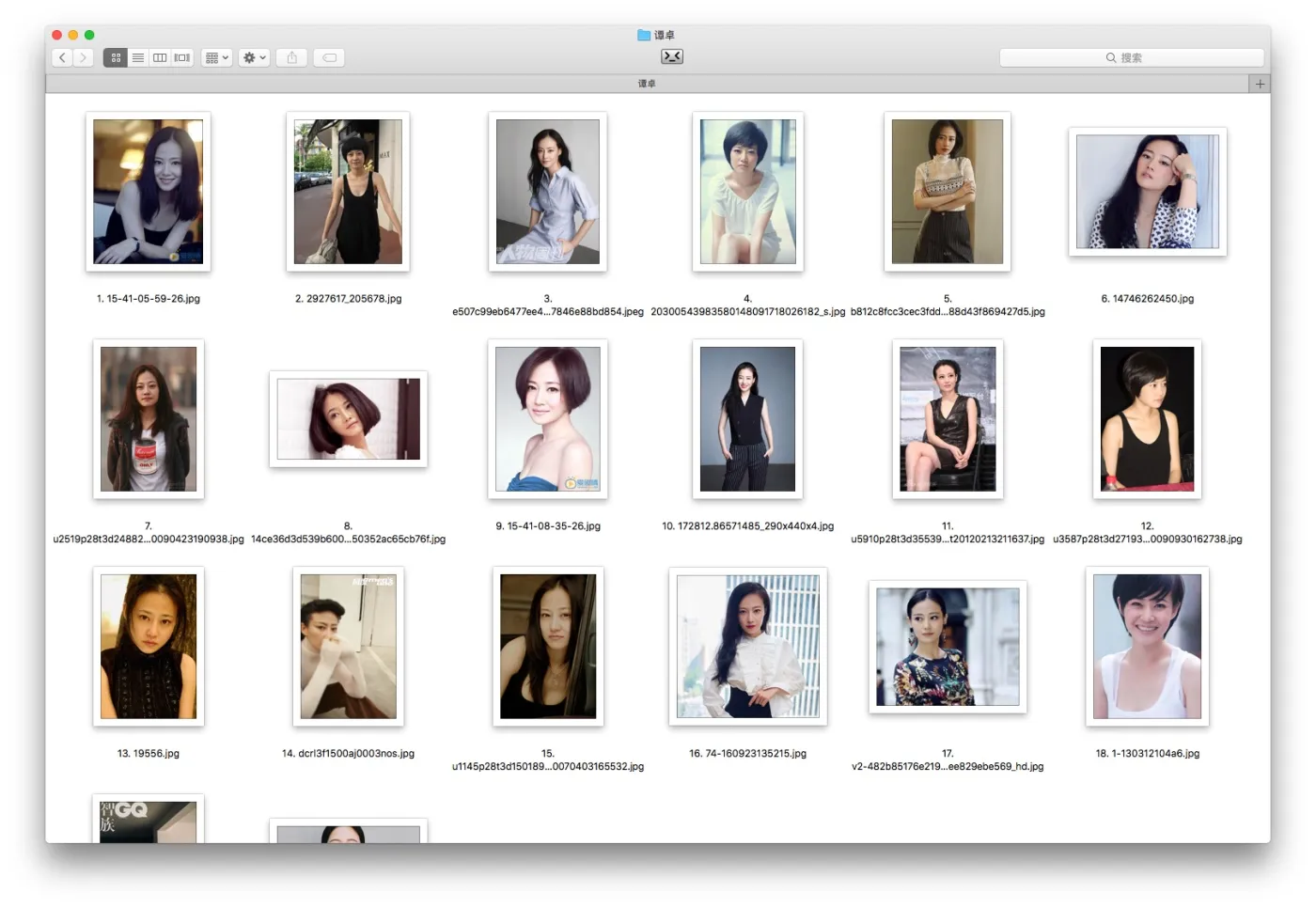
看了半天,有的照片,还是跟郝蕾分不大清楚。
为了彻底分清两位女演员,我们再下载 200 张郝蕾的照片吧。
仿照刚才的命令,我们执行:
googleimagesdownload -k "郝蕾" -l 200
然后……就报错了:

解决
遇到问题,不要慌。
你得认真看看错误提示。
注意其中出现了一个关键词:chromedriver。
这是个什么东西呢?
我们回到 google-images-download 的 github 页面,以 chromedriver 为关键词进行检索。
你会立即找到如下结果:
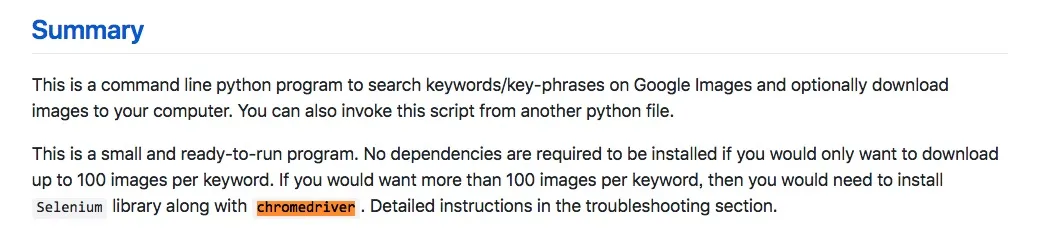
原来如果你要的图片数量超过100张,那么程序就必须调用 Selenium 和 chromedriver 才行。
Selenium 在你安装 google-images-download 的时候,已经自动安装好了。
你只需要下载 chromedriver ,并且指定路径。
下载链接在这里。
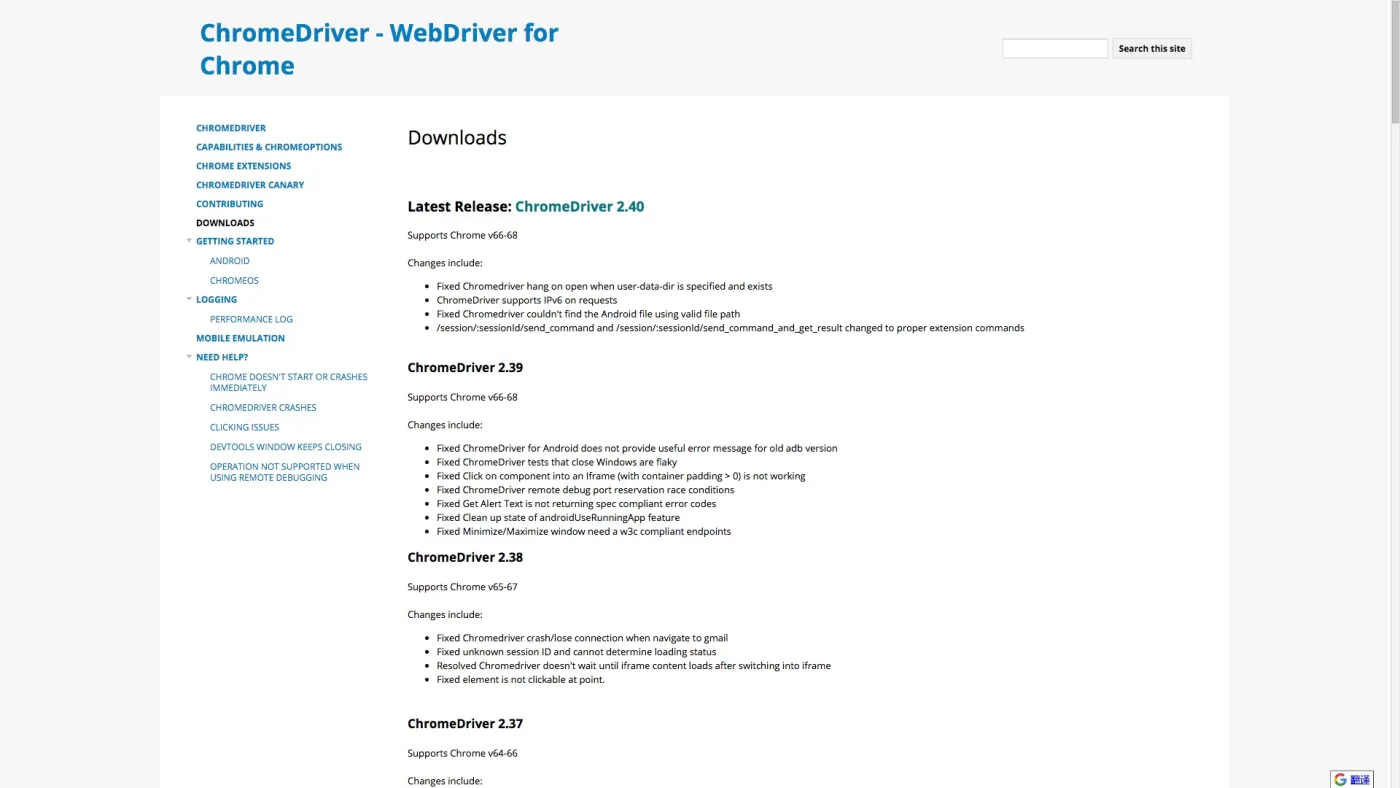
请根据你的操作系统类型,选择合适的版本:

我选的是 macOS 版本。
下载后,压缩包里面只有一个文件,把它解压,放在 ~/Downloads 目录下。
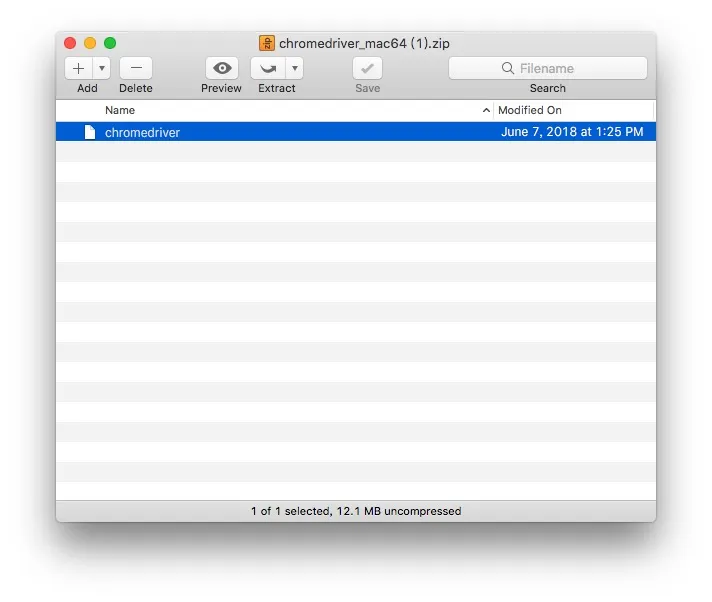
然后,执行:
googleimagesdownload -k "郝蕾" -l 200 --chromedriver="./chromedriver"
这里 --chromedriver 参数,用来告诉 google-images-download ,解压后 chromedriver 所在路径。
这回机器勤勤恳恳,帮我们下载郝蕾的照片了。
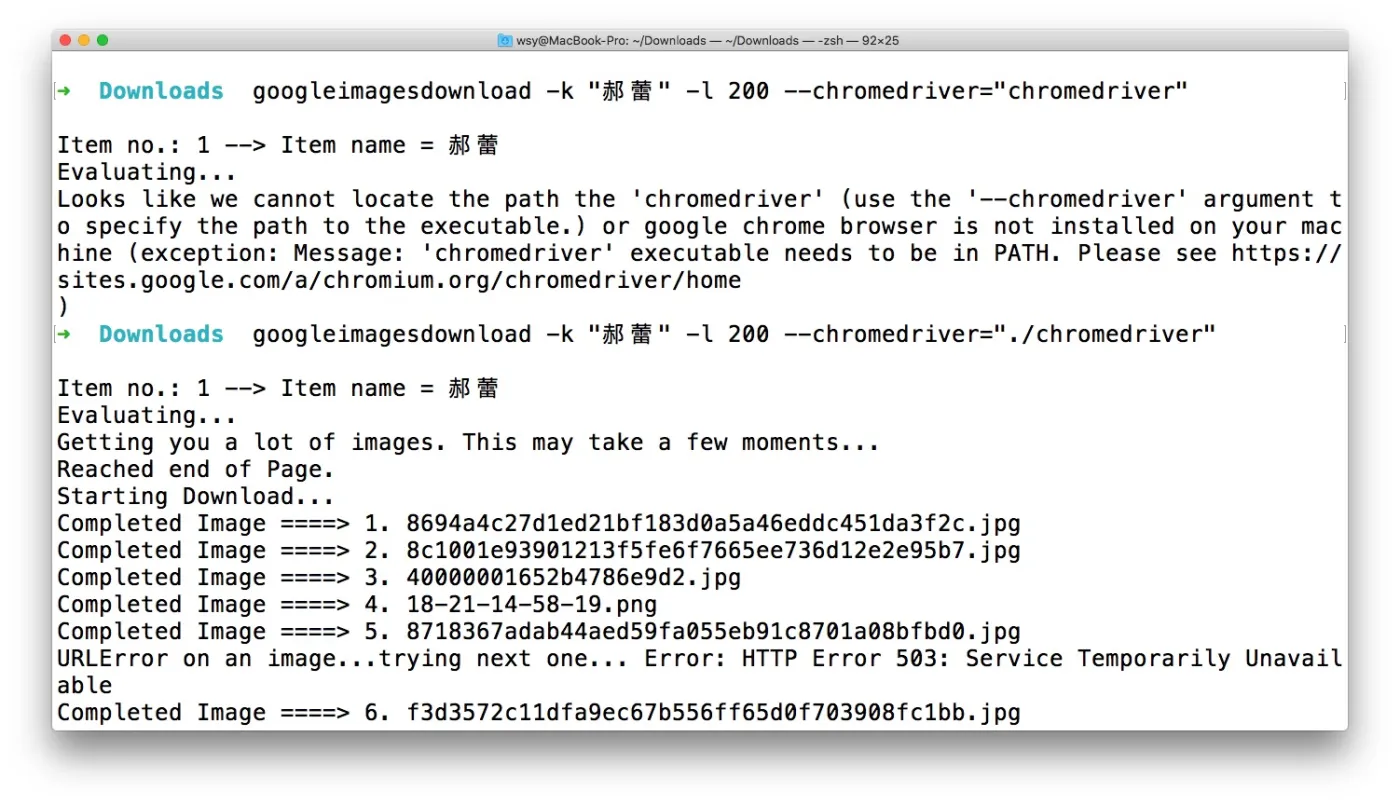
200张图片,需要下载一会儿。请耐心等待。
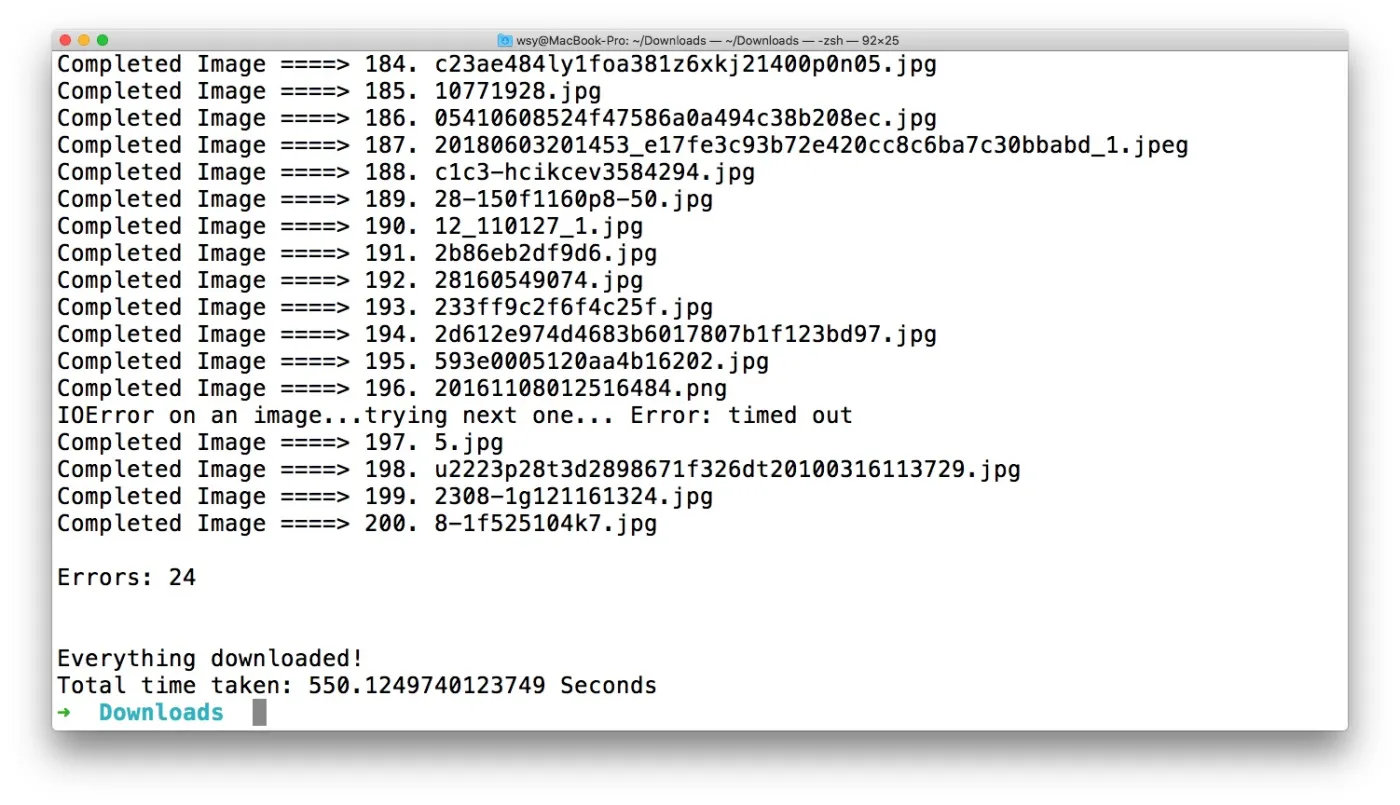
下完了。
中间也有一些报错,部分图片没有正确下载。
好在,这对总体结果没有太大影响。
为了保险起见,建议你设置下载数量时,多设置一些。
给自己留出安全边际嘛。
咱们打开下载后的目录 ~/Downloads/downloads/郝蕾 看看:
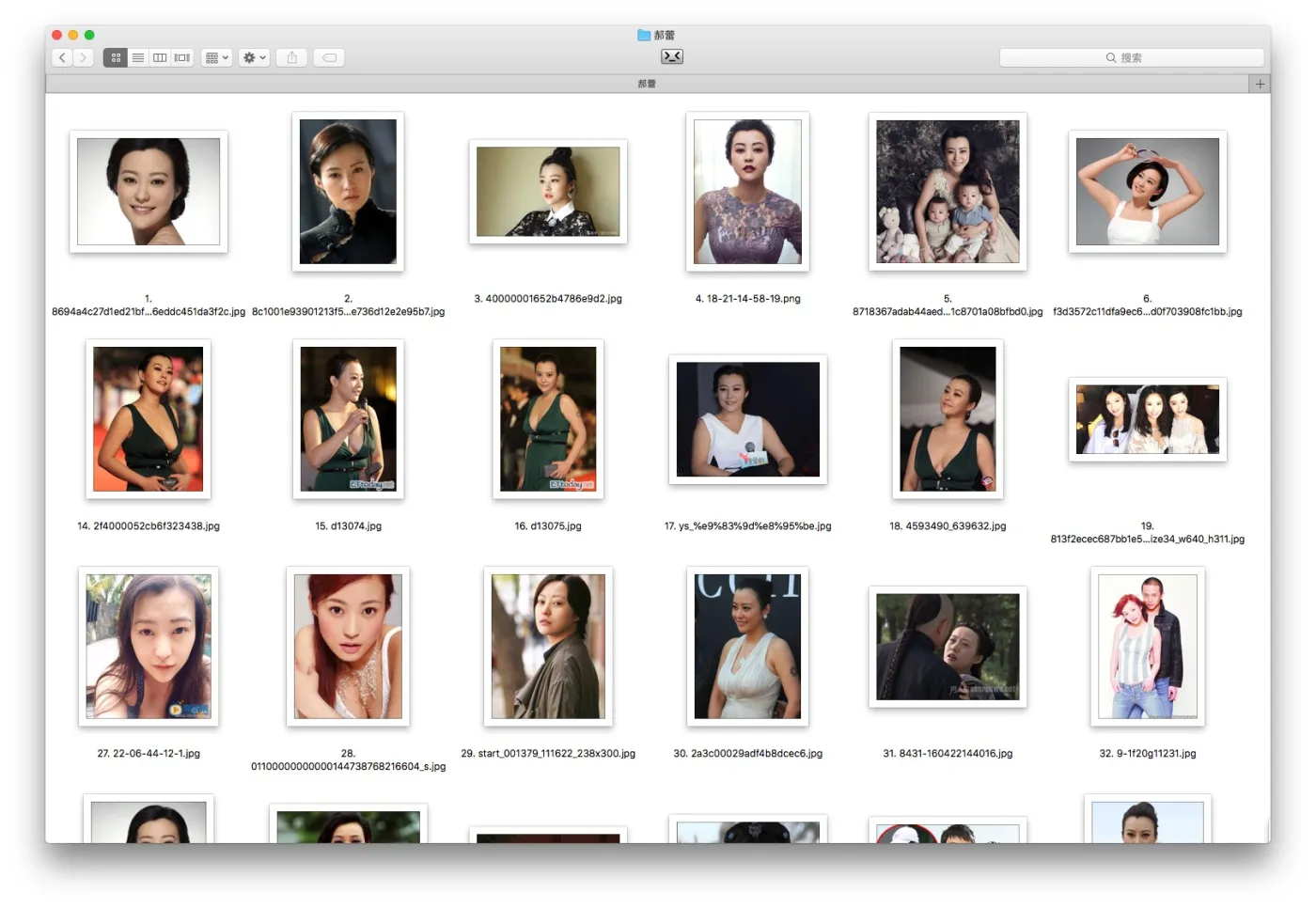
这回,你能分清楚她俩不?
作业
给你留个作业。
你已经学会如何一行命令,下载谭卓和郝蕾的照片。
能否活学活用咱们之前介绍的卷积神经网络知识,用 TuriCreate (或者 Tensorflow) ,建立模型识别两个人的照片?
完成作业后,欢迎把你的测试准确率结果告诉我。
当然,如果你能举一反三,利用咱们今天介绍的脚本,下载其他图像集合,并且进行深度学习训练,就更好了。
也欢迎把结果反馈给我哦。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
