

本文通过一个命令行转换 pdf 为词云的例子,给你讲讲 Python 软件包安装遇挫折时,怎么处理才更高效?
遭遇
前两天,有位读者留言求助。
起因是他读我的《如何用Python做词云?》一文。按照样例成功做出词云后,觉得很兴奋。不过,他不满足于照猫画虎做出结果,找到了 wordcloud 的 github 页面,查看附加功能。
对这一点,我是非常赞赏的。因为这种按图索骥,很多时候,都能有意外收获和惊喜。
例如你偶然读到一篇好文章,于是找到该作者的专栏或者公众号,很大概率就可以读到更多高品质的文章。当年我就是用这种方法,读到阳志平先生和万维钢先生的系列文章,收获颇丰。
同样,一个软件提供了一项你喜欢的功能,你找到它的网站,可能会找到其他感兴趣的功能。甚至有时候,还能发现同一作者的更多优秀工具。
果不其然,这位读者,就找到了一个令自己很兴奋的功能。下图中,我用红线给你标出了这个功能。
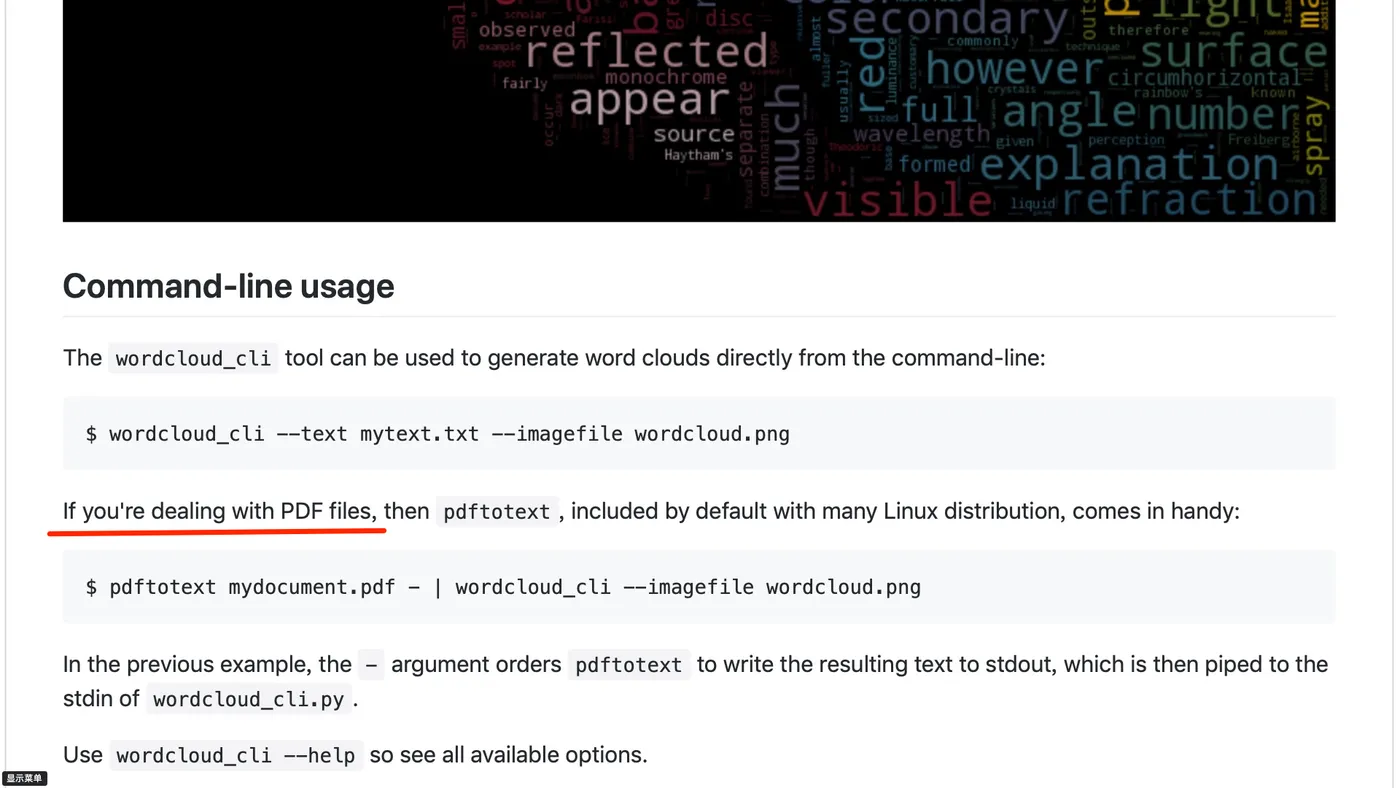
对,wordcloud 不仅可以在 Python 代码中作为模块引入,帮你分析文本,绘制词云;它还可以在命令行方式下,从 pdf 里面直接提取词云出来。
就像这个样子:

我估计,他喜欢这个功能,或许是因为最近读 pdf 格式的论文太多了,想偷个懒吧。
这个操作,只需要终端下面的一行命令。连简单的 Python 编程,都不需要。
他于是兴奋起来,立刻开始尝试这个功能。
然而,这句命令一执行,就报错。提示他的系统里面,没有 pdftotext 。
他于是想,既然 wordcloud ,是需要 pip 命令安装的,那么这个 pdftotext ,看来也需要 pip 安装,对不对?
他尝试执行:
pip install pdftotext
pip 确实找到了这个名称的软件包,开始安装。他瞬间成就感爆棚。
但是,一盆冷水,很快就被泼了下来。
无论如何反复试验,用 pip 安装 pdftotext 这个软件包,总是报错。
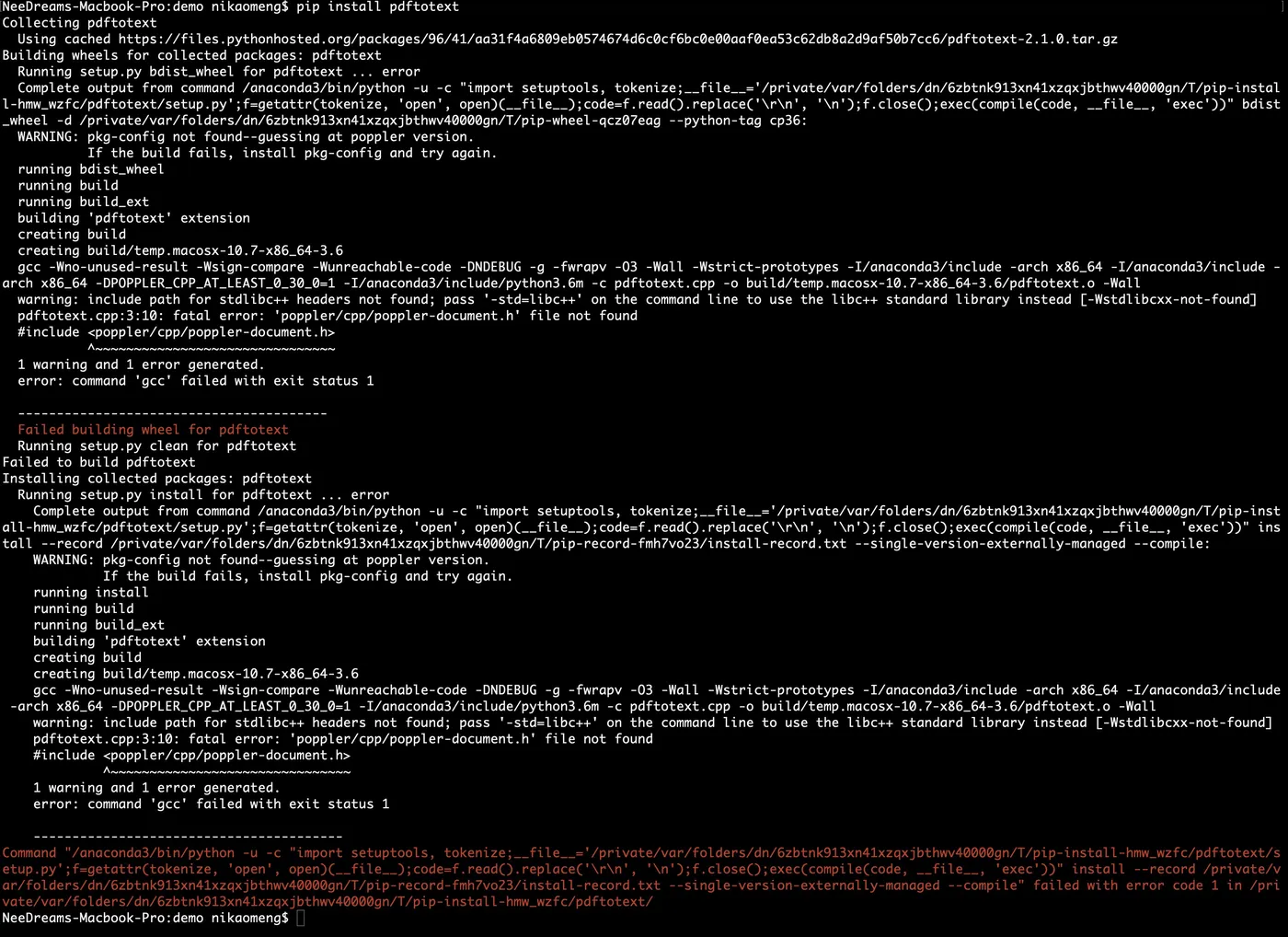
他没有气馁,还专门用搜索引擎查了网上的资料。对于技术问答社区里,类似问题下面提及的每一种可能办法,他都做了尝试。
结果,也无非是报错的提示稍微有了区别,但是问题依旧。
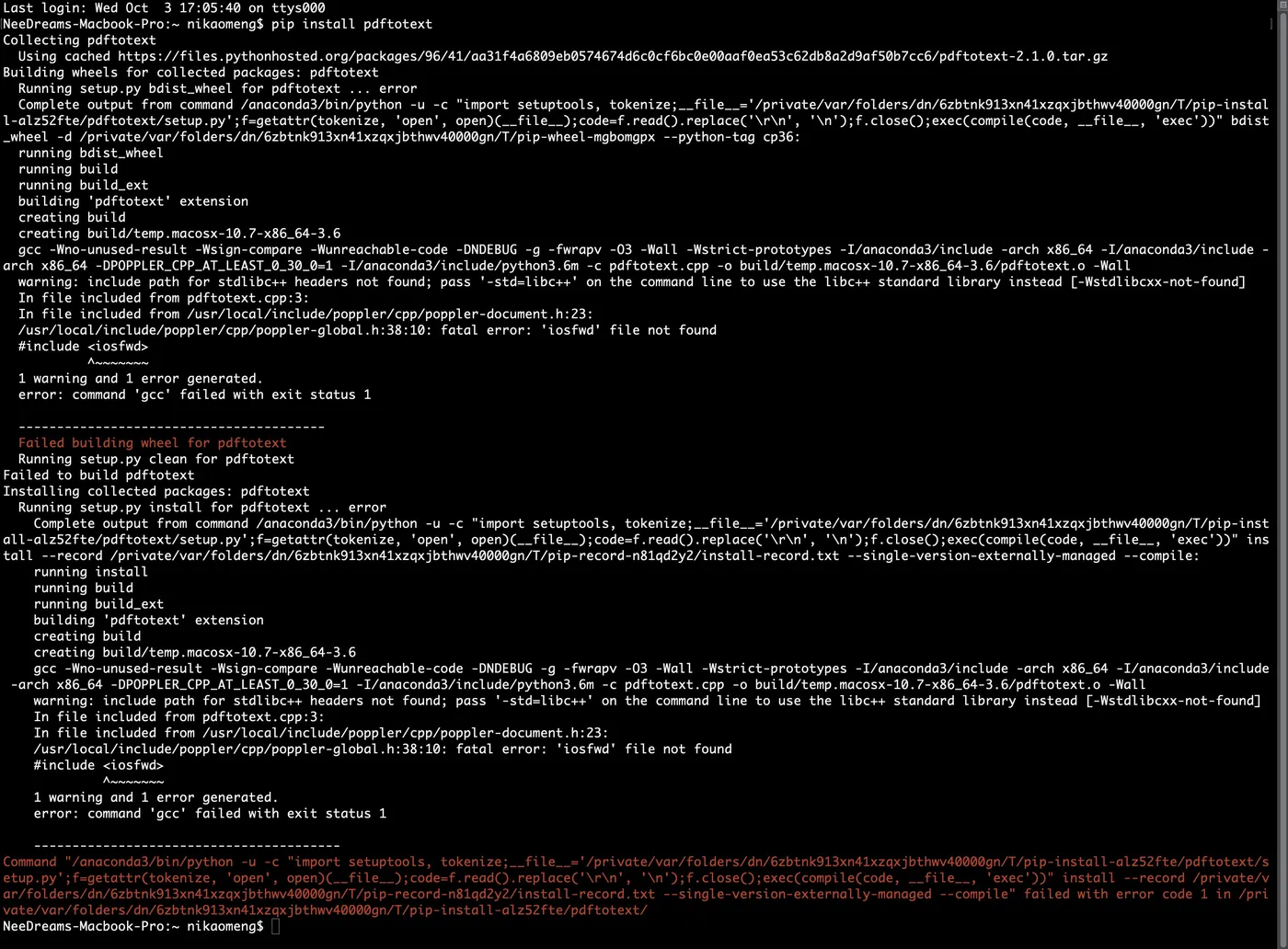
他无计可施了,于是来问我怎么办。
分析
其实,他不该有挫败感。遭遇软件安装困难的时候,能走到他这一步,已经难能可贵。
许多初学者,接触 Python 编程或者命令行操作,往往在自学时,会直接倒在第 0 步,也就是软件安装与环境设置上,直接放弃了。
这位读者求助的,是遇到上图所示的报错时,应该怎么样对应操作,才能让错误消失。
我很愿意帮助他,但不是这个帮法。
因为他从网上找来的这些方法,都没能解决问题。不仅如此,许多操作可能会改变系统环境(例如安装了不同版本的依赖包,或者编译工具等)。这些操作,可能致使现在想回到问题的初始状态,都回不去了。
同一个报错,背后可能有若干种原因。这就是为什么你电脑坏了,往往无法通过电话或者网上技术支持来解决,得需要现场处理,才能让维修人员充分掌握具体情况,做出正确的处理。
当然,报错搞不定,并不意味着问题无法有效解决。
还记得我那篇《什么是第一性原理?》吗?我开门见山地告诉你,应该尝试:
将事情缩减至其根本实质。
你的目的,不应该是跟报错信息较劲,而应该弄明白,到底出了什么问题。
出问题的包,是 pdftotext 对吧?
那你试试,在 github 上搜索一下,它对应的 repo 页面。
你很容易就找到这个网址。
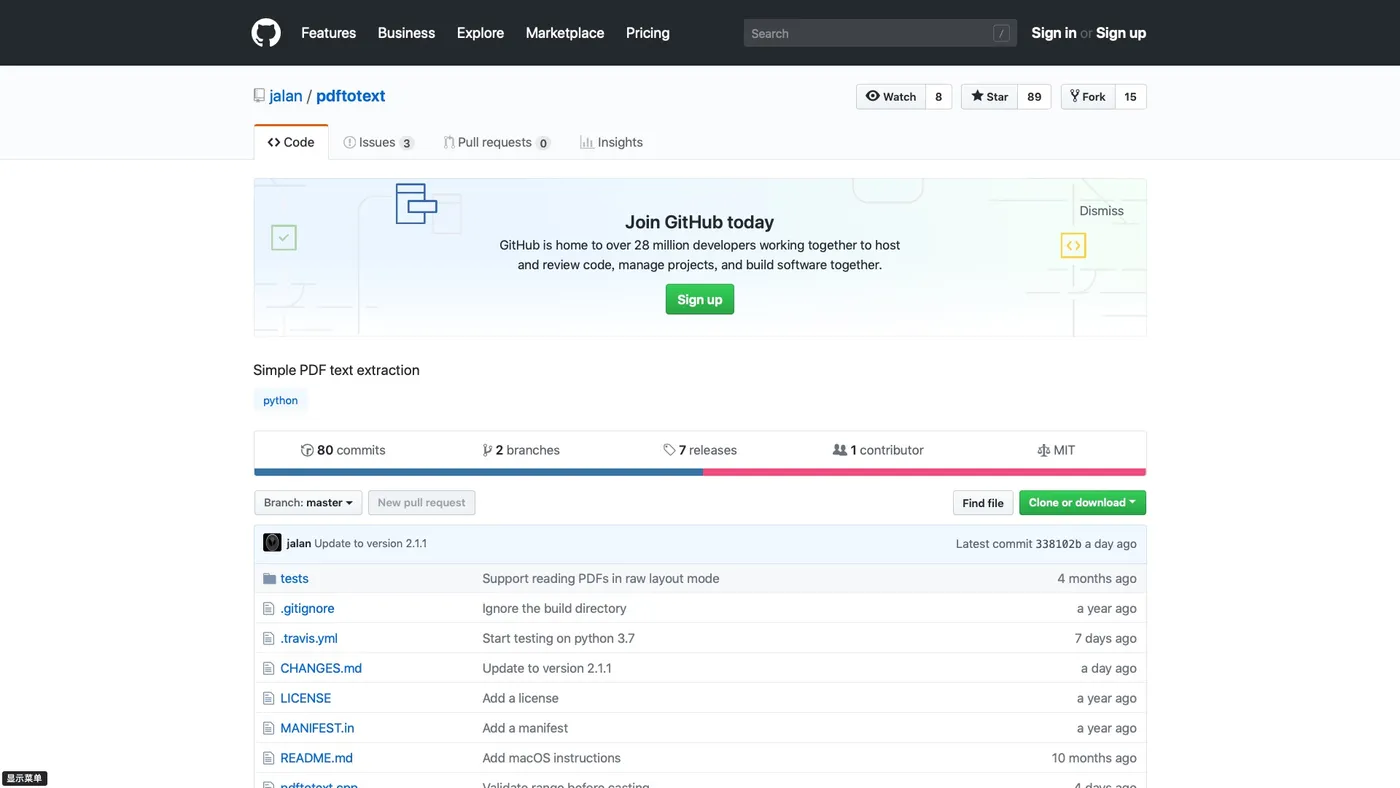
下面请你下拉页面,看跟安装相关的部分。如下图所示:
注意,在安装(Install)一部分,操作非常简单,只需要一条 pip 命令就好。
pip install pdftotext
跟你刚刚的操作,一模一样,对吧?
那怎么会出错呢?
请你往上看。
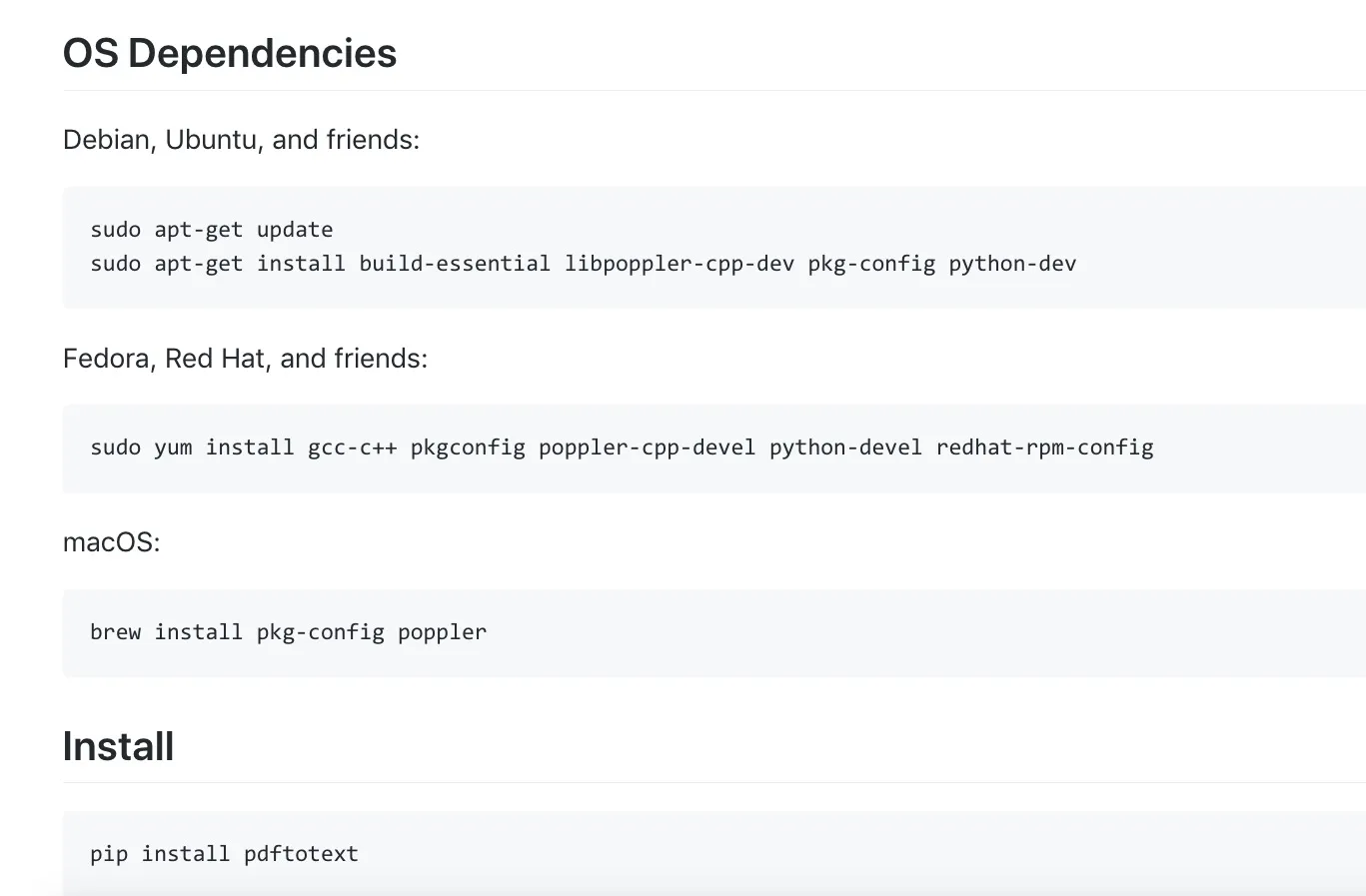
这里有个“系统依赖”(OS Dependencies)部分。它用了比安装命令多出数倍的篇幅,告诉你在不同的操作系统上,需要安装的依赖包。
如果你之前尝试过我的那篇《贷还是不贷:如何用Python和机器学习帮你决策?》教程,应该记得,你遇到过类似问题。
[图片上传失败...(image-902468-1539052087951)]
对,就是最后步骤,尝试绘制这幅决策树可视化图的时候,也遭遇到报错。
错误出现的原因,我已经在《Python编程遇问题,文科生怎么办?》一文中为你详细解释过了。就是因为不少 Python 包,实际上是包裹了其他软件、甚至是系统级别的功能,方便你使用。要正常安装使用这种 Python 包,你首先需要确保系统拥有这些功能,或者已经安装了相应的软件。这就叫做依赖(Dependencies)。
好了,问题找到了。因为这位读者,没有安装对应的依赖。
所以,他虽然下了很大功夫,搜索问题病症和解决方案,但是都是从具体的报错信息出发的。因此一直跟 gcc 、头文件这些编译相关的内容较劲儿。找到的解决方案,其实跟遇到的问题,并不匹配。他其实本不需要见识各种各样的报错信息,而只需要把相应的依赖软件安装就好了。
这位读者,用的是 macOS 。
回顾一下官网给出的依赖要求:
那么,他需要执行:
brew install pkg-config poppler
写到这里,似乎应该是个大团圆的结局了。对吧?
未必。
因为他非常可能,立即会遇到新的报错。
新问题
怎么又报错了?!
因为 brew 命令,属于 Homebrew 套件,它不是 macOS 系统里自带的工具。
好吧,他可以去搜索引擎查找 brew 是怎么回事儿,继而到 Homebrew 的官网成功下载,然后学习如何安装……
最终,估计他可以走到正确的路径上来了。
你可以替他高兴,但是我们不要过早欢呼。
因为这种解决方案,其实只是个例,不具备可推广性。
更多人用的操作系统,是 Windows 对不对?
回过头来看看,刚才的系统依赖清单里面,有 Windows 吗?
没有。
是不是因为作者忘了写?
又或者,是不是因为 Windows 本身已经有了相关软件集成,无须安装?
都不是。
现实是残酷的。
打开 pdftotext 官方 github 页面的答疑记录来看, Windows 干脆就无法像 Linux 或者 macOS 一样,一行命令安装好依赖。
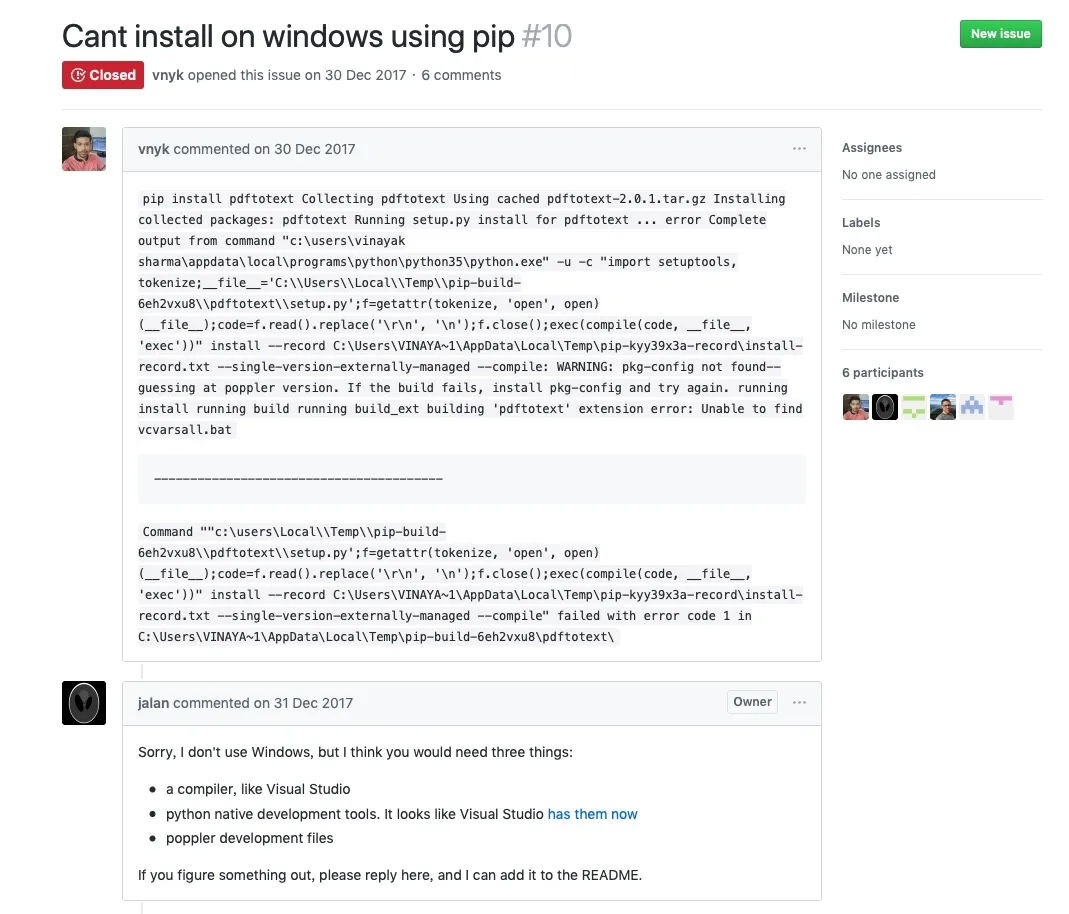
软件作者给你指出的方向,居然是安装 Visual Studio 这样的编译器,然后自己编译出来。
对于文科生来说,这不厚道啊!
……
你别急着放弃啊!我还没说完呢。
曲径
遇到问题,不要第一时间只想到“放弃”这种方法。
虽然学会止损很重要。但是如果因为有困难,就放弃解决问题,那就背离初衷了。
倘若人类的祖先都这样处理问题,今天我们或许都在树上呆着,跟大自然“和谐相处”呢。
但那恐怕只是我们的美好幻想——更大的可能性,是我们这个物种早就灭绝了。
面对新的问题,请你再度拿出“第一性原理”的思考方式。
注意我们的问题已经从“如何应对报错信息”,转换到了“如何正确安装 pdftotext ”软件包。
但是如果你在 Windows 平台,似乎这个软件包跟你缘分不是很密切。
怎么办?
我们再思考一步,真的必须要安装 pdftotext 这款软件包吗?
这样一问,答案呼之欲出:不一定啊!
许多功能,都有不同的软件包可以做到。
之前的教程里,你已经看到了许多的例子。
例如绘图,你既可以用 matplotlib ,也可以用 plotnine ;
中文分词,你既可以用 boson NLP,也可以用结巴分词;
深度学习,你既可以用 tflearn ,也可以用 Keras,还可以用 TuriCreate。
这里,重新给你回放一下 wordcloud 官方 github repo 上面的那行示例语句:
pdftotext mydocument.pdf - | wordcloud_cli --imagefile wordcloud.png
思考一下,使用 pdftotext 这个软件包,用来做什么?
对,是用来把 pdf 文件,变成文本。
有了文本,喂给 wordcloud 工具,它就能做成词云。
我们需要的,根本就不是正确安装 pdftotext ,而是找到一个工具,把 pdf 给我们转换成为文本。
好了,“把 pdf 转换成为文本”让你想到了什么?
如果你没有想到我给你写过的《如何用Python批量提取PDF文本内容?》,那就需要“学而时习之”了。
文中,我给你介绍过一款可以完成上述功能的 Python 软件包,叫做 pdfminer.six 。
当时,我们采用的方法,是 Python 编程,调用 pdfminer.six 软件包作为模块载入。
现在我们需要看看,它是否也支持命令行直接操作。
这里是它的 github 页面。
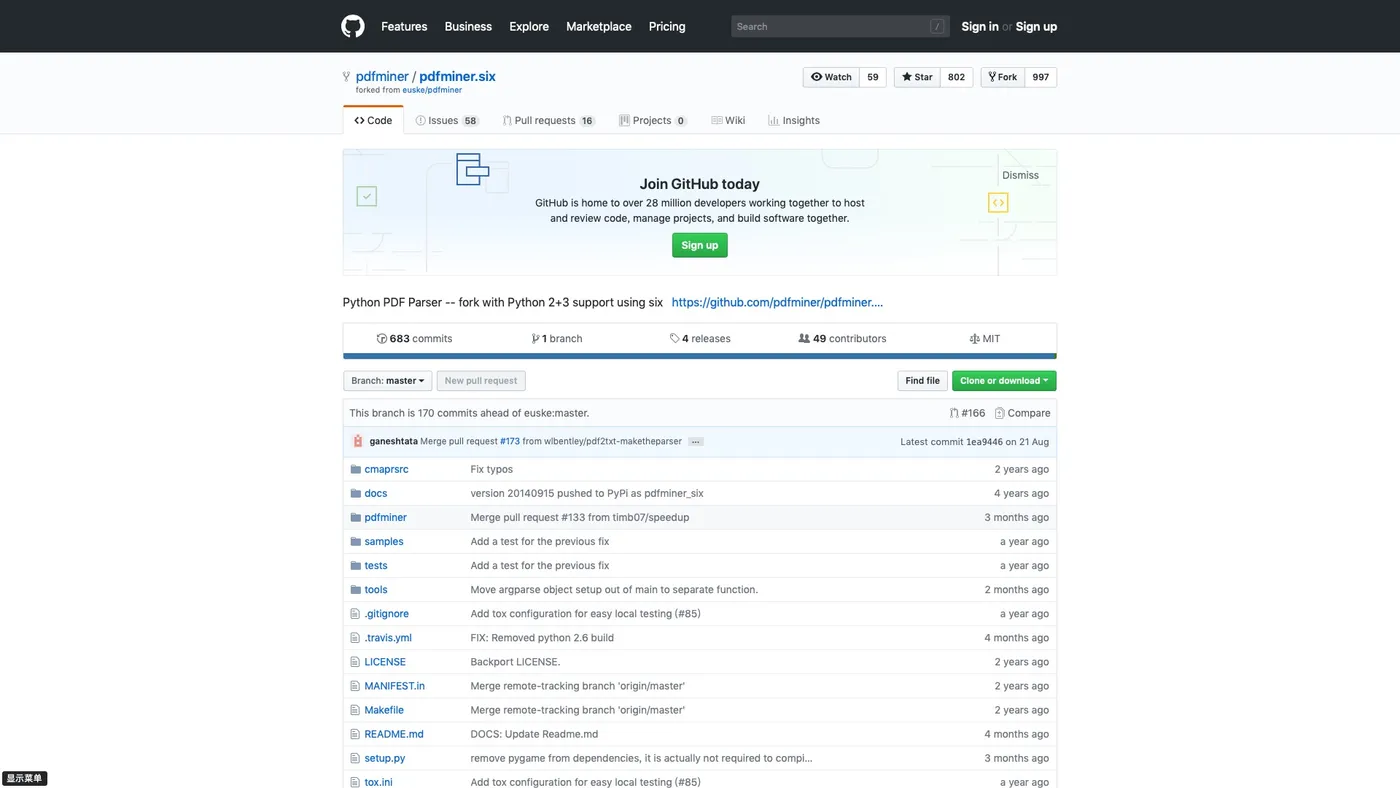
下拉页面,可以看到专门有一个部分,给你介绍如何使用 pdfminer.six 命令行完成文本提取功能。

好了,我们的猜想被证实了。它完全可用。
另外请注意, pdfminer.six 的安装说明里,根本就没有提到操作系统依赖。
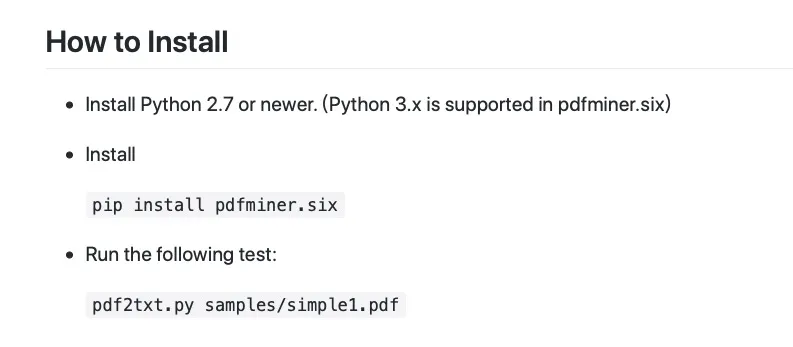
这就意味着,不管你用的是 Windows、Linux,还是 macOS ,都可以在不必安装依赖软件的情况下,直接用 pip 工具安装 pdfminer.six 。
步骤
下面我们来看看,如何用下面的简单步骤,实现我们的目的——直接用命令行而非编程方式,从 pdf 文件,分析并绘制词云。
先确保你的系统里面 python 3 已经安装。如需全新安装,请参考这个视频教程。
然后,用 pip 命令安装 wordcloud 软件包:
pip install wordcloud
注意如果你在安装过程中遇到问题,请参考我的另一份视频教程。
之后,执行下述语句,安装 pdfminer.six 。
pip install pdfminer.six
你可以自己新建一个测试目录,拷贝进入一个 pdf 文件。
或者,你也可以直接下载这个压缩文件,解压后有一个现成的 pdf 文件。后文还有对应生成词云结果,供你测试和对比。
我们打开这个样例 pdf 文件(名称为 test.pdf ),看看内容:

之后在终端下进入该测试目录(方法依然参考这个视频教程),执行:
pdf2txt.py test.pdf | wordcloud_cli --imagefile wordcloud.png
对比一下,我们只是把原先 wordcloud 官方页面上的命令:
pdftotext mydocument.pdf - | wordcloud_cli --imagefile wordcloud.png
前半部分进行了替换,使用了 pdfminer.six 软件包。
转瞬间,wordcloud.png 这个图像文件就在当前目录下生成了。打开看看:

没毛病,对吧?
小结
如你所见,完成从 pdf 提取词云这个功能,原本只需要上面一个小节里,几行命令而已。即便你从 Anaconda 开始全新安装,所需的时间也远远不到一个小时。
但是,就像这位提问的读者一样,如果你遭遇到了安装中的错误提示,然后跟错误提示展开各种斗争,并且最终无功而返。那耽误的时间,可能远远不止一个小时。
你可能会辩驳,说自己从这个折腾的过程中,也学到了东西。没错,你会学到如何采用 Homebrew 来安装 macOS 上的软件,了解 gcc 这款开源编译工具的使用方法,甚至是如何在 Windows 上面编译源代码……但是获得这些经验,你付出了过高的代价。你的机会成本,是原本可以用这几个小时好好读一两篇高水平论文,甚至是写作自己的工作报告或者论文初稿。
用这时间,通过不断折腾来尝试解决问题,还远不是最糟糕的结果。对很多初学者来说,这种长时间反复的挫折,会严重打击你尝试新软件、新功能的信心和兴趣,甚至干脆放弃了探索的欲望。这对你的损害就太大了。
希望读过本文,你收获的远不仅仅是“如何从 pdf 提取词云”这种简单的技巧,而是在生活、学习和工作中,充分运用第一性原理思维工具,把自己从纷繁复杂的表象里面抽身出来,扩大格局和视野,关注更本质的需求,做出明智而高效的选择。
最后给你留一道思考题:
本文给你展示的,是从 pdf 提取词云的最好方法吗?
欢迎你把自己的思考结果,留言告诉我,也分享给其他人。
如果你对 Python 与数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。




