
标题中的英文首字母大写比较规范,但在python实际使用中均为小写。
2018年9月6日笔记
IDE(Intergrated development Environment),集成开发环境为jupyter notebook和Pycharm
操作系统:Win10
语言及其版本:python3.6
0.观察网页
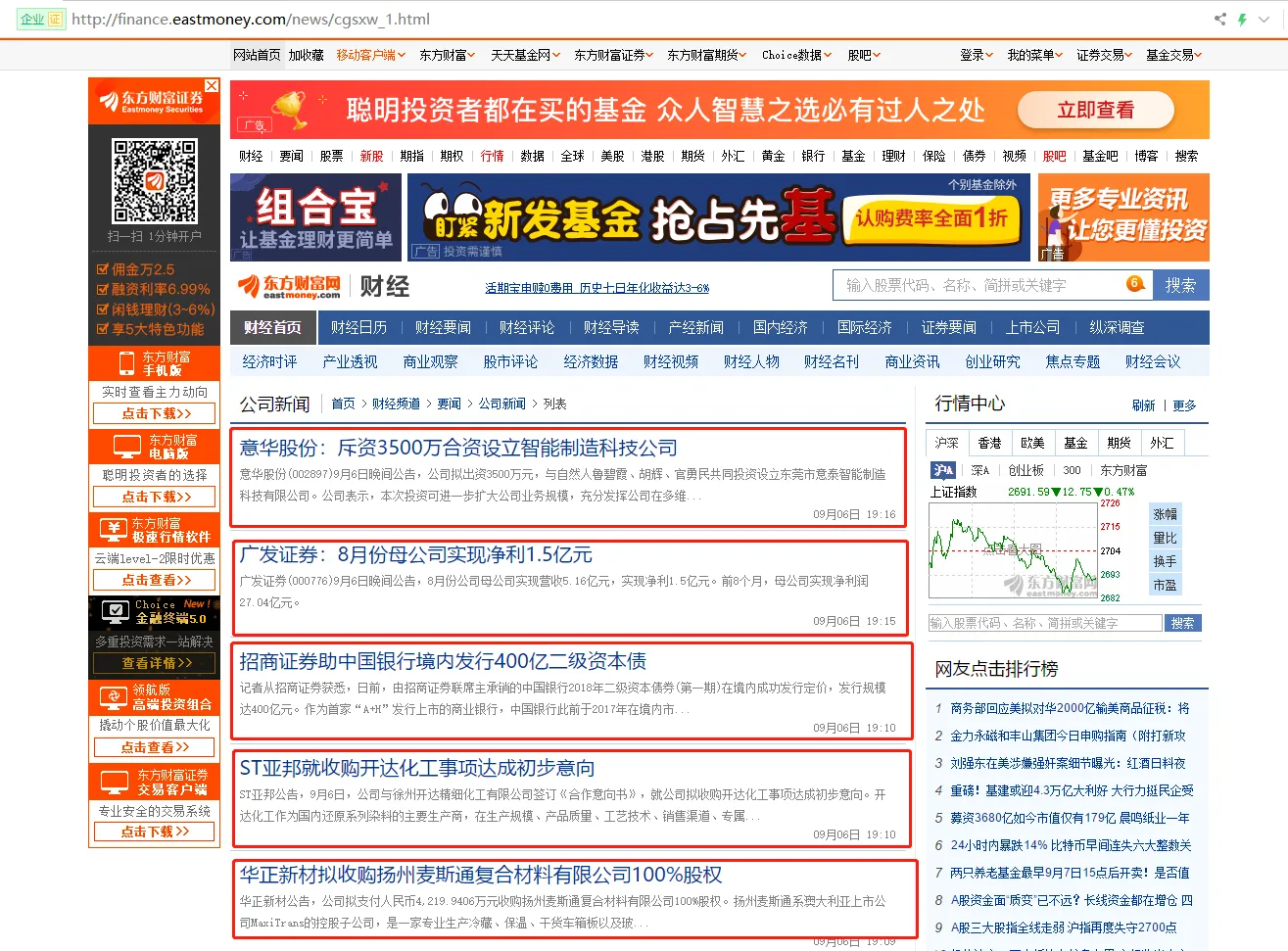
网页链接:http://finance.eastmoney.com/news/cgsxw_1.html
打开网页,红色方框标注出爬取的文章,效果如下图所示。
1 新建爬虫工程
新建爬虫工程命令:scrapy startproject EastMoney
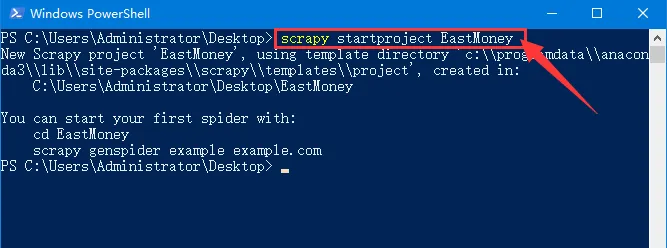
进入爬虫工程目录命令: cd EastMoney
新建爬虫文件命令: scrapy genspider money finance.eastmoney.com
2.编辑items.py文件
共需要收集8个字段信息:网站website、页面链接url、标题title、摘要abstract、内容content、日期datetime、来源original、作者author
import scrapy
from scrapy import Field
class EastmoneyItem(scrapy.Item):
website= Field()
url= Field()
title= Field()
abstract = Field()
content= Field()
datetime= Field()
original= Field()
author= Field()
3.编辑money.py文件
定义parse函数解析目录页面,获取目录页面中的每篇文章的详情页链接。
第16、17、18行代码是获取文章的摘要,即字段abstract。
此字段信息有时在p标签的title属性中,有时在p标签的文本内容中,所以要判断然后再赋值。
第19行代码scrapy.Request方法需要3个参数。
第1个参数是详情页面链接url,数据类型为字符串;
第2个参数是解析函数,数据类型为函数对象;
第3个关键字参数meta可以为任意对象,作用是传递上一级解析函数获取的一部分字段内容。
定义parse1函数解析详情页,获取website、url、title、content、datetime、original、author这7个字段内容,然后返回EastmoneyItem对象,交给管道处理。
import scrapy
from ..items import EastmoneyItem
class MoneySpider(scrapy.Spider):
name = 'money'
allowed_domains = ['finance.eastmoney.com']
start_urls = []
base_url = 'http://finance.eastmoney.com/news/cgsxw_{}.html'
for i in range(1, 26):
start_urls.append(base_url.format(i))
def parse(self, response):
article_list = response.xpath('//ul[@id="newsListContent"]/li')
for article in article_list:
detail_url = article.xpath('.//a/@href').extract_first()
item = EastmoneyItem()
abstract1 = article.xpath('.//p[@class="info"]/@title')
abstract2 = article.xpath('.//p[@class="info"]/text()')
item['abstract'] = abstract1.extract_first().strip() if len(abstract1) else abstract2.extract_first().strip()
yield scrapy.Request(detail_url, callback=self.parse1, meta={'item':item})
def parse1(self, response):
item = response.meta['item']
item['website'] = '东方财富网'
item['url'] = response.url
item['title'] = response.xpath('//div[@class="newsContent"]/h1/text()').extract_first()
p_list = response.xpath('//div[@id="ContentBody"]/p')
item['content'] = '\n'.join([p.xpath('.//text()').extract_first().strip() for p in p_list if len(p.xpath('.//text()'))]).strip()
item['datetime'] = response.xpath('//div[@class="time-source"]/div[@class="time"]/text()').extract_first()
item['original'] = response.xpath('//div[@class="source data-source"]/@data-source').extract_first()
item['author'] = response.xpath('//p[@class="res-edit"]/text()').extract_first().strip()
yield item
4.运行爬虫工程
在爬虫工程中打开cmd或者PowerShell,在其中输入命令并运行:scrapy crawl money -o eastMoney.csv -t csv
5.查看数据持久化结果
在数据持久化文件eastMoney.csv的同级目录下打开jupyter notebook
查看数据持久化结果代码如下:
import pandas as pd
eastMoney_df = pd.read_csv('eastMoney.csv')
eastMoney_df.head()

从上图可以看出我们较好的完成了数据收集工作,但是字段content仍有不完善的地方。
迭代开发,在第6章中找出方法解决此问题。
6.重新编辑money.py文件
使用BeautifulSoup库,能够较好获取文章中的内容。
BeautifulSoup库中的bs4.element.Tag对象的text属性容易获取到节点的文本内容。
import scrapy
from ..items import EastmoneyItem
from bs4 import BeautifulSoup as bs
class MoneySpider(scrapy.Spider):
name = 'money'
allowed_domains = ['finance.eastmoney.com']
start_urls = []
base_url = 'http://finance.eastmoney.com/news/cgsxw_{}.html'
for i in range(1, 26):
start_urls.append(base_url.format(i))
def parse(self, response):
article_list = response.xpath('//ul[@id="newsListContent"]/li')
for article in article_list:
detail_url = article.xpath('.//a/@href').extract_first()
item = EastmoneyItem()
abstract1 = article.xpath('.//p[@class="info"]/@title')
abstract2 = article.xpath('.//p[@class="info"]/text()')
item['abstract'] = abstract1.extract_first().strip() if len(abstract1) else abstract2.extract_first().strip()
yield scrapy.Request(detail_url, callback=self.parse1, meta={'item':item})
def parse1(self, response):
item = response.meta['item']
item['website'] = '东方财富网'
item['url'] = response.url
item['title'] = response.xpath('//div[@class="newsContent"]/h1/text()').extract_first()
soup = bs(response.text, 'lxml')
p_list = soup.select('div#ContentBody p')
item['content'] = '\n'.join([p.text.strip() for p in p_list]).strip()
item['datetime'] = response.xpath('//div[@class="time-source"]/div[@class="time"]/text()').extract_first()
item['original'] = response.xpath('//div[@class="source data-source"]/@data-source').extract_first()
item['author'] = response.xpath('//p[@class="res-edit"]/text()').extract_first().strip()
yield item
7.重新查看数据持久化结果
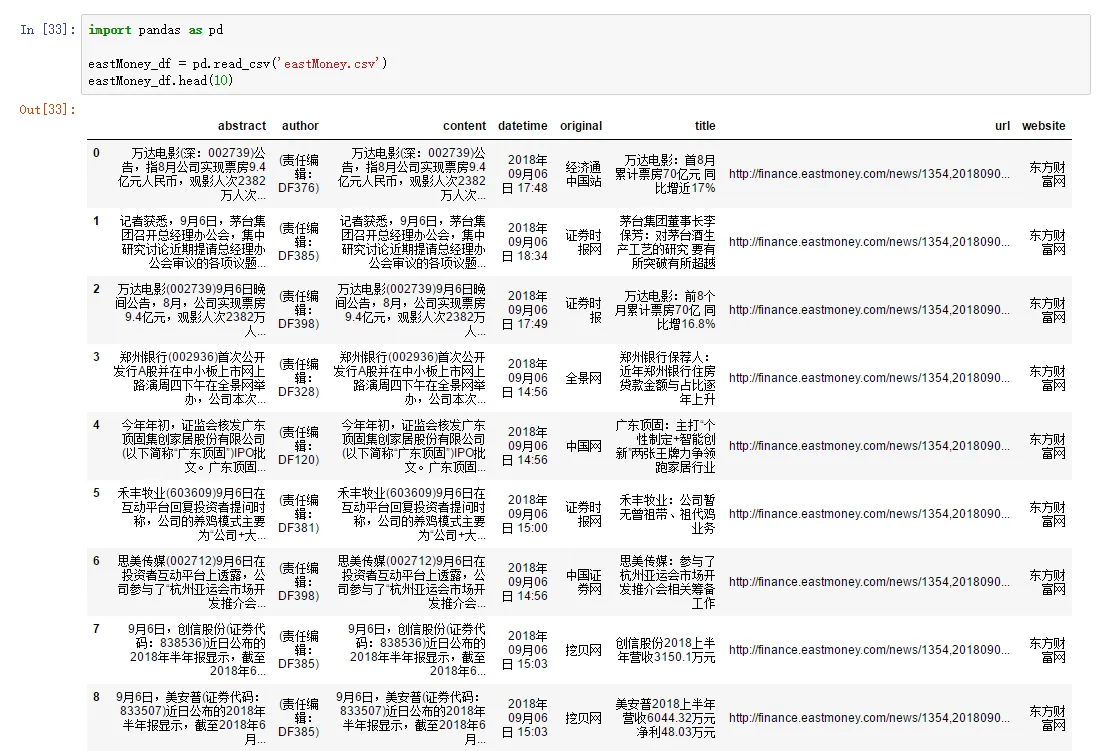
从上面的运行结果可以看出,优化之后能够正确爬取文章内容。
8.总结
两个知识点大家可以学习:
1.scrapy.Request方法的meta参数可以传递上一级解析函数的解析结果
2.文章内容用xpath很难获取,在第2轮迭代开发中,使用BeautifulSoup库可以解决此问题。

