下一篇地址 https://yq.aliyun.com/articles/64423
word2vec 是现在在自然语言处理中非常非常实用的技术,word2vec一般的用途通常有两种,第一种是其他复杂的神经网络模型的初始化,还有一种是把词与词之间的相似度来作为某个模型的特征。
word2vec的最大优势不但是因为它效果比较好,最大的原因是因为它非常的快,几亿的文本都能很快训练完成,因此深受研究者的喜爱。
word2vec 是现在在自然语言处理中非常非常实用的技术,word2vec一般的用途通常有两种,第一种是其他复杂的神经网络模型的初始化,还有一种是把词与词之间的相似度来作为某个模型的特征。
word2vec的最大优势不但是因为它效果比较好,最大的原因是因为它非常的快,几亿的文本都能很快训练完成,因此深受研究者的喜爱。
word2vec目前主流有两种实现的方式,一个是Mikolov13年的skip-gram实现,另一个是stanford大学的golve实现,两者现在都被广泛使用。
对应的论文分别为
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
和
http://nlp.stanford.edu/projects/glove/
本文首先介绍Mikolov13年的skip-gram实现。之后代码的解读会使用google2013的开源代码。
0.说在前头
在介绍原理之前,说一件非常重要的事情,词的vec到底是在哪里表示的?
答:是skip-gram的输入层到第一个hidden层(一共就一个hidden层)的weight,weight的每一行(或者每一列)代表一个词向量
1.word2vec的背景
过去自然语言处理的时候是怎么表示一个词的?
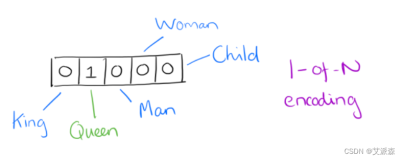
答:one-hot表示。In vector space terms, this is a vector with one 1 and a lot of zeroes [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
比如
motel [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0] AND hotel [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0] = 0
可是motel和hotel其实是有很大相关性的,但他们and一下竟然是0真的太糟糕了!
因此,很多学者就想到了用前后文来表示一个词,先不管神经网络怎么定义,比如有这个两句话
Hotel lives people. Motel lives people.
那么我们想得到的效果是, 输入是 Hotel, 答案是 lives, 输入是Hotel 答案是 people.
输入是 Motel 答案是lives, 输入是Motel 答案是people.
从直觉上来说,由于Hotel和Motel作为输入的时候,答案非常类似,因此这两个词也非常相似。
2.word2vec skip-gram实现的神经网络结构
先上图
明确每个部分的含义
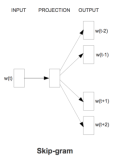
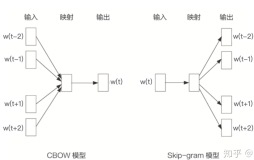
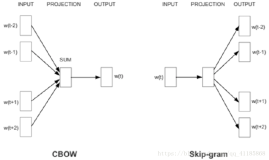
input的w(t) 是一个one-hot表示 如 [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0...]这个向量的长度其实就是词汇量 V,也就是这个语言的所有的单词的数量。
input->projection的箭头是一个weight取名w1, 为V*H维,H是hidden层的维度。意识到每一个单词的输入其实就一个维上是1,因此w(t)*w1其实就是取了w1中的一列。 取的这一列就是单词的词向量。
projection层就是hidden层,为一个H维向量,取名为h。
projection->output的箭头是一个weight取名w2,为H*V维,projection->output的所有箭头都是使用同一个weight,即w2
output层为 hidden层到output层乘积 h*w2的值取softmax。 output层是一个V维向量,取名叫o
output层上还有标有w(t-2) w(t-1)这个是目标值(正解)。也就第t个单词的前后几个单词,前面在input中有提到,w(t-2)w(t-1)都是一个V维向量的one-hot表示。也就是说把计算得到的o和w(t-2),w(t-1)比较,然后类似于logestic regrestion来向这些目标值(正解)靠拢。
明确了每个部分含义以后,再阐述下具体的计算过程
比如有如下文本: 我 去 吃 饭 了
w(t-2)=我 w(t-1)=去 w(t)=吃 w(t+1)=饭 w(t+2)=了 的one-hot
forward 的时候是 o=softmax(w(t)*w1*w2)
backward时候output层loss 是 (o-w(t-2))+(o-w(t-1))+(o-w(t+1))+(o-w(t+2))
要更新的是w1,w2,具体更新方法是backpropagation。
3.word2vec 为什么hotel和motel相似
从上述神经网络结构可以看出,hotel,motel周围的单词比较类似,那在上图中的体现就是output层的答案(hotel和motel周围的词)类似。由于output层的计算值o是由h*w2得到的,w2是共享的weight不会改变,所以在hotel,motel的one-hot作为输入时,h也是很类似的。 而h值其实就是w1中取一列。因此hotel和motel在w1中的取的那一列就很类似。 重要的事情说三遍 取的这一列就是单词的词向量,
因此,hotel和motel的词向量就很相似。
下一期会进行google code的review,刚刚介绍的方法在模型更新时非常缓慢,在实践中有两种更新方法,一种比较高大上,一种听上去傻点,但是效果是一致的。尽请期待。
对应的论文分别为
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
和
http://nlp.stanford.edu/projects/glove/
本文首先介绍Mikolov13年的skip-gram实现。之后代码的解读会使用google2013的开源代码。
0.说在前头
在介绍原理之前,说一件非常重要的事情,词的vec到底是在哪里表示的?
答:是skip-gram的输入层到第一个hidden层(一共就一个hidden层)的weight,weight的每一行(或者每一列)代表一个词向量
1.word2vec的背景
过去自然语言处理的时候是怎么表示一个词的?
答:one-hot表示。In vector space terms, this is a vector with one 1 and a lot of zeroes [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
比如
motel [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0] AND hotel [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0] = 0
可是motel和hotel其实是有很大相关性的,但他们and一下竟然是0真的太糟糕了!
因此,很多学者就想到了用前后文来表示一个词,先不管神经网络怎么定义,比如有这个两句话
Hotel lives people. Motel lives people.
那么我们想得到的效果是, 输入是 Hotel, 答案是 lives, 输入是Hotel 答案是 people.
输入是 Motel 答案是lives, 输入是Motel 答案是people.
从直觉上来说,由于Hotel和Motel作为输入的时候,答案非常类似,因此这两个词也非常相似。
2.word2vec skip-gram实现的神经网络结构
先上图
明确每个部分的含义
input的w(t) 是一个one-hot表示 如 [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0...]这个向量的长度其实就是词汇量 V,也就是这个语言的所有的单词的数量。
input->projection的箭头是一个weight取名w1, 为V*H维,H是hidden层的维度。意识到每一个单词的输入其实就一个维上是1,因此w(t)*w1其实就是取了w1中的一列。 取的这一列就是单词的词向量。
projection层就是hidden层,为一个H维向量,取名为h。
projection->output的箭头是一个weight取名w2,为H*V维,projection->output的所有箭头都是使用同一个weight,即w2
output层为 hidden层到output层乘积 h*w2的值取softmax。 output层是一个V维向量,取名叫o
output层上还有标有w(t-2) w(t-1)这个是目标值(正解)。也就第t个单词的前后几个单词,前面在input中有提到,w(t-2)w(t-1)都是一个V维向量的one-hot表示。也就是说把计算得到的o和w(t-2),w(t-1)比较,然后类似于logestic regrestion来向这些目标值(正解)靠拢。
明确了每个部分含义以后,再阐述下具体的计算过程
比如有如下文本: 我 去 吃 饭 了
w(t-2)=我 w(t-1)=去 w(t)=吃 w(t+1)=饭 w(t+2)=了 的one-hot
forward 的时候是 o=softmax(w(t)*w1*w2)
backward时候output层loss 是 (o-w(t-2))+(o-w(t-1))+(o-w(t+1))+(o-w(t+2))
要更新的是w1,w2,具体更新方法是backpropagation。
3.word2vec 为什么hotel和motel相似
从上述神经网络结构可以看出,hotel,motel周围的单词比较类似,那在上图中的体现就是output层的答案(hotel和motel周围的词)类似。由于output层的计算值o是由h*w2得到的,w2是共享的weight不会改变,所以在hotel,motel的one-hot作为输入时,h也是很类似的。 而h值其实就是w1中取一列。因此hotel和motel在w1中的取的那一列就很类似。 重要的事情说三遍 取的这一列就是单词的词向量,
因此,hotel和motel的词向量就很相似。
下一期会进行google code的review,刚刚介绍的方法在模型更新时非常缓慢,在实践中有两种更新方法,一种比较高大上,一种听上去傻点,但是效果是一致的。尽请期待。