早些日子有人问我我的微信里面有一共多少朋友,我就随后拉倒了通讯录最下面就找到了微信一共有多少位好友。然后他又问我,这里面你认识多少人?
这一句话问的我很无语。一千多个好友我真的不知道认识的人有多少。他还紧追着不放了,你知道你微信朋友的男女比例嘛?你知道你微信朋友大部分来自什么地方吗?
以下的代码内容只涉及一些简单的Python知识,稍微有一点Python知识的朋友都可以读下去。 如果你没有Python的知识你可能需要去学习一下Python,当然你也可以不用学,搭建好Python的环境就好,期间可能需要用到一些库需要自己去解决一下,在下文中也会详细诉述。

第一步:首先抓取微信朋友的资料
既然是要做统计和分析,第一步就是微信朋友的所有可以抓取的资料抓取出来。所谓有用的资料大致来说有以下几个内容:
昵称、微信号、城市、性别、星标好友、头像、个性签名、备注
每一项或者联合项可以做的统计
性别:好友性别统计
城市:好友地区分布
备注+昵称:大致统计认识的好友比例
头像:人脸识别
那么如何抓取呢?这里使用了之前有一位大神写的如何找出被删的好友的代码,修改部分为从提取json数据截断,对返回的json数据进行提取分别找到了以下的所需要的信息:

小编给大家推荐一个学习氛围超好的地方,python交流企鹅裙:【611+530+101】适合在校大学生,小白,想转行,想通过这个找工作的加入。裙里有大量学习资料,有大神解答交流问题,每晚都有免费的直播课程
代码修改为:
#!/usr/bin/env python
# encoding=utf-8
from __future__ import print_function
import os
import requests
import re
import time
import xml.dom.minidom
import json
import sys
import math
import subprocess
import ssl
import threading
import urllib,urllib2
DEBUG = False
MAX_GROUP_NUM = 2 # 每组人数
INTERFACE_CALLING_INTERVAL = 5 # 接口调用时间间隔, 间隔太短容易出现"操作太频繁", 会被限制操作半小时左右
MAX_PROGRESS_LEN = 50
QRImagePath = os.path.join(os.getcwd(), 'qrcode.jpg')
tip = 0
uuid = ''
base_uri = ''
redirect_uri = ''
push_uri = ''
skey = ''
wxsid = ''
wxuin = ''
pass_ticket = ''
deviceId = 'e000000000000000'
BaseRequest = {}
ContactList = []
My = []
SyncKey = []
try:
xrange
range = xrange
except:
# python 3
pass
def responseState(func, BaseResponse):
ErrMsg = BaseResponse['ErrMsg']
Ret = BaseResponse['Ret']
if DEBUG or Ret != 0:
print('func: %s, Ret: %d, ErrMsg: %s' % (func, Ret, ErrMsg))
if Ret != 0:
return False
return True
def getUUID():
global uuid
url = 'https://login.weixin.qq.com/jslogin'
params = {
'appid': 'wx782c26e4c19acffb',
'fun': 'new',
'lang': 'zh_CN',
'_': int(time.time()),
}
r= myRequests.get(url=url, params=params)
r.encoding = 'utf-8'
data = r.text
# print(data)
# window.QRLogin.code = 200; window.QRLogin.uuid = "oZwt_bFfRg==";
regx = r'window.QRLogin.code = (d+); window.QRLogin.uuid = "(S+?)"'
pm = re.search(regx, data)
code = pm.group(1)
uuid = pm.group(2)
if code == '200':
return True
return False
def showQRImage():
global tip
url = 'https://login.weixin.qq.com/qrcode/' + uuid
params = {
't': 'webwx',
'_': int(time.time()),
}
r = myRequests.get(url=url, params=params)
tip = 1
f = open(QRImagePath, 'wb')
f.write(r.content)
f.close()
time.sleep(1)
if sys.platform.find('darwin') >= 0:
subprocess.call(['open', QRImagePath])
else:
subprocess.call(['xdg-open', QRImagePath])
print('请使用微信扫描二维码以登录')
def waitForLogin():
global tip, base_uri, redirect_uri, push_uri
url = 'https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login?tip=%s&uuid=%s&_=%s' % (
tip, uuid, int(time.time()))
r = myRequests.get(url=url)
r.encoding = 'utf-8'
data = r.text
# print(data)
# window.code=500;
regx = r'window.code=(d+);'
pm = re.search(regx, data)
code = pm.group(1)
if code == '201': # 已扫描
print('成功扫描,请在手机上点击确认以登录')
tip = 0
elif code == '200': # 已登录
print('正在登录...')
regx = r'window.redirect_uri="(S+?)";'
pm = re.search(regx, data)
redirect_uri = pm.group(1) + '&fun=new'
base_uri = redirect_uri[:redirect_uri.rfind('/')]
# push_uri与base_uri对应关系(排名分先后)(就是这么奇葩..)
services = [
('wx2.qq.com', 'webpush2.weixin.qq.com'),
('qq.com', 'webpush.weixin.qq.com'),
('web1.wechat.com', 'webpush1.wechat.com'),
('web2.wechat.com', 'webpush2.wechat.com'),
('wechat.com', 'webpush.wechat.com'),
('web1.wechatapp.com', 'webpush1.wechatapp.com'),
]
push_uri = base_uri
for (searchUrl, pushUrl) in services:
if base_uri.find(searchUrl) >= 0:
push_uri = 'https://%s/cgi-bin/mmwebwx-bin' % pushUrl
break
# closeQRImage
if sys.platform.find('darwin') >= 0: # for OSX with Preview
os.system("osascript -e 'quit app "Preview"'")
elif code == '408': # 超时
pass
# elif code == '400' or code == '500':
return code
def login():
global skey, wxsid, wxuin, pass_ticket, BaseRequest
r = myRequests.get(url=redirect_uri)
r.encoding = 'utf-8'
data = r.text
# print(data)
doc = xml.dom.minidom.parseString(data)
root = doc.documentElement
for node in root.childNodes:
if node.nodeName == 'skey':
skey = node.childNodes[0].data
elif node.nodeName == 'wxsid':
wxsid = node.childNodes[0].data
elif node.nodeName == 'wxuin':
wxuin = node.childNodes[0].data
elif node.nodeName == 'pass_ticket':
pass_ticket = node.childNodes[0].data
# print('skey: %s, wxsid: %s, wxuin: %s, pass_ticket: %s' % (skey, wxsid,
# wxuin, pass_ticket))
if not all((skey, wxsid, wxuin, pass_ticket)):
return False
BaseRequest = {
'Uin': int(wxuin),
'Sid': wxsid,
'Skey': skey,
'DeviceID': deviceId,
}
return True
def webwxinit():
url = (base_uri +
'/webwxinit?pass_ticket=%s&skey=%s&r=%s' % (
pass_ticket, skey, int(time.time())) )
params = {'BaseRequest': BaseRequest }
headers = {'content-type': 'application/json; charset=UTF-8'}
r = myRequests.post(url=url, data=json.dumps(params),headers=headers)
r.encoding = 'utf-8'
data = r.json()
if DEBUG:
f = open(os.path.join(os.getcwd(), 'webwxinit.json'), 'wb')
f.write(r.content)
f.close()
# print(data)
global ContactList, My, SyncKey
dic = data
ContactList = dic['ContactList']
My = dic['User']
SyncKey = dic['SyncKey']
state = responseState('webwxinit', dic['BaseResponse'])
return state
def webwxgetcontact():
url = (base_uri +
'/webwxgetcontact?pass_ticket=%s&skey=%s&r=%s' % (
pass_ticket, skey, int(time.time())) )
headers = {'content-type': 'application/json; charset=UTF-8'}
r = myRequests.post(url=url,headers=headers)
r.encoding = 'utf-8'
data = r.json()
if DEBUG:
f = open(os.path.join(os.getcwd(), 'webwxgetcontact.json'), 'wb')
f.write(r.content)
f.close()
dic = data
MemberList = dic['MemberList']
# 倒序遍历,不然删除的时候出问题..
SpecialUsers = ["newsapp", "fmessage", "filehelper", "weibo", "qqmail", "tmessage", "qmessage", "qqsync", "floatbottle", "lbsapp", "shakeapp", "medianote", "qqfriend", "readerapp", "blogapp", "facebookapp", "masssendapp",
"meishiapp", "feedsapp", "voip", "blogappweixin", "weixin", "brandsessionholder", "weixinreminder", "wxid_novlwrv3lqwv11", "gh_22b87fa7cb3c", "officialaccounts", "notification_messages", "wxitil", "userexperience_alarm"]
for i in range(len(MemberList) - 1, -1, -1):
Member = MemberList[i]
if Member['VerifyFlag'] & 8 != 0: # 公众号/服务号
MemberList.remove(Member)
elif Member['UserName'] in SpecialUsers: # 特殊账号
MemberList.remove(Member)
elif Member['UserName'].find('@@') != -1: # 群聊
MemberList.remove(Member)
elif Member['UserName'] == My['UserName']: # 自己
MemberList.remove(Member)
return MemberList
def syncKey():
SyncKeyItems = ['%s_%s' % (item['Key'], item['Val'])
for item in SyncKey['List']]
SyncKeyStr = '|'.join(SyncKeyItems)
return SyncKeyStr
def syncCheck():
url = push_uri + '/synccheck?'
params = {
'skey': BaseRequest['Skey'],
'sid': BaseRequest['Sid'],
'uin': BaseRequest['Uin'],
'deviceId': BaseRequest['DeviceID'],
'synckey': syncKey(),
'r': int(time.time()),
}
r = myRequests.get(url=url,params=params)
r.encoding = 'utf-8'
data = r.text
# print(data)
# window.synccheck={retcode:"0",selector:"2"}
regx = r'window.synccheck={retcode:"(d+)",selector:"(d+)"}'
pm = re.search(regx, data)
retcode = pm.group(1)
selector = pm.group(2)
return selector
def webwxsync():
global SyncKey
url = base_uri + '/webwxsync?lang=zh_CN&skey=%s&sid=%s&pass_ticket=%s' % (
BaseRequest['Skey'], BaseRequest['Sid'], urllib.quote_plus(pass_ticket))
params = {
'BaseRequest': BaseRequest,
'SyncKey': SyncKey,
'rr': ~int(time.time()),
}
headers = {'content-type': 'application/json; charset=UTF-8'}
r = myRequests.post(url=url, data=json.dumps(params))
r.encoding = 'utf-8'
data = r.json()
# print(data)
dic = data
SyncKey = dic['SyncKey']
state = responseState('webwxsync', dic['BaseResponse'])
return state
def heartBeatLoop():
while True:
selector = syncCheck()
if selector != '0':
webwxsync()
time.sleep(1)
def main():
global myRequests
if hasattr(ssl, '_create_unverified_context'):
ssl._create_default_https_context = ssl._create_unverified_context
headers = {'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.125 Safari/537.36'}
myRequests = requests.Session()
myRequests.headers.update(headers)
if not getUUID():
print('获取uuid失败')
return
print('正在获取二维码图片...')
showQRImage()
while waitForLogin() != '200':
pass
os.remove(QRImagePath)
if not login():
print('登录失败')
return
if not webwxinit():
print('初始化失败')
return
MemberList = webwxgetcontact()
threading.Thread(target=heartBeatLoop)
MemberCount = len(MemberList)
print('通讯录共%s位好友' % MemberCount)
d = {}
imageIndex = 0
for Member in MemberList:
imageIndex = imageIndex + 1
name = '/root/Desktop/friendImage/image'+str(imageIndex)+'.jpg'
imageUrl = 'https://wx.qq.com'+Member['HeadImgUrl']
r = myRequests.get(url=imageUrl,headers=headers)
imageContent = (r.content)
fileImage = open(name,'wb')
fileImage.write(imageContent)
fileImage.close()
print('正在下载第:'+str(imageIndex)+'位好友头像')
d[Member['UserName']] = (Member['NickName'], Member['RemarkName'])
city = Member['City']
city = 'nocity' if city == '' else city
name = Member['NickName']
name = 'noname' if name == '' else name
sign = Member['Signature']
sign = 'nosign' if sign == '' else sign
remark = Member['RemarkName']
remark = 'noremark' if remark == '' else remark
alias = Member['Alias']
alias = 'noalias' if alias == '' else alias
nick = Member['NickName']
nick = 'nonick' if nick == '' else nick
print(name,' ^+*+^ ',city,' ^+*+^ ',Member['Sex'],' ^+*+^ ',Member['StarFriend'],' ^+*+^ ',sign,' ^+*+^ ',remark,' ^+*+^ ',alias,' ^+*+^ ',nick )
if __name__ == '__main__':
main()
print('回车键退出...')
input()
所返回的json结果如下图所示
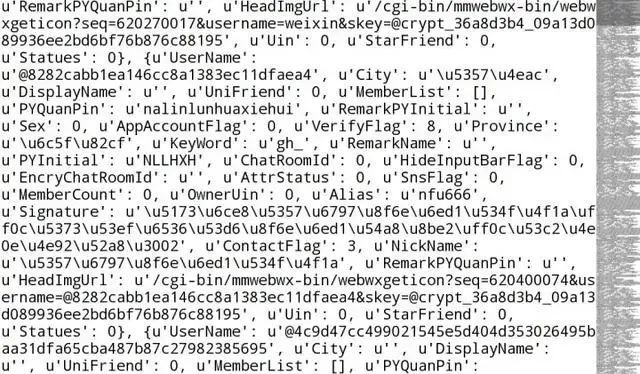
昵称、微信号、城市、性别、星标好友、头像、个性签名、备注。提取以上信息,对头像图片进行下载,并对数据进行简单的清洗等等,最后一列为微信号不方便显示。


第二步:性别统计和地区分布
使用python的pandas科学计算库进行简单的统计,如果你没有用过,可以转至如下链接进行安装学习:【原】十分钟搞定pandas
只要掌握了非常简单的pandas只是就可以继续往下看做以下统计
(1)、所有好友的男女比例
(2)、所有好友的城市分布
(3)、统计认识的朋友以及占所有朋友的百分比
统计方法:所有朋友 - 没有备注的朋友 - 备注与昵称相同的朋友
(4)、统计认识的朋友中的男女比例
统计方法:对三的结果再进行男女划分即可得到结果
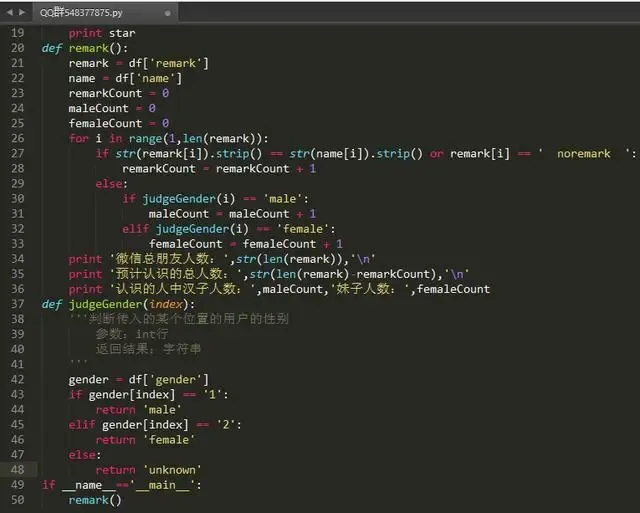
把结果做成简单的图表(主要使用了百度的 echarts 作图)
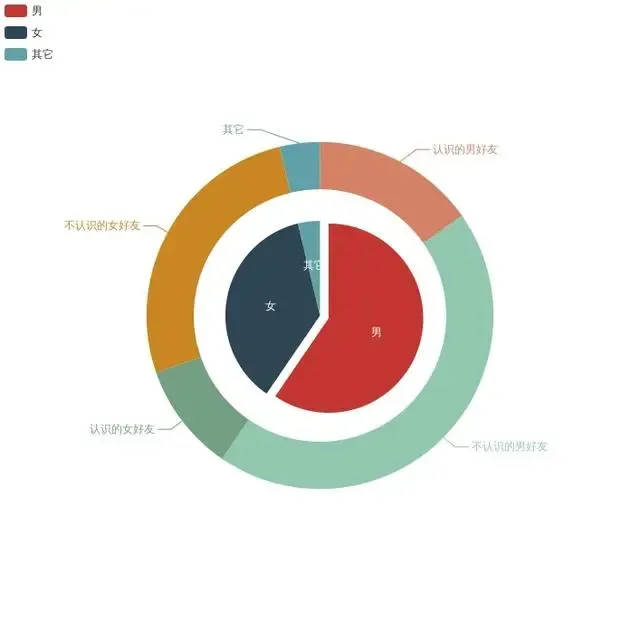
使用地图慧江苏省好友分布,这个编码我不知怎么回事,可能是浏览器问题,回头我用其它浏览器查看一下。
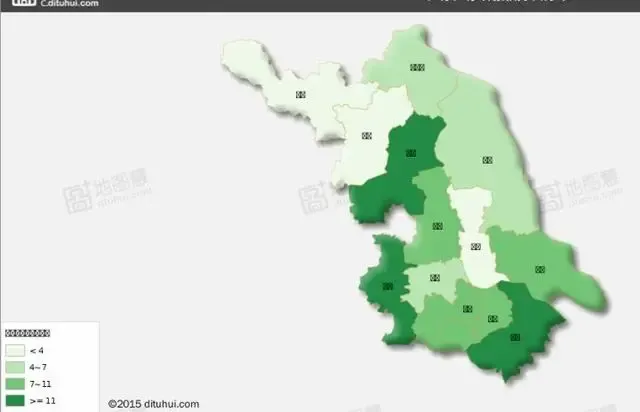
最后再生成省份好友分布地图
最后运用opencv的图像识别进行人像识别,统计微信好友中用人像作为头像的好友人数。OpenCV的全称是:Open Source Computer Vision Library。OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
如果你对opencv不是很了解,你可以按照以下的链接进行学习。
你可以去它的官网:http://opencv.org/ (需要有一定的英语知识)
国内也有一些比较好的博客资源,比如以下两个
如下开始是对抓取的朋友头像进行遍历识别是否含有人脸,代码如下。
#!/usr/bin/env python
'''
face detection using haar cascades
USAGE:
facedetect.py [--cascade
'''
# Python 2/3 compatibility
from __future__ import print_function
import numpy as np
import cv2
# local modules
from video import create_capture
from common import clock, draw_str
def detect(img, cascade):
rects = cascade.detectMultiScale(img, scaleFactor=1.3, minNeighbors=4, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
if len(rects) == 0:
return []
rects[:,2:] += rects[:,:2]
return rects
def draw_rects(img, rects, color):
for x1, y1, x2, y2 in rects:
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
if __name__ == '__main__':
import sys, getopt
print(__doc__)
count = 0
for i in range(1,1192):
print(str(i))
args, video_src = getopt.getopt(sys.argv[1:], '', ['cascade=', 'nested-cascade='])
try:
video_src = video_src[0]
except:
video_src = 0
args = dict(args)
cascade_fn = args.get('--cascade', "../../data/haarcascades/haarcascade_frontalface_alt.xml")
nested_fn = args.get('--nested-cascade', "../../data/haarcascades/haarcascade_eye.xml")
cascade = cv2.CascadeClassifier(cascade_fn)
nested = cv2.CascadeClassifier(nested_fn)
cam = create_capture(video_src, fallback='synth:bg=../data/friend/friendImage/image'+str(i)+'.jpg:noise=0.05')
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
rects = detect(gray, cascade)
vis = img.copy()
draw_rects(vis, rects, (0, 255, 0))
if not nested.empty():
if len(rects) == 0:
print('none')
else:
count = count + 1
print(str(count))
input()
执行以上代码统计出最后的结果
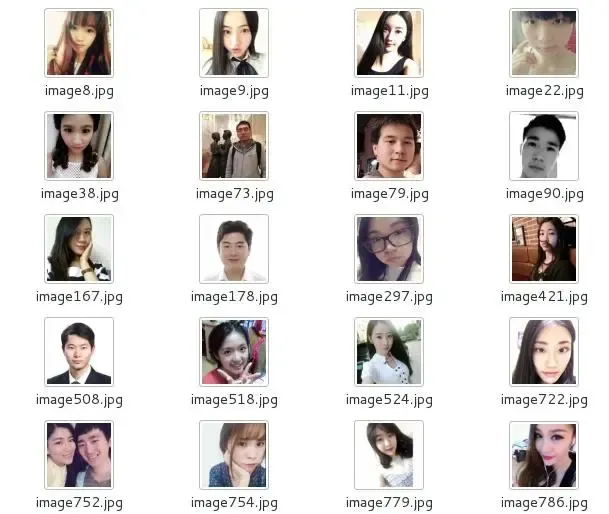
使用人像做头像的好友:59 因此不使用人像的1133,看来使用人像的人还是很少的。
运行提取人像头像的代码最后提取出的头像如下所示 ,不得不说Python的库真是十分的有用。(因为涉及到隐私,所以这里不会展示过多的头像)
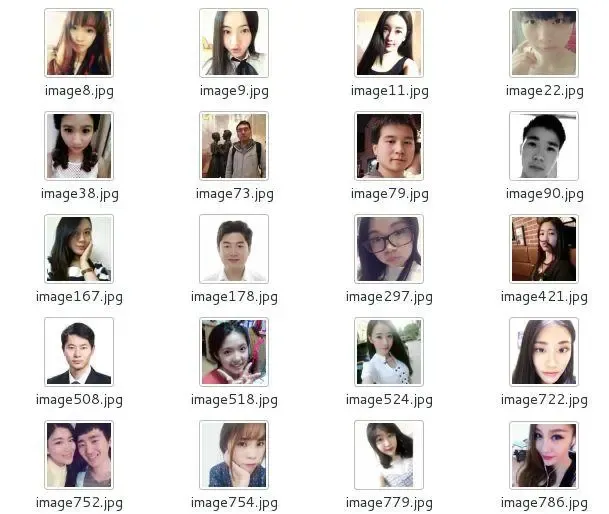
最近仍然在研究签名以及头像的可用之处,也是欢迎大家一起学习交流。同时希望以上的内容可以提升一下大家的学习兴趣。关于微信好友的更多挖掘会不断进行。
(1)、人像头像与年龄之间的关系(由于微信没有年龄,于是想通过知乎进行推算)
(2)、个性签名与年龄性格之间的关系
(3)、微信号中所包含信息推算年龄层次,预测当前微信号年龄






