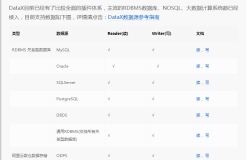
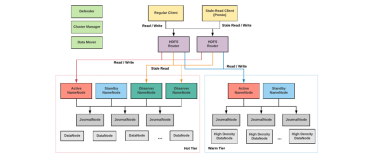
HDFS快照是一个只读的基于时间点文件系统拷贝。快照可以是整个文件系统的 也可以是一部分。常用来作为数据备份,防止用户错误和容灾快照功能。
HDFS实现功能:
- Snapshot 创建的时间 复杂度为O(1),但是不包括INode 的寻找时间
- 只有当修改SnapShot时,才会有额外的内存占用,内存使用量为O(M),M 为修改的文件 或者目录数
- 在DataNode上面的blocks 不会复制,做Snapshot 的文件是纪录了block的列表和文件的 大小,但是没有数据的复制
- Snapshot 并不会影响HDFS 的正常操作:修改会按照时间的反序记录,这样可以直接读 取到最新的数据。快照数据是当前数据减去修改的部分计算出来的。
快照命令
- 设置一个目录为可快照
$ bin/hdfs dfsadmin -allowSnapshot <path> - 取消目录可快照
$ bin/hdfs dfsadmin -disallowSnapshot <path> - 生成快照
$ bin/hdfs dfs -createSnapshot <path> [<snapshotName>] - 删除快照
$ bin/hdfs dfs -deleteSnapshot <path> <snapshotName> - 列出所有可快照目录
$ bin/hdfs lsSnapshottableDir - 比较快照之间的差异
$ bin/hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
具体例子看光官网