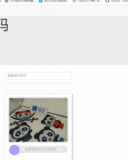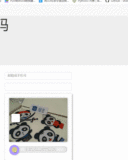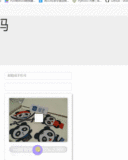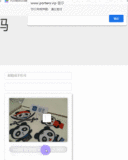
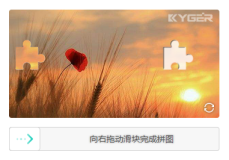
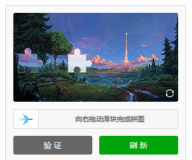
最近在搞爬虫的时候在好几个网站都碰到了一种叫做geetest的滑动条验证码,一直没有太好的办法只能在触发这个验证码后发个报警去手动处理一下。http://www.geetest.com/exp_embed是他们官网的样例。

后来研究了下觉得要破解这个验证码有这么几个问题:
无法直接通过发送url请求来实现鼠标拖动的动作;
实际的背景图片是乱的,并不是我们实际肉眼看到的图像,如下图;
“开创行为判别算法,利用数据挖掘和机器学习,提取超过200多个行为判别特征,建立坚若磐石的多维验证防御体系。”这是官网的描述,听上去就已经很高大上,查了些资料也都说拖动轨迹的识别是geetest的核心内容而无过多的表述,那么这也应该是主要的难点了。
后面我也就基于了以上的问题去一步一步研究如何实现模拟这一操作:
一.安装配置geetest的样例
首先自己安装配置一份geetest的样例。虽然geetest官网上有样例,但有时候反应比较慢,而且后面研究拖动轨迹的时候还需要对样例做一定的改动。编程语言我使用的是python2.7,所以这里选择的也是Python版本的。
参考内容:http://www.geetest.com/install/sections/idx-server-sdk.html#python
安装Git:
[root@mysql-test1 ~]# yum install git
在github中clone出最新Demo项目:
[root@mysql-test1 ~]# git clone https://github.com/GeeTeam/gt-python-sdk.git
安装GeetestSDK:
[root@mysql-test1 ~]# cd gt-python-sdk/ [root@mysql-test1 gt-python-sdk]# python setup.py install
安装Django,要注意的是最新的Django-1.10.1和当前的GeetestSDK是有兼容性问题的,要用Django-1.8.14:
[root@mysql-test1 ~]# wget --no-check-certificate https://www.djangoproject.com/download/1.8.14/tarball/ [root@mysql-test1 ~]# tar zxvf Django-1.8.14.tar.gz [root@mysql-test1 ~]# cd Django-1.8.14 [root@mysql-test1 Django-1.8.14]# python setup.py install
后面就可以直接运行了:
[root@mysql-test1 ~]# cd gt-python-sdk/demo/django_demo/ [root@mysql-test1 django_demo]# python manage.py runserver 0.0.0.0:8000
另外如果安装启动的时候报sqlite相关的错误,那就要安装Linux的sqlite-devel包,然后再编译安装python就可以了。
现在在浏览器里打开http://192.168.161.51:8000/就可以看到安装的geetest样例了。
另外还可以把gt-python-sdk/demo/django_demo/static/index.html里面41-61行注释掉,只保留嵌入式的Demo。
二.在浏览器上模拟鼠标拖动的操作
参考内容:http://www.cnblogs.com/wangly/p/5630069.html
这里要实现鼠标拖动的动作靠直接发送url请求是无法实现的,需要有个真的浏览器再去模拟鼠标拖动的动作。根据参考的内容使用了Selenium(也有python版本的)可以实现这一操作。
通过python的pip可以直接安装,我这里显示的版本是selenium-2.53。除此之外还需要根据浏览器下载webdriver。我使用的是chrome,驱动在http://download.csdn.net/detail/paololiu/9620177有下载,下载完后解压放到chrome的安装目录即可。另外还要注意chrome的版本,我这里使用的是52.0.2743.116。
#!/usr/local/bin/python
# -*- coding: utf8 -*-
'''
Created on 2016年9月2日
@author: PaoloLiu
'''
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
import time
def main():
# 这里的文件路径是webdriver的文件路径
driver = webdriver.Chrome(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
# 打开网页
driver.get("http://192.168.161.51:8000/")
# 等待页面的上元素刷新出来
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_slider_knob gt_show']").is_displayed())
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_cut_bg gt_show']").is_displayed())
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_cut_fullbg gt_show']").is_displayed())
# 找到滑动的圆球
element=driver.find_element_by_xpath("//div[@class='gt_slider_knob gt_show']")
# 鼠标点击元素并按住不放
print "第一步,点击元素"
ActionChains(driver).click_and_hold(on_element=element).perform()
time.sleep(1)
print "第二步,拖动元素"
# 拖动鼠标到指定的位置,注意这里位置是相对于元素左上角的相对值
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=200, yoffset=50).perform()
time.sleep(1)
print "第三步,释放鼠标"
# 释放鼠标
ActionChains(driver).release(on_element=element).perform()
time.sleep(3)
if __name__ == '__main__':
pass
main()
三.计算图片中缺口的偏移量
参考内容:http://www.cnblogs.com/yuananyun/p/5655019.html
上面的移动位置我写了一个固定的值,实际情况这个值是不固定的,需要根据背景图片的缺口来算出这个偏移量。然而要计算缺口的偏移量还要先还原图片。
1.还原图片
如上图,原始的图片是乱的,但是我们可以在html里面可以看到把同一个图片的位置进行重新组合就可以看到还原后的图片了:
代码如下:
import PIL.Image as image
import PIL.ImageChops as imagechops
import time,re,cStringIO,urllib2,random
def get_merge_image(filename,location_list):
'''
根据位置对图片进行合并还原
:filename:图片
:location_list:图片位置
'''
pass
im = image.open(filename)
new_im = image.new('RGB', (260,116))
im_list_upper=[]
im_list_down=[]
for location in location_list:
if location['y']==-58:
pass
im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,166)))
if location['y']==0:
pass
im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))
new_im = image.new('RGB', (260,116))
x_offset = 0
for im in im_list_upper:
new_im.paste(im, (x_offset,0))
x_offset += im.size[0]
x_offset = 0
for im in im_list_down:
new_im.paste(im, (x_offset,58))
x_offset += im.size[0]
return new_im
def get_image(driver,div):
'''
下载并还原图片
:driver:webdriver
:div:图片的div
'''
pass
#找到图片所在的div
background_images=driver.find_elements_by_xpath(div)
location_list=[]
imageurl=''
for background_image in background_images:
location={}
#在html里面解析出小图片的url地址,还有长高的数值
location['x']=int(re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][1])
location['y']=int(re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][2])
imageurl=re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][0]
location_list.append(location)
imageurl=imageurl.replace("webp","jpg")
jpgfile=cStringIO.StringIO(urllib2.urlopen(imageurl).read())
#重新合并图片
image=get_merge_image(jpgfile,location_list )
return image
2.计算缺口位置
通过python的PIL.ImageChops可以计算出两个图片不同地方的位置,方法如下:
import PIL.ImageChops as imagechops diff=imagechops.difference(image1, image2) diff.show() print diff.getbbox()
但是这在我们这里并不适用。因为我们得到的两个图片是通过拼接而成的,并且两张原图在背景上也还是稍有区别的,而difference方法计算得过于精确,所以这里得到的位置并不会是我们要的缺口的位置。这里我借用的参考内容的方法:两张原始图的大小都是相同的260*116,那就通过两个for循环依次对比每个像素点的RGB值,如果相差超过50则就认为找到了缺口的位置:
def is_similar(image1,image2,x,y): ''' 对比RGB值 ''' pass pixel1=image1.getpixel((x,y)) pixel2=image2.getpixel((x,y)) for i in range(0,3): if abs(pixel1[i]-pixel2[i])>=50: return False return True def get_diff_location(image1,image2): ''' 计算缺口的位置 ''' i=0 for i in range(0,260): for j in range(0,116): if is_similar(image1,image2,i,j)==False: return i
四.鼠标拖动的轨迹
1.输出鼠标滑动轨迹
参考内容:http://blog.csdn.net/ieternite/article/details/51483491
如果我们直接把上面算出来的缺口位置放到前面脚本里,你会发现即使移动的位置正确了,提示却是“怪物吃了饼图”,验证不通过。很显然,geetest识别出了这个动作并不是人的行为。这我们就需要去查看自然人滑动鼠标和我们代码实现的滑动在轨迹上有什么不同。
geetest目前版本客户端最核心的是geetest.5.5.36.js,我们可以把它复制出来加以改造。首先找个工具把原代码格式化一下,然后再加入以下的内容:
index.html页面的上直接调用的是gt.js,再由gt.js去调用geetest.5.5.36.js。我用的土办法是自己搭建一个简易的web server,并在host里面把static.geetest.com域名指向到我自己的web server,然后再把页面上要调用的static.geetest.com里的内容都放到我自己搭建的web server上,当然geetest.5.5.36.js是要用我刚才改造过的那个。
static.geetest.com里面只要static目录里的内容即可,pictures里面的图片找不到会自动指向到他们备用的网站的。我用的简易web server是HTTP File Server,可以在下载。
如此一来,我们每次滑动鼠标包括代码实现的滑动操作在浏览器里都能显示出滑动的轨迹:
2.模拟人的行为
有了轨迹的数据,我们就可以进行对比分析了。上图的是我手动滑动的轨迹,而下图的是我通过代码拖动的轨迹,其实根本就不需要涉及到什么复杂的数据挖掘机器学习的算法,两眼一看就能识别出不同来:
这里我总结了一下差别(一个{x,y,z}是一个轨迹记录点,x代表x轴,y代表y轴,z代表累计时间毫秒):
1.时间不宜太长又或者太短,最好能控制在1-5秒之内,另外两个相邻的记录点的时间也最好能控制在50ms以内,并且间隔的时间也不宜相同;
2.乡邻的x值差值也不宜太大,最好控制在以5内,并且差值也不要是一层不变的;
3.geetest虽然是横向拖动的,不会涉及到纵向移动,所以这部分很容易是被忽略的:y轴的值要控制在[-5,5]范围内,不能过大。而且上下抖动的频率不能高,要平缓一点。我试下来最好的办法就是平稳固定的0上,也不要上下抖动了。
完整代码如下:
#!/usr/local/bin/python
# -*- coding: utf8 -*-
'''
Created on 2016年9月2日
@author: PaoloLiu
'''
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
import PIL.Image as image
import time,re,cStringIO,urllib2,random
def get_merge_image(filename,location_list):
'''
根据位置对图片进行合并还原
:filename:图片
:location_list:图片位置
'''
pass
im = image.open(filename)
new_im = image.new('RGB', (260,116))
im_list_upper=[]
im_list_down=[]
for location in location_list:
if location['y']==-58:
pass
im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,166)))
if location['y']==0:
pass
im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))
new_im = image.new('RGB', (260,116))
x_offset = 0
for im in im_list_upper:
new_im.paste(im, (x_offset,0))
x_offset += im.size[0]
x_offset = 0
for im in im_list_down:
new_im.paste(im, (x_offset,58))
x_offset += im.size[0]
return new_im
def get_image(driver,div):
'''
下载并还原图片
:driver:webdriver
:div:图片的div
'''
pass
#找到图片所在的div
background_images=driver.find_elements_by_xpath(div)
location_list=[]
imageurl=''
for background_image in background_images:
location={}
#在html里面解析出小图片的url地址,还有长高的数值
location['x']=int(re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][1])
location['y']=int(re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][2])
imageurl=re.findall("background-image: url\(\"(.*)\"\); background-position: (.*)px (.*)px;",background_image.get_attribute('style'))[0][0]
location_list.append(location)
imageurl=imageurl.replace("webp","jpg")
jpgfile=cStringIO.StringIO(urllib2.urlopen(imageurl).read())
#重新合并图片
image=get_merge_image(jpgfile,location_list )
return image
def is_similar(image1,image2,x,y):
'''
对比RGB值
'''
pass
pixel1=image1.getpixel((x,y))
pixel2=image2.getpixel((x,y))
for i in range(0,3):
if abs(pixel1[i]-pixel2[i])>=50:
return False
return True
def get_diff_location(image1,image2):
'''
计算缺口的位置
'''
i=0
for i in range(0,260):
for j in range(0,116):
if is_similar(image1,image2,i,j)==False:
return i
def get_track(length):
'''
根据缺口的位置模拟x轴移动的轨迹
'''
pass
list=[]
# 间隔通过随机范围函数来获得
x=random.randint(1,3)
while length-x>=5:
list.append(x)
length=length-x
x=random.randint(1,3)
for i in xrange(length):
list.append(1)
return list
def main():
# 这里的文件路径是webdriver的文件路径
driver = webdriver.Chrome(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
# driver = webdriver.Firefox()
# 打开网页
driver.get("http://172.16.2.7:8000/")
# 等待页面的上元素刷新出来
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_slider_knob gt_show']").is_displayed())
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_cut_bg gt_show']").is_displayed())
WebDriverWait(driver, 30).until(lambda the_driver: the_driver.find_element_by_xpath("//div[@class='gt_cut_fullbg gt_show']").is_displayed())
# 下载图片
image1=get_image(driver, "//div[@class='gt_cut_bg gt_show']/div")
image2=get_image(driver, "//div[@class='gt_cut_fullbg gt_show']/div")
# 计算缺口位置
loc=get_diff_location(image1, image2)
# 生成x的移动轨迹点
track_list=get_track(loc)
# 找到滑动的圆球
element=driver.find_element_by_xpath("//div[@class='gt_slider_knob gt_show']")
location=element.location
# 获得滑动圆球的高度
y=location['y']
# 鼠标点击元素并按住不放
print "第一步,点击元素"
ActionChains(driver).click_and_hold(on_element=element).perform()
time.sleep(0.15)
print "第二步,拖动元素"
track_string = ""
for track in track_list:
track_string = track_string + "{%d,%d}," % (track, y - 445)
# xoffset=track+22:这里的移动位置的值是相对于滑动圆球左上角的相对值,而轨迹变量里的是圆球的中心点,所以要加上圆球长度的一半。
# yoffset=y-445:这里也是一样的。不过要注意的是不同的浏览器渲染出来的结果是不一样的,要保证最终的计算后的值是22,也就是圆球高度的一半
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=track+22, yoffset=y-445).perform()
# 间隔时间也通过随机函数来获得
time.sleep(random.randint(10,50)/100)
print track_string
# xoffset=21,本质就是向后退一格。这里退了5格是因为圆球的位置和滑动条的左边缘有5格的距离
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=21, yoffset=y-445).perform()
time.sleep(0.1)
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=21, yoffset=y-445).perform()
time.sleep(0.1)
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=21, yoffset=y-445).perform()
time.sleep(0.1)
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=21, yoffset=y-445).perform()
time.sleep(0.1)
ActionChains(driver).move_to_element_with_offset(to_element=element, xoffset=21, yoffset=y-445).perform()
print "第三步,释放鼠标"
# 释放鼠标
ActionChains(driver).release(on_element=element).perform()
time.sleep(3)
# 点击验证
submit=driver.find_element_by_xpath("//input[@id='embed-submit']")
ActionChains(driver).click(on_element=submit).perform()
time.sleep(5)
driver.quit()
if __name__ == '__main__':
pass
main()
运行结果:
五.浏览器的兼容问题
1.最为重要的就是代码注释里说的y轴的高度问题,我试了PhantomJS,Chrome和Firefox三个浏览器,每一种渲染出来的高度都是不一样的,一定要保证最终的结果是拖动球高度的一半(一般都是22);
2.版权兼容性(以下是我验证过可行的):
selenium (2.53.6)===>PhantomJS 2.1
selenium (2.53.6)===>Chrome 52
selenium (2.53.6)===>Firefox 45(注意不要用48,有兼容问题)
3.webdriver的cookie问题:
有的时候我们需要带入cookie进行验证,那就有了cookie的问题了。Chrome和Firefox都可以通过webdriver.add_cookie来实现,但是经我试下来这个方法和PhantomJS有兼容性问题,我是这样解决的:
def save_cookies(self, driver, file_path, inputcookie):
# LINE = "document.cookie = '{name}={value}; path={path}; domain={domain}; expires={expires}';\n"
dict_cookie = {}
for item in inputcookie.split(";"):
dict_cookie[item.split("=")[0].strip()] = item.split("=")[1].strip()
# logging.info(dict_cookie)
with open(file_path, 'w') as file :
for cookie in driver.get_cookies() :
# logging.info(cookie)
if u'expires' in cookie:
if cookie['name'] in dict_cookie:
line = "document.cookie = '%s=%s; path=%s; domain=%s; expires=%s';\n" % (cookie['name'], dict_cookie[cookie['name']], cookie['path'], cookie['domain'], cookie['expires'])
else:
line = "document.cookie = '%s=%s; path=%s; domain=%s; expires=%s';\n" % (cookie['name'], cookie['value'], cookie['path'], cookie['domain'], cookie['expires'])
else:
if cookie['name'] in dict_cookie:
line = "document.cookie = '%s=%s; path=%s; domain=%s';\n" % (cookie['name'], dict_cookie[cookie['name']], cookie['path'], cookie['domain'])
else:
line = "document.cookie = '%s=%s; path=%s; domain=%s';\n" % (cookie['name'], cookie['value'], cookie['path'], cookie['domain'])
# logging.info(line)
file.write(line.encode("utf8"))
def load_cookies(self, driver, file_path):
with open(file_path, 'r') as file:
driver.execute_script(file.read())
再如此调用就可以解决cookie的兼容性问题了:
driver.get(url) # save the cookies to a file self.save_cookies(driver, r"cookies.js", cookies) # delete all the cookies driver.delete_all_cookies() # load the cookies from the file self.load_cookies(driver, r"cookies.js") # reopen url driver.get(url)
4.PhantomJS浏览器解析出来的图片url是不带引号的,而Firefox和Chrome解析出来的是带引号的,这里正则过滤的时候要注意一下的。
我最终使用的是selenium+Firefox。我实际运行的环境是centos,PhantomJS确实是个不错的选择,直接在shell里运行就可以了,不需要配置图形界面。但是使用下来破解的成功率不高,因为没有界面,也看不出运行的情况。Chrome在centos6.5里面没有现成的安装包,安装使用比较复杂。最终也就只有Firefox了。
centos配置firefox方法如下:
[root@db2-test1 ~]# yum groupinstall "X Window System" -y [root@db2-test1 ~]# yum groupinstall "Desktop" -y [root@db2-test1 ~]# yum install firefox -y
注意不要纯shell环境下运行,要在图形界面的运行。运行init 5可以从字符界面切换到图形界面。