

机器学习领域的裙带关系:不知名大学的好论文 VS 顶级实验室的好论文
今天Reddit发出了一个讨论,有用户指出他观察到的奇怪现象:
这可能是个带点争议性的话题。我最近注意到领域里存在很多裙带关系,我觉得需要指出一下。
今年NIPS的深度强化学习研讨会(Deep RL Symposium),12个演讲中有7个都来自伯克利的两个研究组。虽然这个研讨会上确实有这两个组的很多篇论文,但这个研讨会一共接收了80多篇论文,来自不同的研究组,这些论文原本也该得到关注。论文的选择过程是双盲的,但我忍不住怀疑演讲的选择不是。尤其是研讨会组的织者中,有一半(6人中的3人)与前面说的那两个实验室有着某种关联。
我很高兴强化学习终于有了比较高的认知度,但我也认为我们应该在研究传播的过程中保持谨慎。
对此,用户duh_cats表示,正是因为机器学习现在火了,这种学术圈早已普遍存在的现象也开始在机器学习领域凸显。“WELCOME!热烈欢迎来到一个蓬勃发展的学科,这里还有更多趣事等你来体验。”
用户metacurse给出了如下总结:
- 不知名大学的好论文:只有审稿人看过,仔细评分,然后发表
- 顶级实验室(Bengio/DeepMind/etc)的好论文:审稿人看过,适度评一评。作者,往往在Twitter上拥有几千乃至几万粉丝,在Twitter上把文章一发,论文在Twitter上得到更多关注。大家从论文的表述而非实际贡献来判断工作是否具有原创性(Novelty)。MIT科技评论、纽约时报等媒体,从最简单的概念里推导出最泛泛(generic)的功能,然而写标题党文章。论文作者成了领域中很小一处地盘的“思想领袖”,然后受邀到世界各地发表演讲。
metacurse甚至指名道姓地举出两个Twitter大V,说不知怎的他们如今成了元学习(meta-learning)的领袖,实际上两人的研究并不是很具原创性。
metacurse的评论显然将问题过分简化,并且描述了极端情况。同时,考虑到Reddit社区论坛的特性,这里更多是在闲聊。但是,不可否认,他确实戳到了一个痛点。
而且在这里,我们都甚至不需要展开去谈双盲评审的有效性。
知名学者和大V在论文传播中的“影响因子”
讨论中还引出了前不久谷歌大脑的一项工作。出身于谷歌大脑,并且还有GAN发明人,也是Twitter大V的Ian Goodfellow转发评述,这篇文章很快获得了很多关注。
谷歌大脑团队的研究者在ArXiv上传了题为“Are GANs Created Equal? A Large-Scale Study”的论文,对MM GAN、NS GAN、WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN等近期出现的优秀GAN模型进行了比较,然后在摘要中写道:“我们没有发现本研究所测试的任何一个算法一直优于原始算法的证据。”
GAN的发明人Ian Goodfellow(他本人并没有参与这项工作)在Twitter评论称:ML的研究人员、审稿人和有关ML的新闻报道,需要对结果的统计稳健性和超参数的效果进行更认真的研究。这项研究表明,过去一年多的很多论文只是观察抽样误差,而不是真正的改进。论文:https://arxiv.org/pdf/1711.10337.pdf
但是,有人很快就指出了这篇文章的缺点。
Reddit用户NichG评论:
“这篇论文宣称要纠察GAN研究方法中的不足,也即专门挑选好的结果来展示(cherry-picking),然而自己在方法上恰恰就犯了这样的错误。”
NichG评论说,广泛的超参数搜索要查找包括学习率在内的很多东西的值。这导致论文中Frechet Inception Distance(FID)分数看起来令人绝望。狭义搜索的结果更为合理,也能显示出系统性的差异,但是这个数字被淹没在附录D中。
在分析实际数字的时候,第6.2节末尾有一个表格,用来比较模型和数据集。尽管论文的摘要声称没有找到证据表明任何测试的算法“总是胜过”原始数据,但该表显示平均FID得分实际上相差好几个标准偏差,而且最高排名也并不稳定。除MNIST外,每个数据集的最高排名都是WGAN或WGAN-GP,与下一个排名的差异在5到10个标准差之间。对于MNIST,WGAN和WGAN-GP也在最高排名的NS GAN的误差范围内。看平均排名,结果也一样。WGAN-GP的平均值比WGAN的平均值低了一个标准差,而WGAN的平均值比DRAGAN低一个多标准差。
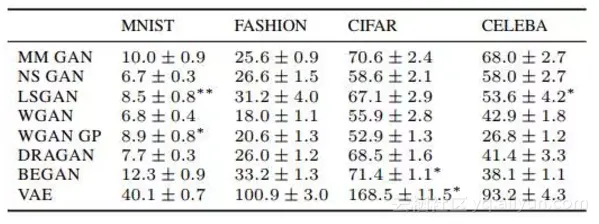
这样看,谷歌大脑论文摘要中所说的“没有证据”就很奇怪了。我猜这是因为这总比说,“我们发现了系统性差异的证据,但这些差异取决于可用的计算资源”(WGAN收敛的速度明显要慢)要好。
这篇论文真正展示的是,不同的GAN在不同的情况下需要权衡,如果作者得出这个结论,那我不会有任何问题。然而,这篇论文却把自己定位成对GAN研究方法标准的批评,而这些标准并没有被它实际发现的东西所支持。就这一点而言,这有点像是有人先写出了结论,然后试图通过数据呈现的方式来支持这些结论。
这实在令人遗憾,因为本文中的实验对这些GAN进行了彻底的描述,这对研究社区来说是切实有用的。但它却被掩埋在了过分夸大的声明下面。我原本并不会这么恼火,但是有太多的人,在看完摘要后说“我就知道是这样!”也不去检查实际的结果,实在忍不住才写下这段话。
结语
裙带关系任何一个研究领域都有,依靠论文发表数量和引用的时候这种情况尤甚。“吸引人”和“真实可靠”之间难免存在权衡。而科学传播就更是一门科学,欢迎留下评论,说说你的看法。
原文发布时间为:2017-12-4
本文作者:闻菲
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号



