
这篇文章始于对这么个程序的思考:
| int main(int argc, char* argv[]) { int i=1234567; DWORD dwWrite; HANDLE hFile = CreateFile("test.txt", GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); WriteFile(hFile, &i, sizeof(int), &dwWrite, NULL); CloseHandle(hFile); return 0; } |
用二进制编辑器(如UltraEdit)打开程序输出结果文件“test.txt”查看,结果是:“87 D6 12 00”。如果将87D61200直接输入计算器,转变成十进制数,那就是2278953472,并非我们所期待的1234567,但如果把这几个十六进制数倒过来,输入0012D687到计算器,转成十进制数,就出现了我们想要的结果,1234567。这是一个字节序的问题,但在讨论这个之前,我想先来讨论下内存的表示。
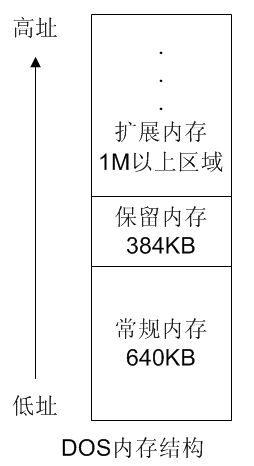
粗一想,这根本不是问题,把内存地址和数据以表的形式列出来不就行了么?但仔细一想,确实还有些要斟酌之处。因为:我们对内存“写生”到纸上就有上下左右方位之分,而真实的内存,并没有上下左右这些方位的概念,只有“高位”和“低位”的概念,内存电子元器件所表示的那些“0”和“1”是连续的。那究竟把高位画在上还是画在下?或者左?或者右?下面我来说说我的理解,按照我们常规思维,“高”通常就代表“上”,“低”就代表“下”,不仅我们中国人如此,发明电脑的老美也如此,DOS的内存管理中有个“上位内存”的概念,上位内存英文就是“Upper Memory Block”,居高位,在常规内存之上的意思,看来上高下低是没什么问题了吧。
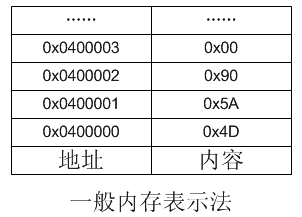
那如果我们有张纸条,必须要左右绘表来描述内存,那究竟左高还是右高?其实这也是比较明显的,像1234567这个整数,1明显居高位,它是最有效力的数字,它在最左边,所以应该用左边来表示高位,这样和我们的思维习惯比较相符,如果这个理由还不够充分,那我这里就插入“位运算”来讲一下。
| int main(int argc, char* argv[]) { unsigned char c, d, e; c=38; //c == 100110 (binary) d=c>>1; //d == 10011 (binary) e=c<<1; //e == 1001100 (binary) return 0; } |
“>>”是右位移运算符(bitwise right shift operator),“<<”是左位移运算符(bitwise left shift operator),而从这个简单的程序上看来,它们确实执行了我们常规思维中所理解的左右位移,左移使得低位变为高位,“增值”,右移使得高位变为低位,“贬值”,看来左边表示高位,右边表示低位,也是没有什么疑义的了。
但!你发现没有,这种表示规则和我们的阅读习惯,书写习惯完全相反。我们人类写字都是从左到右,从上到下,(BTW:OK,我承认日本人有从右到左的习惯,但这里就别钻牛角尖了,嘿嘿)如何见得这个冲突?看下面的代码:
| char szArray[10] ={'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', '/0'}; |
我们给szArray这个数组赋初值,这么一来,你认为szArray[0],szArray[1]分别是哪个字符?那还用想么?当然分别是“a”和“b”,那么szArray[0]居低位,还是szArray[1]居低位?那也根本不用想,当然是szArray[0]居低位,但回头看看我们的赋值语句,“a”是写在“b”的左边的,但它却居低位而非高位。所以我认为人的习惯还是从上往下,从左往右,把低的东西写到高,把小的东西写到大。至于为什么会这样,我也无法回答,可能要去请教下生物学家。看下面这个截图,正好说明了这点,这是VC++中的内存表示法,明显和我前面推荐的表示法相反,低位居上居左,高位居下居右。

那说了半天究竟要用哪种表示法?怎样?知道这个是个问题了吧。我这里也没有标准答案,事实上两种表示法都会出现在实际应用中,所以都需要适应。但有一点必须强调,要不就上左高位,要不就上左低位,不存在上高左低或上低左高。
好了,回到文章开始的那个字节序的问题,我曾经被这个字节序的问题弄得糊里糊涂,现在终于想明白,其实我当时之所以这么难明白,主要就是字节序这个英文单词(endian)太能误导人。endian这个单词在传统词典里是查不到的,但看到前边的“end”就容易让人想起“结束”,这真是个大错误,其实它和结束没有任何关系,看它的英文解释:The ordering of bytes in a multi-byte number,翻译为“字节序”就合适了。
目前有两种常见的字节序,即“big-endian”和“little-endian”,如果你认为“endian”含有“结束”的意思的话这里就出差错了,因为如果内存用“开始”和“结束”来描述本来就是很不清晰的,只能用“高位”和“低位”来描述,“big-endian”是把最有效力的数放在低位(这里姑且把“低位”算“开始”吧),而“little-endian”正好相反,把最没效力的数放在低位。
字节序的采用和系统有关系,目前PC机上的系统都是“little-endian”,很明显,我调试开篇程序的这个系统使用的也是“little-endian”,据称Mac机则使用“big-endian”,可惜我只用过PC机,所以没法在此证实了。
由于各种系统使用的字节序可能不同,系统对数字的理解就有可能不同,那如果系统之间传输数字信息的时候就可能出乱子,比如我用PC机把整型数“1234567”传输到一台Mac机去,Mac机就会把这个数字理解成“2278953472”,相差不是一点点。所以这里就涉及到字节序转换的问题。也就是那几个常用的函数:htons,htonl,ntohs,ntohl。这里就不展开说了。最后还有个问题,假如两个系统用的都是同一种字节序,那在它们之间传输数据是否还需要用这几个函数转换字节序?答案是最好用,因为网络也有它自己的字节序(big-endian),一些包在网上传输的时候可能要设置一些要让网络理解的参数,这种转换还是必须的,尽管有时候看起来不转换也没问题,但大家都依循这个规则不是更好么?
