Introduction
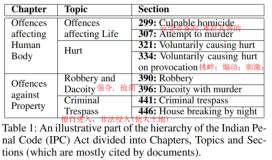
The reason for the current work is to analyze different methods for efficent delivery of network events from kernel mode to user mode. Five methods are examined, poll() that has been chosen as the better old-style method, standard /dev/poll interface, standard RT signals, RT signals with one-sig-per-fd patch and a new /dev/epoll that uses a quite different notification method. This work is composed by :
1) the new /dev/epoll kernel patch
2) the /dev/poll patch from Provos-Lever modified to work with 2.4.6
3) the HTTP server
4) the deadconn(tm) tool to create "dead" connections
As a measurement tool httperf has been chosen coz, even if not perfect, it offers a quite sufficent number of loading options.
The new /dev/epoll kernel patch
The patch is quite simple and it adds notification callbacks to the 'struct file' data structure :
******* include/linux/fs.h
struct file {
...
/* file callback list */
rwlock_t f_cblock;
struct list_head f_cblist;
};
****** include/linux/fcblist.h
/* file callback notification events */
#define ION_IN 1
#define ION_OUT 2
#define ION_HUP 3
#define ION_ERR 4
#define FCB_LOCAL_SIZE 4
#define fcblist_read_lock(fp, fl) read_lock_irqsave(&(fp)->f_cblock, fl)
#define fcblist_read_unlock(fp, fl) read_unlock_irqrestore(&(fp)->f_cblock, fl)
#define fcblist_write_lock(fp, fl) write_lock_irqsave(&(fp)->f_cblock, fl)
#define fcblist_write_unlock(fp, fl) write_unlock_irqrestore(&(fp)->f_cblock, fl)
struct fcb_struct {
struct list_head lnk;
void (*cbproc)(struct file *, void *, unsigned long *, long *);
void *data;
unsigned long local[FCB_LOCAL_SIZE];
};
extern long ion_band_table[];
extern long poll_band_table[];
static inline void file_notify_init(struct file *filep)
{
rwlock_init(&filep->f_cblock);
INIT_LIST_HEAD(&filep->f_cblist);
}
void file_notify_event(struct file *filep, long *event);
int file_notify_addcb(struct file *filep,
void (*cbproc)(struct file *, void *, unsigned long *, long *), void *data);
int file_notify_delcb(struct file *filep,
void (*cbproc)(struct file *, void *, unsigned long *, long *));
void file_notify_cleanup(struct file *filep);
The meaning of this callback list is to give lower IO layers the ability to notify upper layers that will register their "interests" to the file structure. In fs/file_table.c initialization and cleanup code has been added while in fs/fcblist.c the callback list handling code has been fit :
****** fs/file_table.c
struct file * get_empty_filp(void)
{
...
file_notify_init(f);
...
}
int init_private_file(struct file *filp, struct dentry *dentry, int mode)
{
...
file_notify_init(filp);
...
}
void fput(struct file * file)
{
...
file_notify_cleanup(file);
...
}
****** fs/fcblist.c
void file_notify_event(struct file *filep, long *event)
{
unsigned long flags;
struct list_head *lnk;
fcblist_read_lock(filep, flags);
list_for_each(lnk, &filep->f_cblist) {
struct fcb_struct *fcbp = list_entry(lnk, struct fcb_struct, lnk);
fcbp->cbproc(filep, fcbp->data, fcbp->local, event);
}
fcblist_read_unlock(filep, flags);
}
int file_notify_addcb(struct file *filep,
void (*cbproc)(struct file *, void *, unsigned long *, long *), void *data)
{
unsigned long flags;
struct fcb_struct *fcbp;
if (!(fcbp = (struct fcb_struct *) kmalloc(sizeof(struct fcb_struct), GFP_KERNEL)))
return -ENOMEM;
memset(fcbp, 0, sizeof(struct fcb_struct));
fcbp->cbproc = cbproc;
fcbp->data = data;
fcblist_write_lock(filep, flags);
list_add_tail(&fcbp->lnk, &filep->f_cblist);
fcblist_write_unlock(filep, flags);
return 0;
}
int file_notify_delcb(struct file *filep,
void (*cbproc)(struct file *, void *, unsigned long *, long *))
{
unsigned long flags;
struct list_head *lnk;
fcblist_write_lock(filep, flags);
list_for_each(lnk, &filep->f_cblist) {
struct fcb_struct *fcbp = list_entry(lnk, struct fcb_struct, lnk);
if (fcbp->cbproc == cbproc) {
list_del(lnk);
fcblist_write_unlock(filep, flags);
kfree(fcbp);
return 0;
}
}
fcblist_write_unlock(filep, flags);
return -ENOENT;
}
void file_notify_cleanup(struct file *filep)
{
unsigned long flags;
struct list_head *lnk;
fcblist_write_lock(filep, flags);
while ((lnk = list_first(&filep->f_cblist))) {
struct fcb_struct *fcbp = list_entry(lnk, struct fcb_struct, lnk);
list_del(lnk);
fcblist_write_unlock(filep, flags);
kfree(fcbp);
fcblist_write_lock(filep, flags);
}
fcblist_write_unlock(filep, flags);
}
The callbacks will receive a 'long *' whose first element is one of the ION_* events while the nexts could store additional params whose meaning will vary depending on the first one. This interface is a draft and I used it only to verify if the transport method is efficent "enough" to work on. At the current stage notifications has been plugged only inside the socket files by adding :
****** include/net/sock.h
static inline void sk_wake_async(struct sock *sk, int how, int band)
{
if (sk->socket) {
if (sk->socket->file) {
long event[] = { ion_band_table[band - POLL_IN], poll_band_table[band - POLL_IN], -1 };
file_notify_event(sk->socket->file, event);
}
if (sk->socket->fasync_list)
sock_wake_async(sk->socket, how, band);
}
}
The files fs/pipe.c and include/linux/pipe_fs_i.h has been also modified to extend /dev/epoll to pipes ( pipe() ).
The /dev/epoll implementation resides in two new files driver/char/eventpoll.c and the include/linux/eventpoll.h include file.
The interface of the new /dev/epoll is quite different from the previous one coz it works only by mmapping the device file descriptor while the copy-data-to-user-space has been discarded for efficiency reasons. By avoiding unnecessary copies of data through a common set of shared pages the new /dev/epoll achieves more efficency due 1) less CPU cycles needed to copy the data 2) a lower memory footprint with all the advantages on modern cached memory architectures.
The /dev/epoll implementation uses the new file callback notification machanism to register its callbacks that will store events inside the event buffer. The initialization sequence is :
if ((kdpfd = open("/dev/epoll", O_RDWR)) == -1) {
}
if (ioctl(kdpfd, EP_ALLOC, maxfds))
{
}
if ((map = (char *) mmap(NULL, EP_MAP_SIZE(maxfds), PROT_READ,
MAP_PRIVATE, kdpfd, 0)) == (char *) -1)
{
}
where maxfds is the maximum number of file descriptors that it's supposed to stock inside the polling device. Files are added to the interest set by :
struct pollfd pfd;
pfd.fd = fd;
pfd.events = POLLIN | POLLOUT | POLLERR | POLLHUP;
pfd.revents = 0;
if (write(kdpfd, &pfd, sizeof(pfd)) != sizeof(pfd)) {
...
}
and removed with :
struct pollfd pfd;
pfd.fd = fd;
pfd.events = POLLREMOVE;
pfd.revents = 0;
if (write(kdpfd, &pfd, sizeof(pfd)) != sizeof(pfd)) {
...
}
The core dispatching code looks like :
struct pollfd *pfds;
struct evpoll evp;
for (;;) {
evp.ep_timeout = STD_SCHED_TIMEOUT;
evp.ep_resoff = 0;
nfds = ioctl(kdpfd, EP_POLL, &evp);
pfds = (struct pollfd *) (map + evp.ep_resoff);
for (ii = 0; ii < nfds; ii++, pfds++) {
...
}
}
Basically the driver allocates two sets of pages that it uses as a double buffer to store files events. The field ep_resoff will tell where, inside the map, the result set resides so, while working on one set, the kernel can use the other one to store incoming events. There is no copy to userspace issues, events coming from the same file are collapsed into a single slot and the EP_POLL function will never do a linear scan of the interest set to perform a file->f_ops->poll(). To use the /dev/epoll interface You've to mknod such name with major=10 and minor=124 :
# mknod /dev/epoll c 10 124
You can download the patch here :
The /dev/poll patch from Provos-Lever
There's very few things to say about this, only that a virt_to_page() bug has been fixed to make the patch work. I fixed also a problem the patch has when it tries to resize the hash table by calling kmalloc() for a big chunk of memory that can't be satisfied. Now vmalloc() is used for hash table allocation. I modified a patch for 2.4.3 that I found at the CITI web site and this should be the port to 2.4.x of the original ( 2.2.x ) one used by Provos-Lever. You can download the patch here :
http://www.xmailserver.org/linux-patches/olddp_last.diff.gz
The RT signals one-sig-per-fd patch
This patch coded by Vitaly Luban implement RT signals collapsing and try to avoid SIGIO delivery that happens when the RT signals queue become full. You can download the patch here :
http://www.luban.org/GPL/gpl.html
The HTTP server
The HTTP server is very simple(tm) and is based on event polling + coroutines that make the server quite efficent. The coroutine library implementation used inside the server has been taken from :
http://www.goron.de/~froese/coro/
It's very small, simple and fast. The default stack size used by the server is 8192 and this, when trying to charge a lot of connections, may result in memory waste and vm trashing. A stack size of 4096 should be sufficent with this ( empty ) HTTP server implementation. Another issue is about the allocation method used by the coro library that uses mmap() for stack allocation. This, when the rate of accept()/close() become high may result in performance loss. I changed the library ( just one file coro.c ) to use malloc()/free() instead of mmap()/munmap(). Again, it's very simple ( the server ) and always emits the same HTTP response whose size can be programmed by a command line parameter. Other two command line options enable You to set the listening port and the fd set size. You can download the server here :
Old version:
http://www.xmailserver.org/linux-patches/dphttpd_last.tar.gz
The deadconn(tm) tool
If the server is simple this is even simpler and its purpose is to create "dead" connections to the server to simulate a realistic load where a bunch of slow links are connected. You can download deadconn here :
http://www.xmailserver.org/linux-patches/deadconn_last.c
The test
The test machine is a PIII 600MHz, 128 Mb RAM, eepro100 network card connected to a 100Mbps fast ethernet switch. The kernel is 2.4.6 over a RH 6.2 and the coroutine library version is 1.1.0-pre2. I used a dual PIII 1GHz, 256 Mb RAM and dual eepro100 as httperf machine, while a dual PIII 900 MHz, 256 Mb RAM and dual eepro100 has been used as deadconn(tm) machine. Since httperf when used with an high number of num-conns goes very quickly to fill the fds space ( modified to 8000 ) I used this command line :
--think-timeout 5 --timeout 5 --num-calls 2500 --num-conns 100 --hog --rate 100
This basically allocates 100 connections that will load the server under different values of dead connections. The other parameter I varied is the response size from 128, 512 and 1024. Another test, that has more respect of the nature of the internet sessions, is to have a burst of connections that are opened, make two HTTP requests and than are closed. This test is implemented with httperf by calling :
--think-timeout 5 --timeout 5 --num-calls 2 --num-conns 27000 --hog --rate 5000
Each of these numbers is the average of three runs. You can download httperf here :
http://www.hpl.hp.com/personal/David_Mosberger/httperf.html

The test show that the /dev/epoll is about 10-12% faster than the RT signals one-sig implementation and that either /dev/epoll and both RT signals implementation keeps flat over dead connections load. The RT-one-sig implementation is slight faster than the simple RT signal, but here only a couple of SIGIO occurred during the test.


Both the 512 and 1024 Content-Length test show that /dev/epoll, RT signals and RT one-sig behave almost is the same way ( the graph overlap ). This is due the ethernet saturation ( 100Mbps ) occurred during these tests.

This test shows that /dev/epoll, RT signals and RT one-sig implementation had a quite flat behaviour over dead connections load with /dev/epoll about 15% faster than RT one-sig and RT one-sig about 10-15% faster than the simple RT signals.
The need of a system call interface to the event retrival device driven the implementation of sys_epoll, that offsers the same level of scalability through a simpler interface for the developer. The new system call interface introduces three new system calls that maps to the corresponding user space calls :
int epoll_create(int maxfds);
int epoll_ctl(int epfd, int op, int fd, unsigned int events);
int epoll_wait(int epfd, struct pollfd *events, int maxevents, int timeout);
These functions are described in their manual pages :
epoll : PSTXTMAN
epoll_create : PS TXTMAN
epoll_ctl : PSTXT MAN
epoll_wait : PSTXT MAN
Patches that implement the system call interface are available here. A library to access the new ( 2.5.45 ) epoll is available here :
A simple pipe-based epoll performace tester :
User space libraries that supports epoll :
During the epoll test I quickly made a patch for thttpd :
Conclusion
These numbers show that the new /dev/epoll ( and sys_epoll ) improve the efficency of the server from a response rate point of view and from a CPU utilization point of view ( better value of CPU/load factor ). The response rate of the new /dev/epoll in completely independent from the number of connections while the standard poll() and the old /dev/poll seems to suffer the load. The standard deviation is also very low compared to poll() and old /dev/poll and this let me think that 1) there's more power to be extracted 2) the method has a predictable response over high loads. Both the RT signals and RT one-sig implementations behave pretty flat over dead connections load with the one-sig version that is about 10-12% faster than the simple RT signals version. RT singnals implementations ( even if the one-sig less ) seems to suffer the burst test that simulates the real internet load where a huge number of connections are alive. This because of the limit of the RT signals queue that, even with the one-sig patch applied, is going to become full during the test.
Links:
[1] The epoll scalability page at lse.
[2] David Weekly - /dev/epoll Page
References:
[1] W. Richard Stevens - "UNIX Network Programming, Volume I: Networking APIs: Sockets and XTI, 2nd edition"
Prentice Hall, 1998.
[2] W. Richard Stevens - "TCP/IP Illustrated, Volume 1: The Protocols"
Addison Wesley professional computing series, 1994.
[3] G. Banga and J. C. Mogul - "Scalable Kernel Performance for Internet Servers Under Realistic Load"
Proceedings of the USENIX Annual Technical Conference, June 1998.
[4] G. Banga. P. Druschel. J. C. Mogul - "Better Operating System Features for Faster Network Servers"
SIGMETRICS Workshop on Internet Server Performance, June 1998.
[5] G. Banga and P. Druschel - "Measuring the Capacity of a Web Server"
Proceedings of the USENIX Symposium on Internet Technologies and Systems, December 1997.
[6] Niels Provos and Charles Lever - "Scalable Network I/O in Linux"
http://www.citi.umich.edu/techreports/reports/citi-tr-00-4.pdf
[7] Dan Kegel - "The C10K problem"
http://www.kegel.com/c10k.html
[8] Richard Gooch - "IO Event Handling Under Linux"
http://www.atnf.csiro.au/~rgooch/linux/docs/io-events.html
[9] Abhishek Chandra and David Mosberger - "Scalability of Linux Event-Dispatch Mechanisms"
http://www.hpl.hp.com/techreports/2000/HPL-2000-174.html
[10] Niels Provos and Charles Lever - "Analyzing the Overload Behaviour of a Simple Web Server"
http://www.citi.umich.edu/techreports/reports/citi-tr-00-7.ps.gz
[11] D. Mosberger and T. Jin - "httperf -- A Tool for Measuring Web Server Performance"
SIGMETRICS Workshop on Internet Server Performance, June 1998.