
阿里云上云流程:注册账号、实名认证、领优惠券补贴和购买云服务器全解析,上云就上阿里云,首先你需要注册一个阿里云账号,之后账号必须完成实名认证才可以正常使用,然后免费领取上云补贴,最后在活动中心购买想要的云服务器、云数据库、云存储等产品。阿小云整理详细的阿里云上云流程:
步骤一:注册阿里云账号
注册阿里云账号只需要一个可以接收短信验证码的手机号就可以了,注册教程参考官方文档:https://help.aliyun.com/zh/account/step-1-register-an-alibaba-cloud-account
账号注册流程如下图:
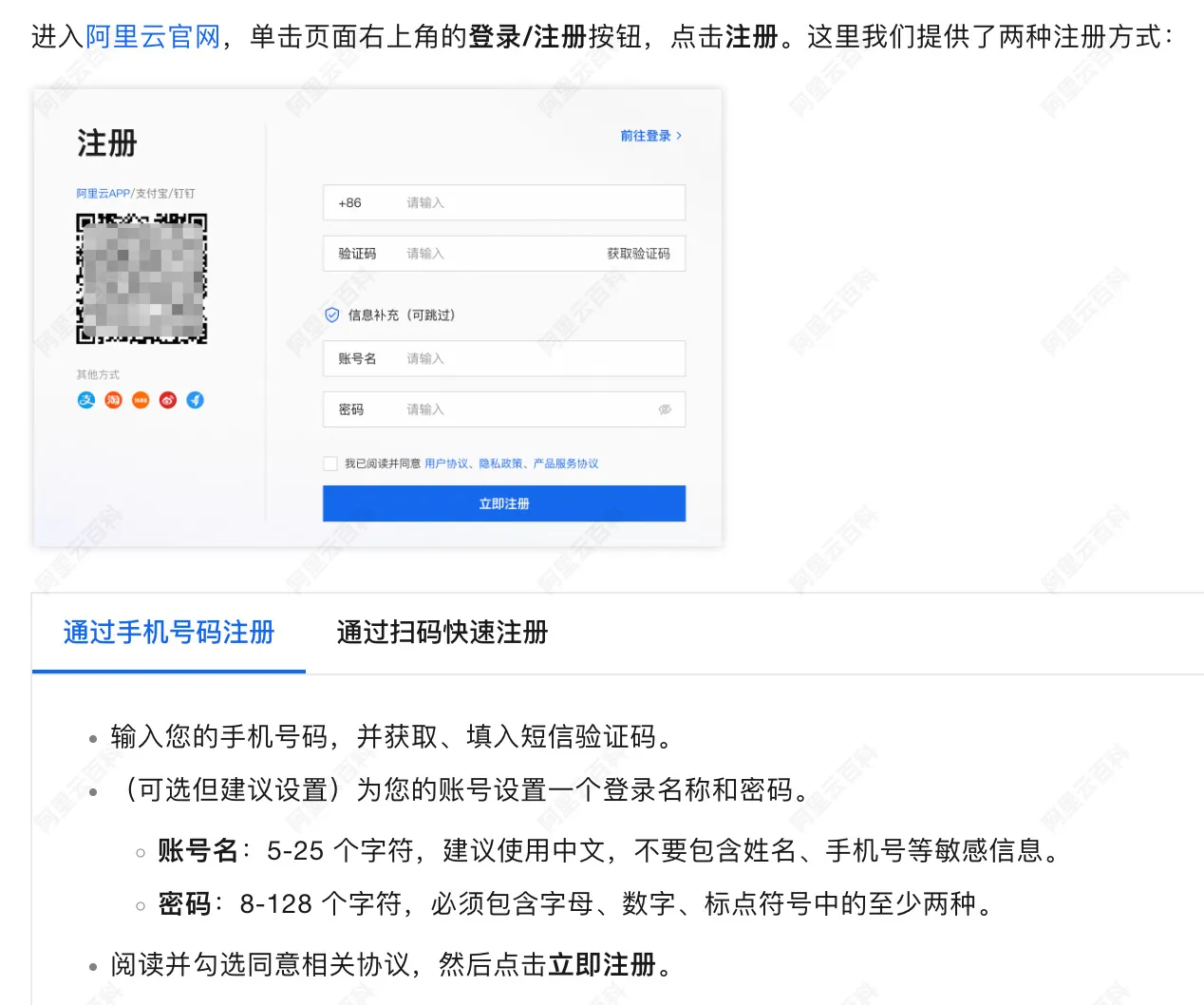
步骤二:实名认证
根据相关规定,账号必须完成实名认证才可以购买及使用云服务器、云数据库、云存储等产品,根据使用主体可以选择个人实名认证或者企业实名认证,一个支付宝就可以认证了,基本上秒通过的,实名认证教程如下:
- 个人实名认证:https://help.aliyun.com/zh/account/verify-your-identity-individual-account
- 企业实名认证:https://help.aliyun.com/zh/account/verify-your-identity-enterprise-account/
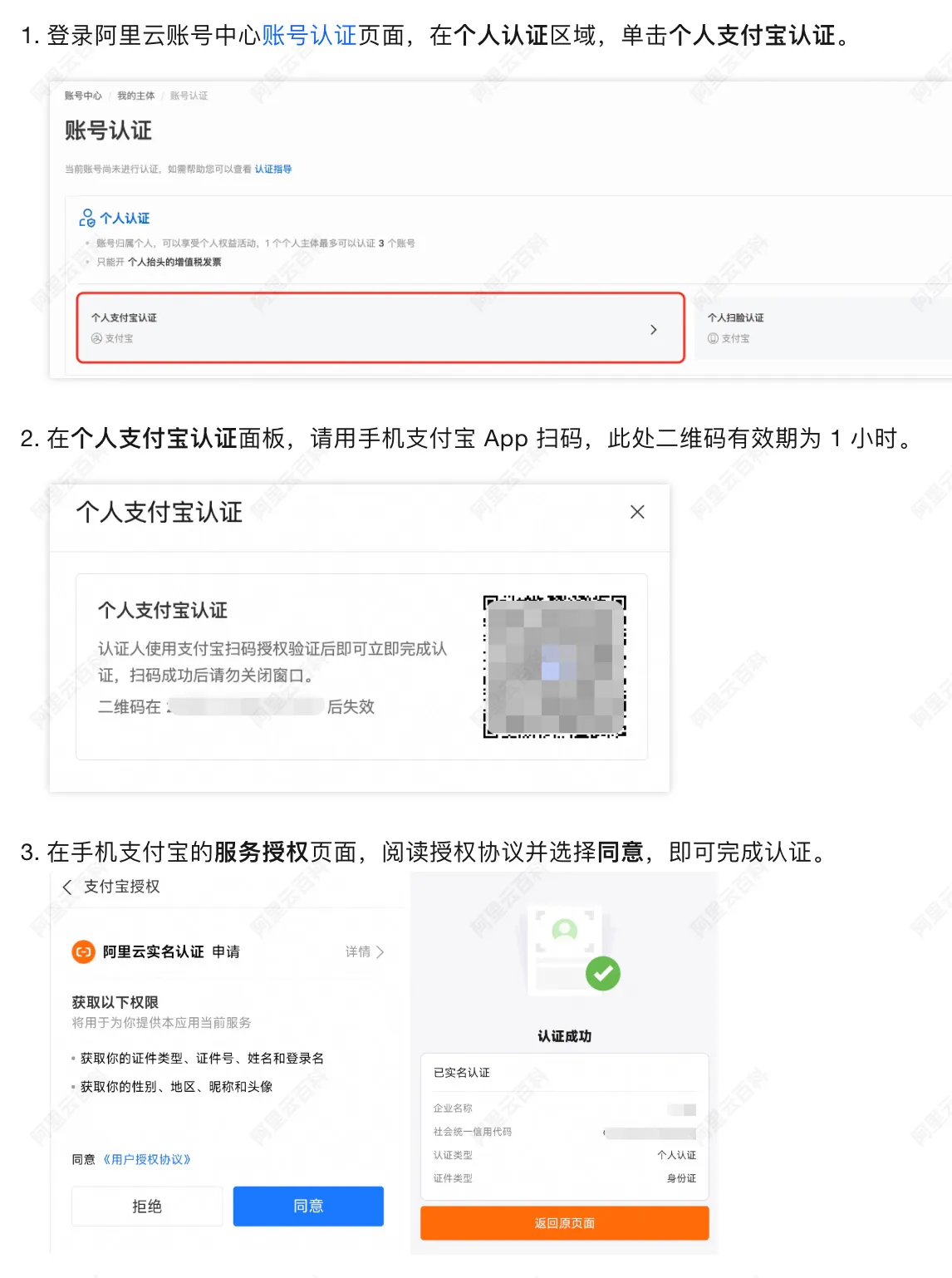
下图是以阿里云个人账号实名认证为例,如下图:
步骤三:免费领取上云补贴
阿里云用户类型分为个人用户、企业用户和学生用户,针对不同用户类型,阿里云均提供对应的上云补贴:
企业用户权益中心
企业用户:如果你是企业用户,请移步到这个活动,企业权益中心:https://www.aliyun.com/benefit/developer/company 如下图:

个人用户权益中心和活动中心
个人用户:如果是个人用户,可以在上面的活动切换到个人权益中心,也可以逛一逛阿里云的活动中心:https://www.aliyun.com/activity 如下图:

云工开物(阿里云高校用云计划)
学生用户:如果你是学生用户,可以移步到这个高校计划:https://university.aliyun.com/ 免费领取学生专属的300元无门槛代金券,如下图:

步骤四:购买云服务器等产品
领取到上云补贴优惠券后,可以去购买云服务器等产品了。目前可以领取的优惠券有阿里云折扣券和代金券,学生还可以另外领取一个300元无门槛代金券,然后去阿里云活动中心购买想要的云产品即可。
以上是阿小云整理的阿里云上云流程,新手无门槛教程,从阿里云账号注册、实名认证、领取上云补贴优惠券到购买全流程。

