

系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第九篇——《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》
一、引言:大模型的“内存焦虑”与量化技术的使命
大型语言模型(LLMs)在自然语言处理领域的应用日益广泛,但千亿参数规模的模型(如175B参数的OPT-175B、BLOOM-176B)面临严重的推理内存瓶颈。传统模型通常采用16位浮点(FP16)或32位浮点(FP32)存储参数,导致单模型内存占用动辄超过百GB,需依赖多GPU集群才能运行。
量化技术作为解决该问题的核心方案,通过将高比特精度参数映射到低比特(如8位整数Int8),可大幅降低内存占用并提升计算效率。然而,现有8位量化方法在处理超过6.7B参数的大模型时,普遍存在性能退化问题,其核心矛盾在于量化过程中无法平衡内存节省与精度保留。2022年发表的《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》一文,针对这一痛点提出了突破性解决方案,首次实现了千亿参数模型的无精度损失8位量化推理。
二、论文详细解读
2.1 核心挑战:为什么普通量化会让大模型“变笨”?
论文通过实证分析发现,大模型量化性能退化的关键诱因是涌现性异常值特征。当模型参数规模超过6.7B时, transformer的注意力投影层和前馈网络层中,会出现少量(约0.1%)但系统性的大幅值特征(幅值可达普通特征的20倍)。这些异常值具有高度规律性:集中在少数特征维度(最多7个),但覆盖75%的序列维度和所有网络层,且对模型的注意力权重计算和预测性能至关重要——移除这些异常值会导致top-1注意力softmax概率下降20%以上,验证困惑度提升600-1000%。传统量化方法(如逐张量absmax量化)采用全局统一的缩放因子,异常值会主导缩放过程,导致普通特征的量化精度被严重压缩,进而引发模型性能退化。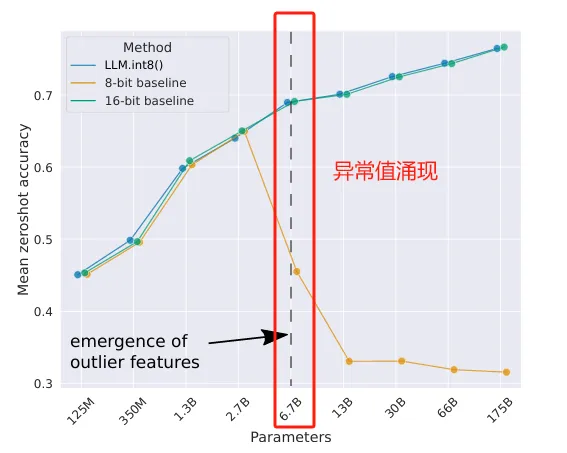
图1:OPT模型在WinoGrande、HellaSwag、PIQA和LAMBADA数据集上的零样本平均准确率。展示了16位基线模型、现有最精确的8位量化基线方法,以及本文提出的新型8位量化方法LLM.int8()。结果显示,当模型参数达到6.7B规模出现系统性异常值时,常规量化方法失效,而LLM.int8()仍能保持16位精度水平。
2.2 核心创新:LLM.int8()的混合精度量化方案
论文提出的LLM.int8()方法通过向量级量化与混合精度分解的双阶段策略,解决了异常值导致的量化精度问题:
- 向量级量化(Vector-wise Quantization):将矩阵乘法视为行向量与列向量的独立内积运算,为每个内积分配独立的归一化常数,而非全局统一缩放因子,从而提升普通特征的量化精度,可支持2.7B参数模型的无退化量化。
- 混合精度分解(Mixed-precision Decomposition):通过阈值α=6.0识别异常值特征维度,将占比0.1%的异常值特征分离出来,采用FP16精度进行矩阵乘法;其余99.9%的普通特征则采用Int8量化。该策略既保留了异常值的高精度计算,又维持了50%以上的内存节省(相比FP16),且额外内存开销仅0.1%。
整个流程为:先对FP16输入和权重进行异常值分解,再对普通特征执行向量级Int8量化与矩阵乘法,最后将Int8计算结果反归一化,并与异常值的FP16计算结果累加,输出FP16精度的最终结果。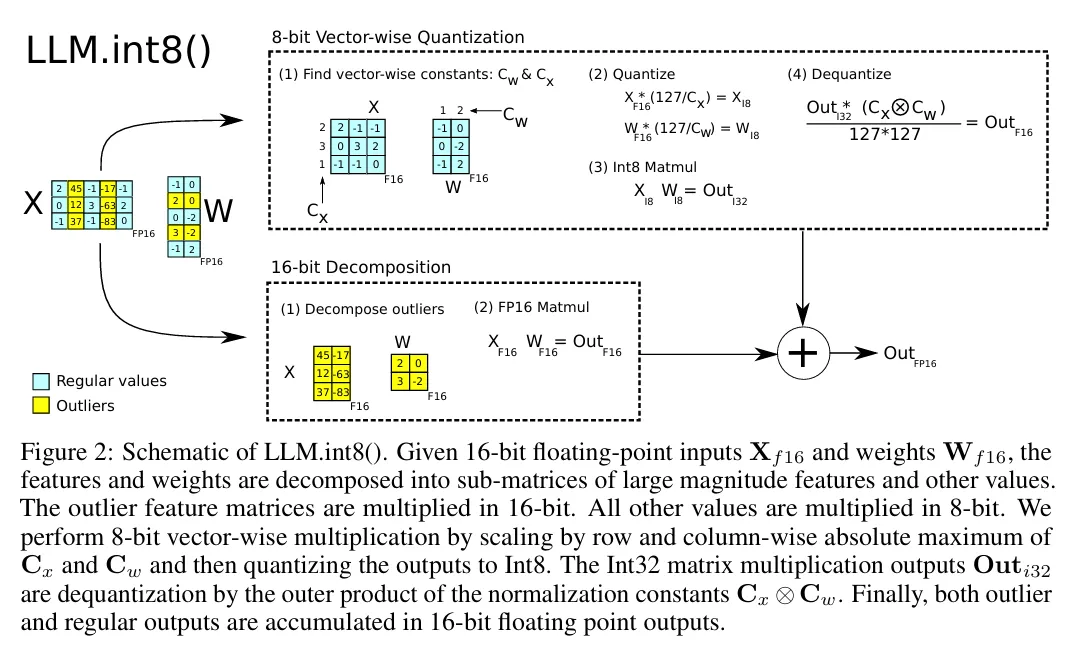
图2:LLM.int8()量化方法示意图。给定16位浮点型输入Xf16和权重Wf16,将特征与权重分解为大数值特征子矩阵及其他数值子矩阵:异常值特征矩阵采用16位精度执行乘法运算,其余所有数值均以8位精度计算。8位按向量乘法的实现流程为:通过Cx和Cw的行/列方向绝对最大值进行缩放,随后将输出量化为8位整型(Int8);8位整型矩阵乘法输出Outi32通过归一化常数Cx与Cw的外积完成反量化;最终将异常值输出与常规输出累加,得到16位浮点型最终结果。
2.3 实验验证:千亿参数模型的无退化量化奇迹
论文在125M到175B参数的多个模型(GPT-2、OPT、BLOOM等)上进行了验证,核心结果包括:
- 性能保持:在C4语料的语言建模任务中,LLM.int8()量化后的13B模型困惑度(12.45)与FP32基线完全一致,而传统Int8量化(absmax)的困惑度高达19.08;在WinoGrande、HellaSwag等零样本任务中,OPT-175B的量化模型准确率与FP16基线无差异,而传统8位量化模型性能退化至随机水平。
- 内存与效率:BLOOM-176B模型经LLM.int8()量化后,可在单台配备8张RTX 3090(24GB显存)的学术服务器上运行,而FP16版本需8张A100(40GB显存)才能支撑;对于175B参数模型,Int8矩阵乘法的推理速度比FP16快1.81倍,且端到端延迟接近FP16基线。
- 通用性:该方法适用于不同训练框架(Fairseq、OpenAI、TensorFlow-Mesh)和推理框架(Fairseq、Hugging Face Transformers),且对模型架构变体(旋转嵌入、残差缩放等)具有鲁棒性。
2.4 实际应用:大模型落地的“降本增效”神器
LLM.int8()的实际价值体现在大模型部署的全链条优化:
- 降低部署成本:通过将模型内存占用减半,减少了GPU硬件采购成本,例如学术机构无需依赖昂贵的A100集群,用消费级GPU即可开展千亿参数模型研究;云服务提供商可在相同GPU资源上部署更多模型实例,提升资源利用率。
- 加速原型开发:研究者可在本地GPU上快速加载大模型进行实验,无需等待集群资源,缩短迭代周期。
- 兼容参数高效微调:LLM.int8()可与LoRA等技术结合,在量化模型上进行任务特定微调,仅需训练少量适配器参数,即可进一步提升任务性能,且微调过程仍保持低内存占用。
2.5 局限与未来:量化技术的进一步探索
论文也指出了当前工作的局限:
- 仅支持Int8量化,未探索FP8等新型低比特浮点格式(受限于当前GPU硬件支持);
- 未覆盖注意力函数的Int8量化,仅针对前馈层和注意力投影层;
- 聚焦推理阶段,Int8训练仍面临性能退化问题,需更复杂的量化策略;
- 仅验证了175B参数模型,更大规模模型可能出现新的涌现特征,需进一步适配。
未来方向包括:FP8量化适配、注意力机制的低比特优化、Int8训练技术研发,以及更大规模模型的量化探索。
三、总结:量化技术重塑大模型的可及性
LLM.int8()通过对transformer模型中涌现性异常值特征的深刻洞察,提出了向量级量化与混合精度分解的创新组合,首次实现了千亿参数规模大模型的无性能退化Int8量化。该方法不仅解决了长期以来低比特量化与模型精度的矛盾,更将千亿参数模型的部署门槛从企业级GPU集群降至消费级GPU,极大提升了大模型的可及性。其核心贡献在于揭示了大模型量化性能退化的本质原因(异常值主导的缩放失真),并提供了高效且通用的解决方案,为后续低比特量化技术的发展奠定了理论与实践基础。

