

系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第八篇——《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
一、研究背景:大模型的“甜蜜烦恼”——规模与落地的核心矛盾
近年来,迁移学习在自然语言处理(NLP)领域迎来爆发式普及,以BERT为代表的大规模预训练语言模型通过“预训练-微调”范式,在情感分类、问答系统、文本推理等众多下游任务中实现了性能飞跃,成为现代NLP技术栈的核心基础。然而,这些模型的“大尺寸”特性逐渐显现出不可忽视的现实困境:
一方面,模型参数规模呈指数级增长,从BERT-base的1.1亿参数到后续MegatronLM等超大规模模型的千亿级参数,带来了惊人的计算与能源消耗。正如Schwartz等人[2019]在《Green AI》中指出的,大模型训练过程的碳排放量相当于数辆汽车的终身碳足迹;Strubell等人[2019]的研究也显示,训练一个大型NLP模型的能源消耗甚至超过普通家庭数十年的用电量,环境代价与可持续性问题日益突出。
另一方面,大模型的部署门槛极高。其庞大的内存占用(BERT-base推理需占用数十GB显存)和高延迟(CPU端单批次推理耗时数百秒),使其难以适配边缘设备(如智能手机、智能穿戴设备、工业传感器)的实时计算场景。而边缘设备的离线处理、低延迟响应、数据隐私保护等需求,恰恰是AI技术从“云端”走向“终端”的关键突破口——用户需要无需联网的离线翻译、低延迟的语音助手、本地处理敏感文本的分析工具,这些场景都对模型的轻量化提出了刚性要求。
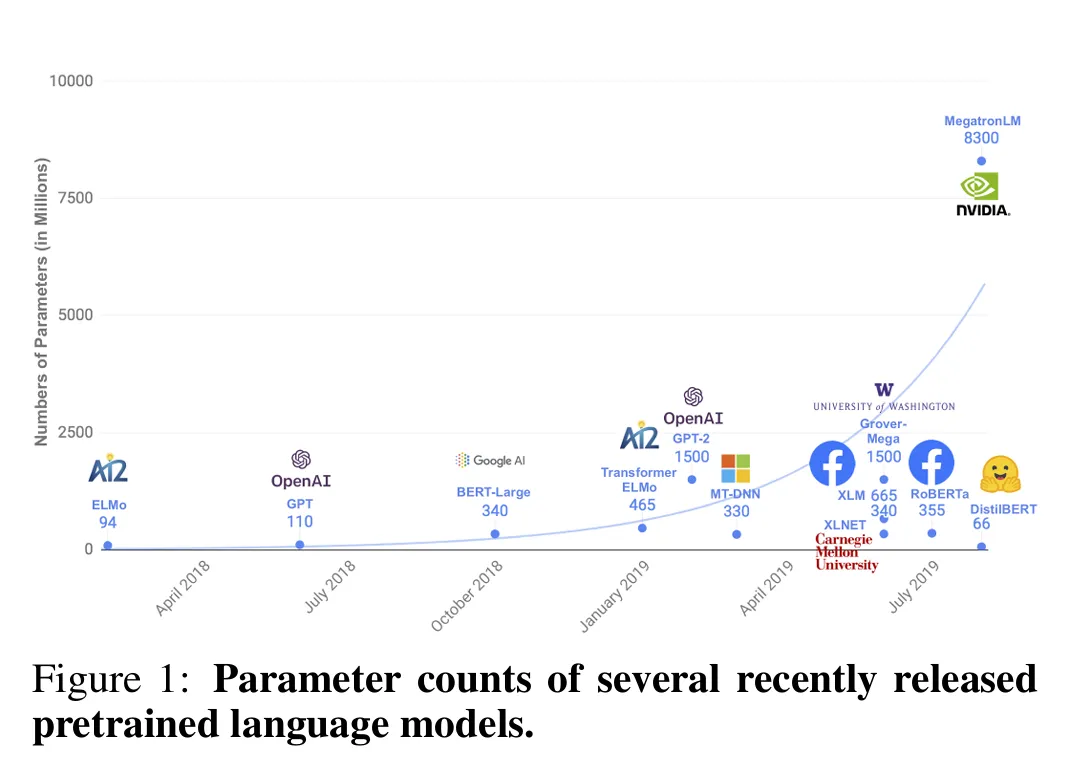
核心痛点已明确:现有大模型的“规模-效率”失衡,缺乏一种既能保留通用语言理解能力,又能适配低资源环境部署的通用解决方案。 DistilBERT的诞生,正是为了破解这一矛盾。
二、论文深度解读:知识蒸馏驱动的通用模型轻量化方案
1. 核心方案:预训练蒸馏+三重损失+轻量化架构设计
DistilBERT的核心创新在于将知识蒸馏技术从“任务特定阶段”迁移至“预训练阶段”,构建通用型轻量化模型,而非针对单个下游任务定制压缩模型。其技术路径可拆解为“蒸馏框架设计”“模型架构优化”“训练策略创新”三大模块,形成闭环优化。
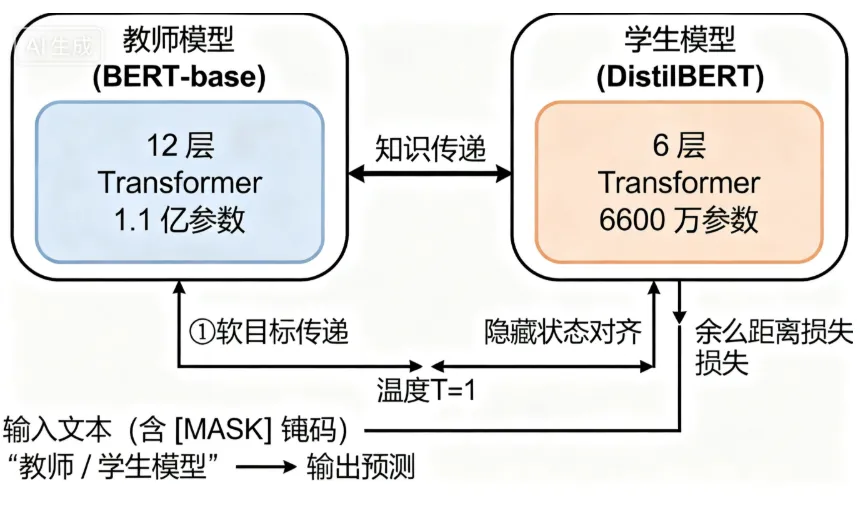
1.1 知识蒸馏的本质与三重损失函数
知识蒸馏(Knowledge Distillation)的核心逻辑是:让参数紧凑的“学生模型”(DistilBERT)通过学习参数庞大的“教师模型”(BERT-base)的“知识”,实现性能逼近。这里的“知识”不仅包括教师模型的最终预测结果(硬目标),更包括其预测分布中蕴含的泛化信息(软目标)。为实现高效知识迁移,论文设计了三重损失函数(Triple Loss),各组件各司其职且相互补充:
蒸馏损失($L_{ce}$:Cross-Entropy Loss)
核心目标是让学生模型模仿教师模型的软目标概率分布。传统分类任务中,模型输出的硬目标(one-hot向量)仅包含正确标签的信息,而软目标(通过温度参数T平滑后的概率分布)能反映教师模型对不同类别(或token)的置信度差异,蕴含更丰富的泛化知识。
具体计算过程为:- 对教师模型和学生模型的原始输出(logits)分别应用带温度T的软max函数,得到软目标概率:$p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)}$,其中$z_i$为模型对类别i的原始得分,T为温度参数(论文中T=1)。
- 蒸馏损失为学生软目标与教师软目标的交叉熵:$L_{ce} = \sum_i t_i \cdot \log(s_i)$,其中$t_i$为教师软目标概率,$s_i$为学生软目标概率。
- 该损失确保学生模型不仅“学会答案”,更“学会教师的思考方式”。
掩码语言建模损失($L_{mlm}$:Masked Language Modeling Loss)
继承BERT的核心预训练目标,通过随机掩码输入文本中的部分token(如15%的token被掩码),让模型预测被掩码的原始token。这一损失确保学生模型不会因模仿教师而丢失基础语言理解能力(如词汇语义、语法结构),为通用语言任务提供底层支撑。
论文中,DistilBERT采用了动态掩码策略(与RoBERTa一致),即每个训练批次对文本重新生成掩码,而非固定掩码模式,提升了预训练数据的多样性。余弦距离损失($L_{cos}$:Cosine-Distance Loss)
目标是对齐学生模型与教师模型的隐藏状态向量空间。具体而言,计算教师模型和学生模型对应层的隐藏状态向量的余弦相似度,最小化二者的距离:$L_{cos} = 1 - \cos(h_t, h_s)$,其中$h_t$为教师隐藏状态,$h_s$为学生隐藏状态。
该损失的核心作用是确保学生模型的特征表示空间与教师模型一致——即使模型结构简化,其提取的语言特征仍能保留教师模型的语义层次,避免因结构压缩导致特征失真。
最终的训练目标为三重损失的加权和:$L{total} = \alpha L{ce} + \beta L{mlm} + \gamma L{cos}$(论文中未明确给出权重,但通过消融实验验证了三者的必要性)。
1.2 轻量化架构设计:聚焦“高效压缩”而非“盲目缩减”
DistilBERT并未对BERT的核心Transformer架构进行颠覆性修改,而是基于“计算效率优先级”进行针对性优化,确保压缩后仍能保留Transformer的并行计算优势:
| 优化方向 | 具体措施 | 设计依据 |
|---|---|---|
| 移除冗余组件 | 删除token-type嵌入和pooler层 | 1. token-type嵌入用于区分句子对(如MNLI任务中的前提句与假设句),但DistilBERT预训练阶段移除了下一句预测(NSP)任务,该嵌入失去作用; 2. pooler层用于生成句子级别的固定维度表示(适用于分类任务),但DistilBERT作为通用模型,微调时可通过简单的均值池化或全连接层替代,移除后可减少参数冗余。 |
| 精简网络层数 | 将Transformer层数从12层减半至6层 | 论文通过实验验证:在固定参数预算下,Transformer层数对计算效率的影响远大于隐藏层维度(hidden size)——层数减少可直接降低推理时的串行计算步骤,而隐藏层维度缩减会导致特征表达能力大幅下降,且现代线性代数框架(如CUDA)对隐藏层维度的优化更充分,缩减带来的效率提升有限。 |
| 保持核心维度 | 隐藏层维度(768)、注意力头数(12)与BERT-base一致 | 确保学生模型与教师模型的特征维度兼容,为隐藏状态对齐(余弦距离损失)和层采样初始化提供基础。 |
1.3 训练策略:继承教师知识,加速收敛
为解决小模型训练易陷入局部最优的问题,DistilBERT采用了“教师模型参数初始化”策略:利用教师模型与学生模型的架构兼容性(层数减半),从教师模型中每两层抽取一层的参数作为学生模型对应层的初始参数(如教师第2层参数作为学生第1层,教师第4层作为学生第2层,以此类推)。
这种初始化方式的核心优势在于:学生模型无需从零开始学习语言知识,而是直接继承教师模型预训练后的“先验知识”,既能加速训练收敛(减少约30%的训练迭代次数),又能避免随机初始化导致的性能波动。
训练细节补充:
- 训练语料:与BERT-base完全一致,即英文维基百科(约25亿词)+多伦多图书语料库(约8亿词),确保预训练数据的一致性对比;
- 训练配置:使用8台16GB V100 GPU,通过梯度累积将批次大小扩大至4K(单GPU批次大小为512,8台GPU×512=4096),动态掩码,训练时长约90小时;
- 对比基准:RoBERTa(BERT的优化版本)需在1024台32GB V100 GPU上训练1天,DistilBERT的训练硬件成本仅为RoBERTa的约1/300,充分体现了“cheaper”的优势。
2. 实验结果:全方位验证“轻量化不减能”
论文从通用语言理解、下游任务适配、速度与部署、 ablation验证四个维度展开实验,全面验证DistilBERT的性能与效率优势。
2.1 通用语言理解:GLUE基准测试
GLUE基准包含9个不同类型的NLP任务(涵盖句子级分类、文本相似度、问答推理等),是评估通用语言模型能力的核心标准。实验采用“单任务微调”模式(不使用集成模型或多任务微调),确保结果的客观性。
核心结论:
- 性能保留率:DistilBERT的GLUE宏平均得分为77.0,相较于BERT-base的79.5,保留了97%的语言理解能力,而参数规模从1.1亿减少至6600万,压缩比达40%;
- 任务适配性:在所有9个任务中,DistilBERT均优于ELMo基线(最高在STS-B任务上提升19个准确率点),其中在SST-2(情感分类)、MRPC(句子对匹配)等任务上与BERT-base差距不足2个百分点,仅在RTE(文本推理)、WNLI(代词指代消解)等对推理能力要求较高的任务上差距略大(约5-10个百分点);
- 稳定性:实验报告5次不同随机种子的中位数结果,DistilBERT的标准差与BERT-base接近,说明其训练过程稳定,未因模型压缩导致泛化能力下降。
2.2 下游任务专项测试:IMDb与SQuAD
为验证DistilBERT在实际应用场景中的表现,论文选择了两个典型下游任务:
IMDb情感分类(二分类任务,测试集含25000条评论):
- DistilBERT测试准确率为92.82%,仅落后BERT-base(93.46%)0.64个百分点,证明其在单句子分类任务上的性能逼近大模型;
SQuAD 1.1问答任务(抽取式问答,含10万+问题):
- 基础版本:EM(精确匹配)=77.7,F1=85.8,与BERT-base(81.2/88.5)差距分别为3.5和2.7;
- 二次蒸馏版本(DistilBERT (D)):在微调阶段以BERT-base微调后的模型为教师,新增蒸馏损失,EM提升至79.1,F1提升至86.9,差距进一步缩小至2.1和1.6。
二次蒸馏的提升验证了“预训练蒸馏+微调蒸馏”的叠加效应——微调阶段的教师模型已适配具体任务,其知识更具针对性,能进一步弥补学生模型的性能差距。
2.3 速度与部署测试:边缘设备适配性
论文重点测试了DistilBERT在受限环境下的表现,为边缘部署提供数据支撑:
| 测试场景 | 测试条件 | 结果对比 |
|---|---|---|
| CPU推理速度 | Intel Xeon E5-2690 v3 @2.9GHz,单批次(batch size=1),STS-B任务 | DistilBERT推理时间410秒,BERT-base为668秒,速度提升60%;ELMo(1.8亿参数)为895秒,DistilBERT在参数更少的情况下速度远超ELMo。 |
| 移动端推理速度 | iPhone 7 Plus,排除分词步骤,问答任务 | DistilBERT平均推理时间比BERT-base快71%,模型体积仅207MB(BERT-base约410MB),支持本地存储与离线运行。 |
关键补充:论文提到可通过量化技术(如INT8量化)进一步压缩模型体积,预计可将207MB缩减至50MB以下,完全满足智能穿戴设备等内存受限场景的需求。
2.4 Ablation研究:拆解核心组件的贡献
为明确三重损失函数与初始化策略的必要性,论文进行了控制变量法实验(以GLUE宏得分为指标,基准分为77.0):
| 消融方案 | 性能变化(Δ) | 核心分析 |
|---|---|---|
| 移除余弦距离损失($L_{cos}$) | -1.46(得分75.54) | 余弦距离损失确保了学生与教师的特征空间对齐,移除后特征表达出现偏差,导致下游任务性能下降,但影响相对有限,说明基础语言能力仍由$L{mlm}$和$L{ce}$保障。 |
| 移除蒸馏损失($L_{ce}$) | -2.96(得分74.04) | 蒸馏损失是传递教师泛化知识的核心,移除后学生模型仅依赖$L_{mlm}$学习基础语言知识,缺乏教师的“经验指导”,泛化能力大幅下降,证明蒸馏是性能保留的关键。 |
| 移除掩码语言建模损失($L_{mlm}$) | -0.31(得分76.69) | 影响最小,说明教师模型的软目标中已蕴含部分基础语言知识,学生模型通过模仿教师即可部分掌握,但$L_{mlm}$仍能提供补充信号,避免基础能力缺失。 |
| 随机初始化替代教师层采样 | -3.69(得分73.31) | 最大性能下降,证明教师模型的初始化参数为学生模型提供了关键的“知识起点”,随机初始化导致学生模型需重新学习语言规律,不仅训练收敛慢,且易陷入局部最优。 |
3. 相关工作对比:DistilBERT的核心差异化优势
在DistilBERT之前,NLP领域已有多种模型压缩方案,但DistilBERT通过“通用预训练蒸馏”的定位,形成了独特优势:
| 压缩方案类型 | 代表工作 | 核心特点 | DistilBERT的差异化优势 |
|---|---|---|---|
| 任务特定蒸馏 | Tang et al. [2019]、Chatterjee [2019] | 1. 针对单个下游任务(如分类、问答); 2. 流程为“大模型微调→蒸馏为小模型”; 3. 小模型仅适用于特定任务,灵活性差。 |
1. 预训练阶段蒸馏,得到通用型小模型; 2. 可直接用于所有下游任务微调,无需重复蒸馏; 3. 兼顾性能与灵活性,适配多样化场景。 |
| 单一目标预训练压缩 | Turc et al. [2019] | 1. 仅使用掩码语言建模损失训练小模型; 2. 未利用教师模型的知识,性能依赖数据量与训练策略。 |
1. 融合三重损失,充分吸收教师模型的泛化知识; 2. 性能更优(GLUE得分77.0 vs Turc等人的约75.0)。 |
| 多教师蒸馏 | Yang et al. [2019] | 1. 利用多个教师模型的集成知识; 2. 适用于特定任务(如问答系统),训练复杂度高。 |
1. 单教师模型蒸馏,训练成本低; 2. 通用型模型,无需针对任务设计教师集成策略。 |
| 剪枝与量化 | Michel et al. [2019]、Gupta et al. [2015] | 1. 剪枝:移除冗余参数(如注意力头、神经元); 2. 量化:降低参数数值精度(如FP32→INT8); 3. 属于“后处理压缩”,需在训练后额外优化。 |
1. 属于“训练时压缩”,通过架构设计与蒸馏直接得到轻量化模型; 2. 与剪枝、量化正交,可结合使用(如DistilBERT+量化,压缩比可达80%以上)。 |
4. 应用场景与产业价值:解锁边缘AI的无限可能
DistilBERT的核心价值在于打破了“大模型=高性能”与“小模型=低延迟”的二元对立,为AI技术在边缘设备的落地提供了“高性能+高效率”的解决方案。其典型应用场景包括:
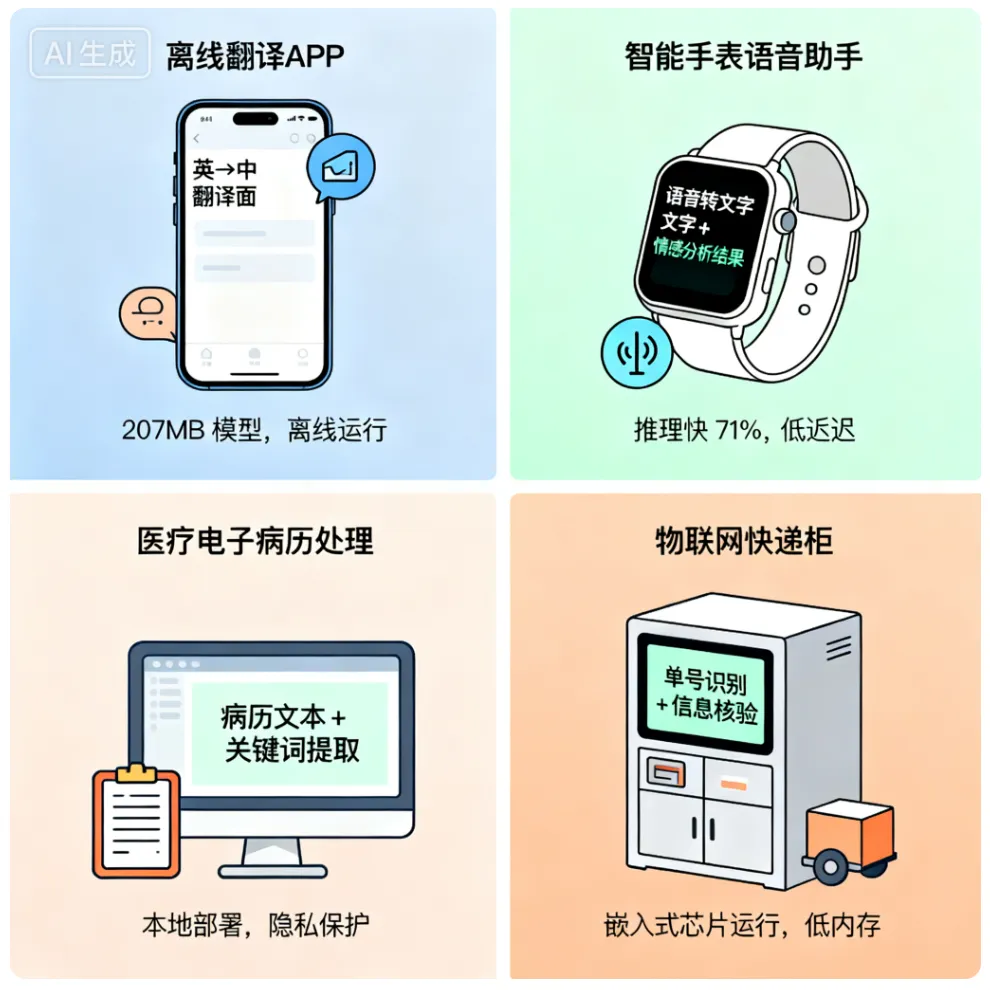
4.1 离线NLP应用
- 场景需求:无网络环境下的文本处理(如野外作业的文档分析、无信号区域的翻译工具);
- 适配优势:207MB的模型体积可轻松存储于手机、平板等设备,离线推理速度满足实时响应(移动端单句处理耗时<100ms);
- 案例:离线翻译APP(如基于DistilBERT的英中翻译工具)、本地文本纠错软件。
4.2 低延迟实时交互系统
- 场景需求:语音助手、智能客服等需要快速响应的交互场景(延迟要求<500ms);
- 适配优势:CPU推理速度提升60%,无需依赖高端GPU,普通服务器即可支撑高并发请求;
- 案例:智能手表的语音转文字实时分析、电商平台的实时评论情感识别。
4.3 隐私保护型NLP工具
- 场景需求:医疗、金融等敏感领域的文本分析(如电子病历处理、客户隐私信息提取),数据不可上传云端;
- 适配优势:本地部署无需传输数据,避免隐私泄露,同时轻量化模型降低了本地硬件的计算压力;
- 案例:医院本地电子病历关键词提取系统、银行客户信息脱敏工具。
4.4 资源受限设备部署
- 场景需求:智能摄像头的文本识别(如车牌识别、快递单号读取)、物联网设备的简单文本处理;
- 适配优势:模型体积小、内存占用低(推理时内存占用<1GB),可运行于嵌入式芯片(如NVIDIA Jetson Nano);
- 案例:智能快递柜的单号自动识别、工业传感器的文本日志分析。
三、总结与未来展望
1. 核心贡献回顾
DistilBERT通过“预训练阶段知识蒸馏+三重损失函数+轻量化架构设计”的创新组合,成功实现了BERT模型的高效压缩:
- 性能层面:保留97%的通用语言理解能力,在下游任务中逼近BERT-base;
- 效率层面:参数减少40%,推理速度提升60%,训练成本降低数百倍;
- 落地层面:首次实现通用预训练模型的边缘部署,解锁了NLP技术的多样化应用场景。
其核心启示在于:模型压缩的关键并非“盲目缩减参数”,而是“高效传递知识”——通过蒸馏技术让小模型继承大模型的泛化能力,同时优化架构以匹配计算效率需求,才能实现“轻量化不减能”。
2. 局限性与未来方向
2.1 现存局限性
- 复杂推理任务性能差距:在需要深层语义推理的任务(如RTE、WNLI)上,与BERT-base仍有5-10个百分点的差距,说明蒸馏技术在传递复杂推理知识方面仍有提升空间;
- 单语言局限:仅支持英文,缺乏多语言版本,难以满足全球化部署需求;
- 损失函数权重未优化:论文未系统探索三重损失的最优权重组合,可能存在性能提升潜力。
2.2 未来研究方向
- 多语言DistilBERT:基于多语言BERT(mBERT)进行蒸馏,开发支持数十种语言的轻量化模型,适配跨境应用场景;
- 混合压缩技术:结合剪枝、量化、蒸馏,进一步提升压缩比(如参数减少80%仍保留95%性能);
- 任务自适应蒸馏:在预训练蒸馏的基础上,针对特定高价值任务(如医疗问答、法律文本分析)增加微调阶段的二次蒸馏,进一步缩小性能差距;
- 动态蒸馏框架:设计自适应温度参数T和损失权重,根据不同任务自动调整蒸馏策略,提升模型的通用性。
DistilBERT的出现,不仅为大模型压缩提供了可复用的技术范式,更推动了NLP技术从“实验室走向产业”的进程。在AI模型日益追求“高效、绿色、可落地”的今天,DistilBERT的设计思路将持续为后续轻量化模型的研发提供重要参考。



