
一、本文介绍
本文记录的是利用单头自注意力SHSA改进RT-DETR检测模型,详细说明了优化原因,注意事项等。传统的自注意力机制虽能提升性能,但计算量大,内存访问成本高,而SHSA==从根本上避免了多注意力头机制带来的计算冗余。并且改进后的模型在相同计算预算下,能够堆叠更多宽度更大的块,从而提高性能。==
专栏目录:RT-DETR改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改进
专栏地址:RT-DETR改进专栏——以发表论文的角度,快速准确的找到有效涨点的创新点!
二、Single-Head Self-Attention介绍
2.1 出发点
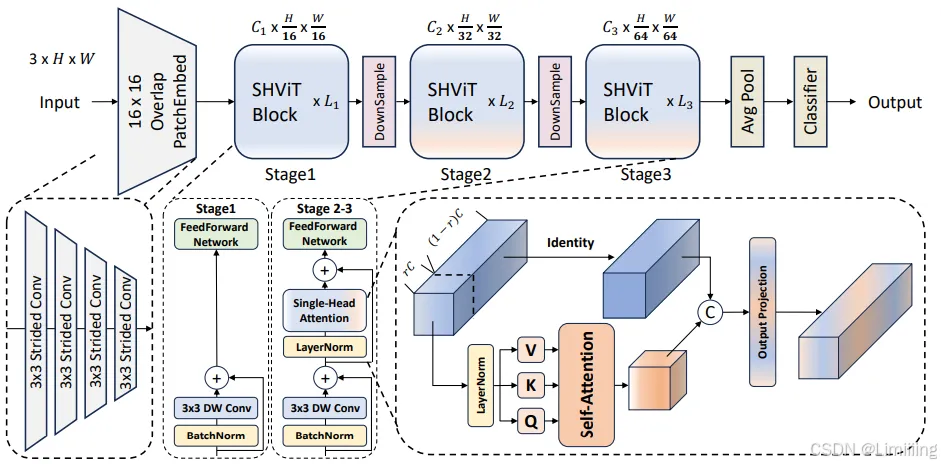
- 宏观设计层面:传统的高效模型大多采用$4×4$的patchify stem和4阶段配置,存在空间冗余,导致早期阶段速度瓶颈且内存访问成本高。研究发现采用更大步长的$16×16$patchify stem和3阶段设计可减少空间冗余,降低内存访问成本,提高性能。
- 微观设计层面:多注意力头机制(MHSA)在计算和应用注意力映射时虽能提升性能,但存在冗余。尤其在早期阶段部分头类似卷积操作,后期阶段头之间存在大量冗余,且多数现有方法处理头冗余需先训练完整网络再修剪,计算资源和内存消耗大。
2.2 原理
- 基于上述宏观和微观设计的分析结果,提出
Single - Head Self - Attention(SHSA)模块。它仅在部分输入通道($C_{p}=rC$)上应用单头注意力层进行空间特征聚合,其余通道保持不变,默认$r = 1/4.6$。
2.3 结构
2.3.1 输入通道处理
将输入$X$按通道分为两部分$X{att}$和$X{res}$,其中$X{att}$包含$C{p}$个通道,$X{res}$包含$C - C{p}$个通道。
2.3.2 注意力计算
对$X{att}$应用注意力机制,计算$\tilde{X}{att}=Attention(X{att}W^{Q},X{att}W^{K},X{att}W^{V})$,其中$Attention(Q,K,V)=Softmax(QK^{\top}/\sqrt{d{qk}})V$,$d_{qk}$默认值为16。
2.3.3 输出拼接与投影
将$\tilde{X}{att}$和$X{res}$拼接得到$SHSA(X)=Concat(\tilde{X}{att},X{res})W^{O}$,最终投影应用于所有通道,确保注意力特征有效传播到剩余通道。
- 优势
- 减少冗余:从根本上避免了多注意力头机制带来的计算冗余。
- 降低内存访问成本:仅处理部分通道,减少了内存访问成本。
- 提高性能:在相同计算预算下,能够堆叠更多宽度更大的块,从而提高性能。
- 简化训练和推理过程:相比现有处理头冗余的方法,无需先训练完整网络再修剪,训练和推理过程更加高效。
论文:https://arxiv.org/pdf/2401.16456
源码:https://github.com/ysj9909/SHViT
三、实现代码及RT-DETR修改步骤
模块完整介绍、个人总结、实现代码、模块改进、二次创新以及各模型添加步骤参考如下地址:










