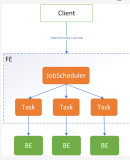
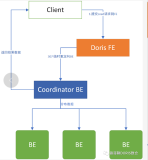
在 GreatSQL 中,并行 Load Data 确实可以显著加快数据导入速度。以下是关于这一功能的详细介绍:
一、并行 Load Data 的优势
- 提高效率
- 通过并行处理数据导入任务,可以充分利用服务器的多核处理器资源,大大缩短数据导入所需的时间。例如,在导入大量数据时,传统的单线程导入可能需要数小时甚至更长时间,而并行 Load Data 可以将这个时间大幅缩短,提高工作效率。
- 多个线程同时工作,能够更快地读取数据文件、解析数据并将其插入到数据库中,从而加快整个导入过程。
- 适应大数据量
- 随着数据量的不断增长,传统的数据导入方法可能会遇到性能瓶颈。并行 Load Data 能够更好地应对大数据量的导入需求,确保在处理大规模数据集时依然能够保持高效的导入速度。
- 对于企业级应用和数据仓库等场景,能够快速导入大量数据对于及时进行数据分析和决策至关重要。
二、实现原理
- 多线程处理
- GreatSQL 的并行 Load Data 功能利用多线程技术,将数据导入任务拆分成多个子任务,每个子任务由一个独立的线程负责执行。这些线程可以同时读取数据文件的不同部分,并行地进行数据解析和插入操作。
- 例如,假设有一个包含数百万条记录的 CSV 文件需要导入到数据库中。并行 Load Data 可以启动多个线程,每个线程负责读取和处理一部分数据,然后将其插入到数据库表中。这样可以大大提高数据导入的速度,减少整体导入时间。
- 数据分区
- 为了实现并行处理,数据通常需要进行分区。GreatSQL 可以根据特定的规则将数据文件划分为多个分区,每个分区由一个线程负责处理。这样可以确保各个线程之间的工作负载相对均衡,避免出现某些线程负载过重而其他线程空闲的情况。
- 数据分区的方式可以根据数据的特点和导入需求进行选择,例如可以按照数据的范围、哈希值或其他规则进行分区。
三、使用方法
- 启用并行导入
- 在使用 GreatSQL 进行数据导入时,可以通过特定的参数或命令来启用并行 Load Data 功能。具体的方法可能因版本和使用场景而有所不同,但通常可以在导入命令中指定并行度参数,以控制同时执行的线程数量。
- 例如,可以使用以下命令来启用并行导入:
LOAD DATA INFILE 'data.csv' INTO TABLE mytable CHARACTER SET utf8mb4 FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' PARALLEL n;
- 其中,
PARALLEL n表示启用并行导入,n是并行度,即同时执行的线程数量。可以根据服务器的硬件资源和数据量大小来调整并行度的值。
- 优化导入性能
- 为了获得最佳的导入性能,还可以结合其他优化措施。例如,可以调整数据库的缓冲池大小、优化表结构、关闭不必要的索引等,以减少导入过程中的磁盘 I/O 和内存占用。
- 此外,还可以对数据文件进行预处理,例如去除不必要的字段、压缩数据等,以提高导入速度和减少存储空间占用。
总之,GreatSQL 的并行 Load Data 功能为加快数据导入速度提供了一种有效的解决方案。通过合理地使用并行导入和优化数据库配置,可以大大提高数据导入的效率,满足企业在大数据时代对快速数据处理的需求。